
{kind=link}
Crystal
Collection
2 items
•
Updated
We present CrystalChat, an instruction following model finetuned from LLM360/Crystal.
CrystalChat pushes the Llama 2 frontier for models excelling at both langauge and coding tasks. CrystalChat is part of LLM360's Pebble model series.
| Model | Trained Tokens | Avg. of Avg. | Language Avg. | Coding Avg. |
|---|---|---|---|---|
| CrystalChat 7B | 1.275T | 44.96 | 53.29 | 36.62 |
| Mistral-7B-Instruct-v0.1 | - | 44.34 | 54.86 | 30.62 |
| CodeLlama-7b-Instruct | 2.5T | 40.91 | 45.29 | 36.52 |
| Llama-2-7b-Chat | 2T | 34.11 | 52.86 | 15.35 |
| AmberChat 7B | 1.25T | - | 44.76 | - |
| Model | Trained Tokens | ARC | HellaSwag | MMLU (5-shot) | GSM8K | Winogrande(5-shot) | TruthfulQA | HumanEval (pass@1) | MBPP (pass@1) |
|---|---|---|---|---|---|---|---|---|---|
| CrystalChat 7B | 1.275T | 51.71 | 76.12 | 53.22 | 28.05 | 70.64 | 47.29 | 34.12 | 39.11 |
| Mistral-7B-Instruct-v0.1 | - | 58.05 | 75.71 | 55.56 | 32.00 | 74.27 | 55.90 | 29.27 | 31.96 |
| CodeLlama-7b-Instruct | 2.5T | 43.35 | 66.14 | 42.75 | 15.92 | 64.33 | 39.23 | 34.12 | 38.91 |
| Llama-2-7b-Chat | 2T | 53.07 | 78.39 | 48.42 | 18.88 | 73.09 | 45.30 | 13.26 | 17.43 |
| AmberChat 7B | 1.25T | 42.83 | 74.03 | 38.88 | 5.31 | 66.77 | 40.72 | - | - |
| Combined Language and Coding Ability |
|---|
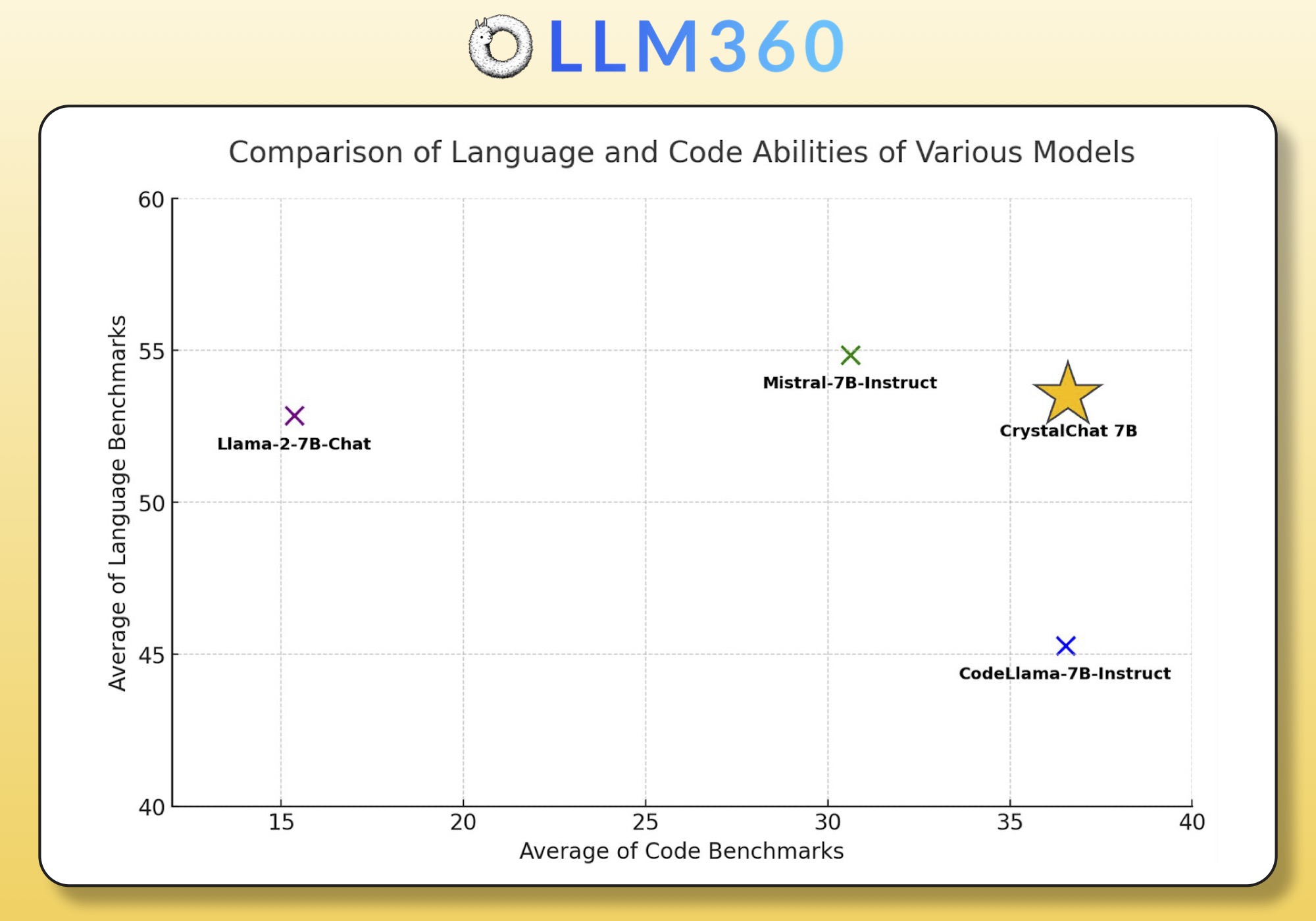 |
| Performance on Standard Benchmarks |
|---|
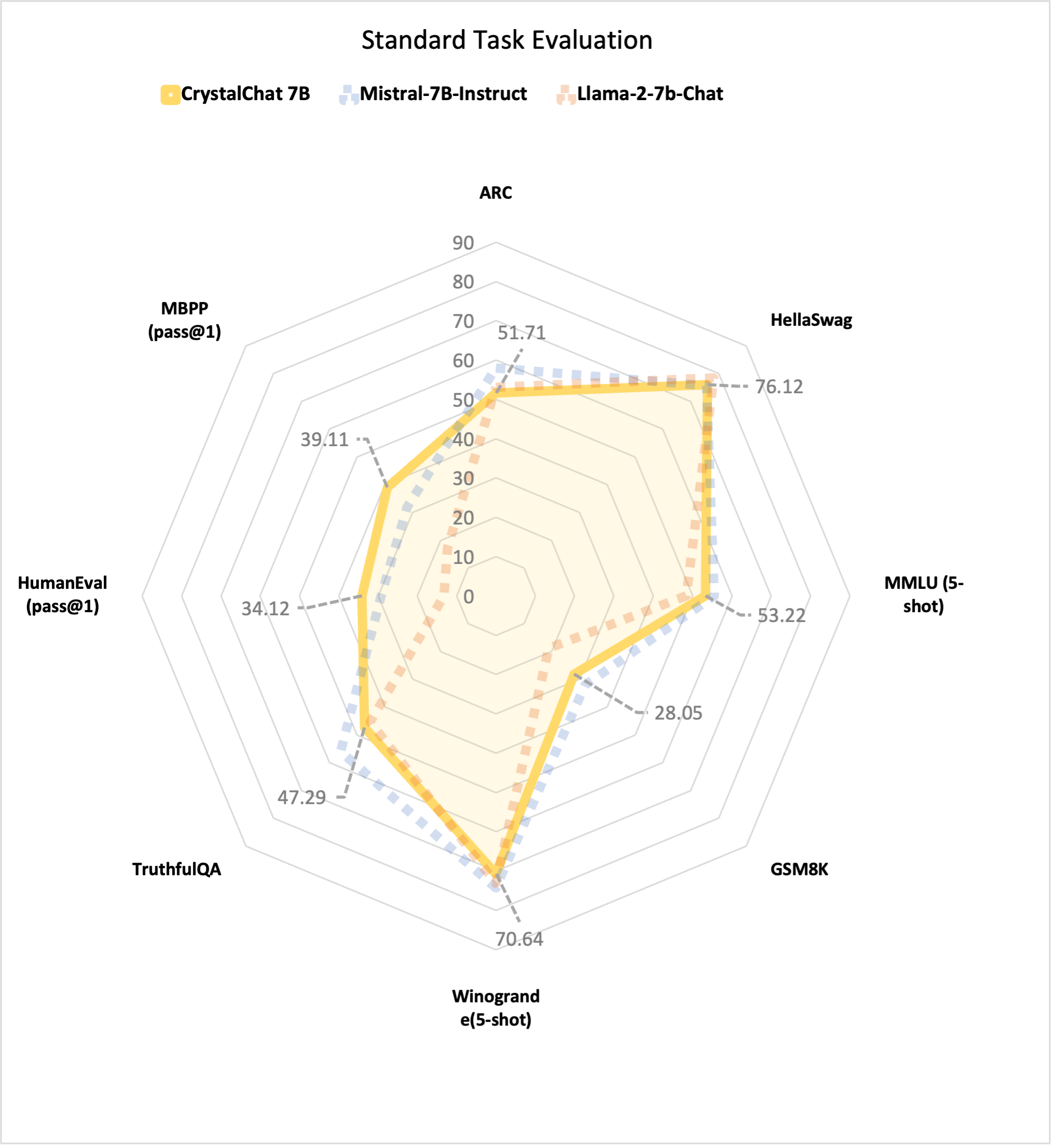 |
| Perforamnce on Language Benchmarks |
|---|
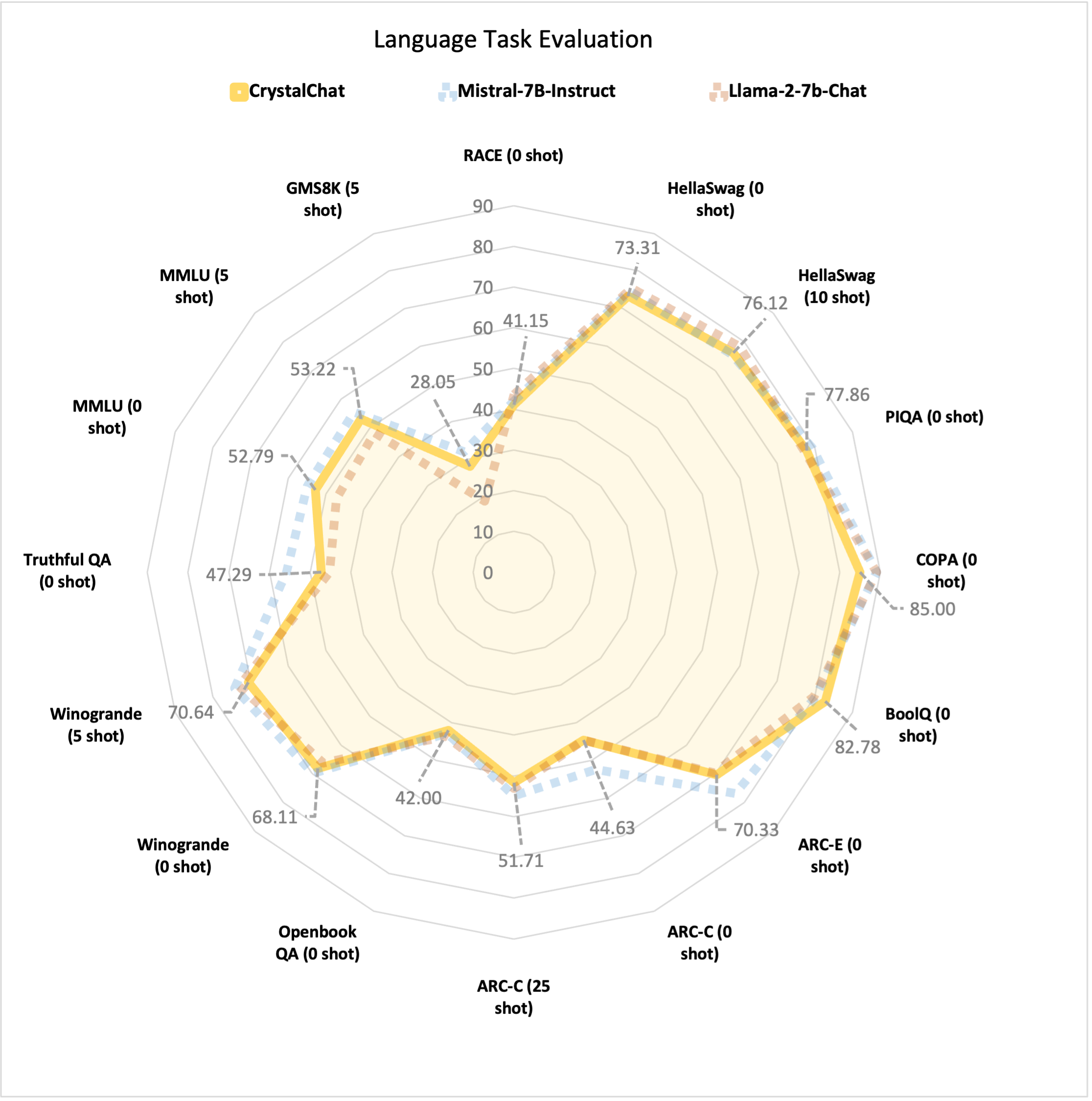 |
CrystalChat is using the last CrystalCoder checkpoint of phase2 (CrystalCoder_phase2_checkpoint_214387) as the initialization checkpoint. We then finetune the model using the dataset mentioned below.
We also performed the same finetuning on the last CrystalCoder checkpoint of phase3 (CrystalCoder_phase3_checkpoint_027728). The phase2 and phase3 finetuning results are very similar, but phase2 finetuning exhibits slightly better performance on the English language benchmarks. We choose the phase2 finetuning result as the final model for CrystalChat.
The fine-tuning data is a mix of publicly available language and code datasets, plus a orginally created dataset called WebAlpaca on HTML coding instructions. The WebAlpaca dataset is created by us and is used as part of our instruction tuning training data. We will release the WebAlpaca dataset in a separate repository soon.
The summary of the fine-tuning data is as follows:
| Subset | #Tokens | Avg. #Q | Avg. Query Len | Avg. #R | Avg. Reply Len |
|---|---|---|---|---|---|
| OASST1-guanaco | 4,464,640 | 1.36 | 38.28 | 1.36 | 271.69 |
| SlimOrca | 225,628,160 | 1.00 | 259.16 | 1.00 | 151.12 |
| ShareGPT | 112,914,432 | 3.28 | 94.53 | 3.64 | 365.81 |
| Evol-ShareGPT | 85,954,560 | 1.00 | 145.99 | 1.00 | 425.17 |
| ChatLogs | 29,337,600 | 3.39 | 95.58 | 3.24 | 191.42 |
| CodeAlpaca | 2,623,488 | 1.00 | 32.46 | 1.00 | 67.68 |
| Rosetta Code | 7,987,200 | 1.00 | 450.09 | 1.00 | 533.52 |
| Evol-CodeAlpaca 1 | 73,803,776 | 1.00 | 210.33 | 1.00 | 437.92 |
| Evol-CodeAlpaca 2 | 34,910,208 | 1.00 | 114.99 | 1.00 | 300.29 |
| WebAlpaca | 43,673,600 | 1.00 | 96.29 | 1.00 | 746.52 |
| General Textbooks | 85,590,016 | Not instruction data | |||
| Programming Books | 395,628,544 | Not instruction data | |||
| Total | 1,102,516,224 |
For more details, check out the data table.
We've added some new special tokens to the CrystalCoder tokenizer to support the instruction tuning.
List special tokens used in the instruction tuning:
bos: <s>
eos: </s>
system_start: <|sys_start|>
system_end: <|sys_end|>
user_start: <|im_start|>
user_end: <|im_end|>
The instruction format is as follows:
<s> <|sys_start|> system prompt <|sys_end|> <|im_start|> first user utterance <|im_end|> first model response <|im_start|> next user utterance <|im_end|> next model response </s>
We will release the training code and the training data soon. Our training code is based on Megatron-LM, with some modifications to support our training data format and Maximal Update Parametrization (μP).
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
device = "cuda:0" if torch.cuda.is_available() else "cpu"
tokenizer = AutoTokenizer.from_pretrained("LLM360/CrystalChat", trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained("LLM360/CrystalChat", trust_remote_code=True).to(device)
prompt = '<s> <|sys_start|> You are an AI assistant. You will be given a task. You must generate a detailed and long answer. <|sys_end|> <|im_start|> Write a python function that takes a list of integers and returns the squared sum of the list. <|im_end|>'
input_ids = tokenizer(prompt, return_tensors="pt").input_ids.to(device)
gen_tokens = model.generate(input_ids, do_sample=True, max_length=400)
print("-"*20 + "Output for model" + 20 * '-')
print(tokenizer.batch_decode(gen_tokens)[0])
Response:
Here's a Python function named `squared_sum_list` that takes a list of integers as input and returns the squared sum of the list:
```python
def squared_sum_list(lst):
return sum([num ** 2 for num in lst])
```
The function `squared_sum_list` uses a list comprehension to iterate over each number in the input list `lst` and calculate its square. Then, it uses the `sum` function to accumulate all the squared numbers in a single value - the squared sum of the list.
For example:
```python
numbers = [1, 2, 3, 4, 5]
print(squared_sum_list(numbers)) # Outputs: 55
```
In the above code, the list `[1, 2, 3, 4, 5]` is passed as an argument to the `squared_sum_list` function. The function calculates the sum of the squares of the elements in the list, which is `1 + 4 + 9 + 16 + 25 = 55`. The function then returns this result, which is printed to the console.</s>
Another chat example:
# ...
prompt = '<s> <|sys_start|> You are an AI assistant. You will be given a task. You must generate a detailed \
and long answer. <|sys_end|> <|im_start|> Give me a one-sentence description of crystal. And tell me what \
might the name "Crystal" mean for a transparant and open-source language model? <|im_end|>'
# ...
Response:
A crystal is an ordered, hexagonal lattice of atoms that displays a unique crystal structure resulting in transparency and diverse physical and chemical properties, and as a transparent and open-source language model, "Crystal" might represent transparency and accessibility by enabling users to understand the inner workings of the model.</s>
CrystalChat has not been aligned to human preferences for safety within the RLHF phase or deployed with in-the-loop filtering of responses like ChatGPT, so the model can produce problematic outputs (especially when prompted to do so). The training data is known and made available here. It primarily consists of SlimPajama, StarCoder, and WebCrawl dataset.
BibTeX:
@misc{liu2023llm360,
title={LLM360: Towards Fully Transparent Open-Source LLMs},
author={Zhengzhong Liu and Aurick Qiao and Willie Neiswanger and Hongyi Wang and Bowen Tan and Tianhua Tao and Junbo Li and Yuqi Wang and Suqi Sun and Omkar Pangarkar and Richard Fan and Yi Gu and Victor Miller and Yonghao Zhuang and Guowei He and Haonan Li and Fajri Koto and Liping Tang and Nikhil Ranjan and Zhiqiang Shen and Xuguang Ren and Roberto Iriondo and Cun Mu and Zhiting Hu and Mark Schulze and Preslav Nakov and Tim Baldwin and Eric P. Xing},
year={2023},
eprint={2312.06550},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
LLM360 is an initiative for comprehensive and fully open-sourced LLMs, where all training details, model checkpoints, intermediate results, and additional analyses are made available to the community. Our goal is to advance the field by inviting the community to deepen the understanding of LLMs together. As the first step of the project LLM360, we release all intermediate model checkpoints, our fully-prepared pre-training dataset, all source code and configurations, and training details. We are committed to continually pushing the boundaries of LLMs through this open-source effort.