Llama3-German-8B-32k (version 0.1)
This version of the model refers to the long-context extension version described below
Llama3-German-8B-v0.1 is a large language model based on Meta's Llama3-8B. It is specialized for the German language through continuous pretraining on 65 billion high-quality tokens, similar to previous LeoLM or Occiglot models.
Llama3 itself was trained on 15T tokens, of which only <1T were multilingual, resulting in suboptimal performance in German with reduced linguistic capabilities and frequent grammatical errors, motivating the necessity for continued pretraining. Benchmark results on our model show minimal degradation in English performance, despite the absence of replay during training. Importantly, Llama3-German-8B-v0.1 demonstrates strong improvements in German, particularly on the Hellaswag benchmark, which measures linguistic understanding and general reasoning.
DiscoResearch/Llama3-German-8B-v0.1 is the result of a joint effort between DiscoResearch and Occiglot with support from the DFKI (German Research Center for Artificial Intelligence) and hessian.Ai. Occiglot kindly handled data preprocessing, filtering, and deduplication as part of their latest dataset release, as well as sharing their compute allocation at hessian.Ai's 42 Supercomputer.
How to use
This is a base model and should probably be subject to finetuning before use. See our collection for various finetuned and long-context versions.
Model Training and Hyperparameters
The model was trained on 128 GPUs on hessian.Ai 42 for ~60 hours. See detailed hyperparameters below.
| Parameter |
Value |
| Sequence Length |
8192 tokens |
| Learning Rate |
1.5e-5 to 1.5e-6 (cosine schedule) |
| Batch Size |
4194304 (512*8192) tokens |
| Micro Batch Size |
4*8192 tokens |
| Training Steps |
15500 |
| Warmup Steps |
155 (1%) |
| Weight Decay |
0.05 |
| Optimizer |
AdamW |
Data Collection and Preprocessing
For pre-training, we used 65B German tokens from the occiglot-fineweb-0.5 dataset.
The data comprises multiple curated datasets from LLM-Datasets as well as 12 Common-Crawl releases that were processed with OSCAR's Ungoliant pipeline.
All data was further filtered with a set of language-specific filters based on Huggingface's fine-web and globally deduplicated.
For more information please refer to the dataset card and corresponding blog-post.
Evaluation and Results
We evaluated the model using a suite of common English Benchmarks and their German counterparts with GermanBench.
The following figure shows the benchmark results in comparison to the base model meta-llama/Meta-Llama3-8B and two different hyperparameter configurations.
We swept different learning rates to identify a well-working setup. The final released model is the 1.5e-5 lr version.
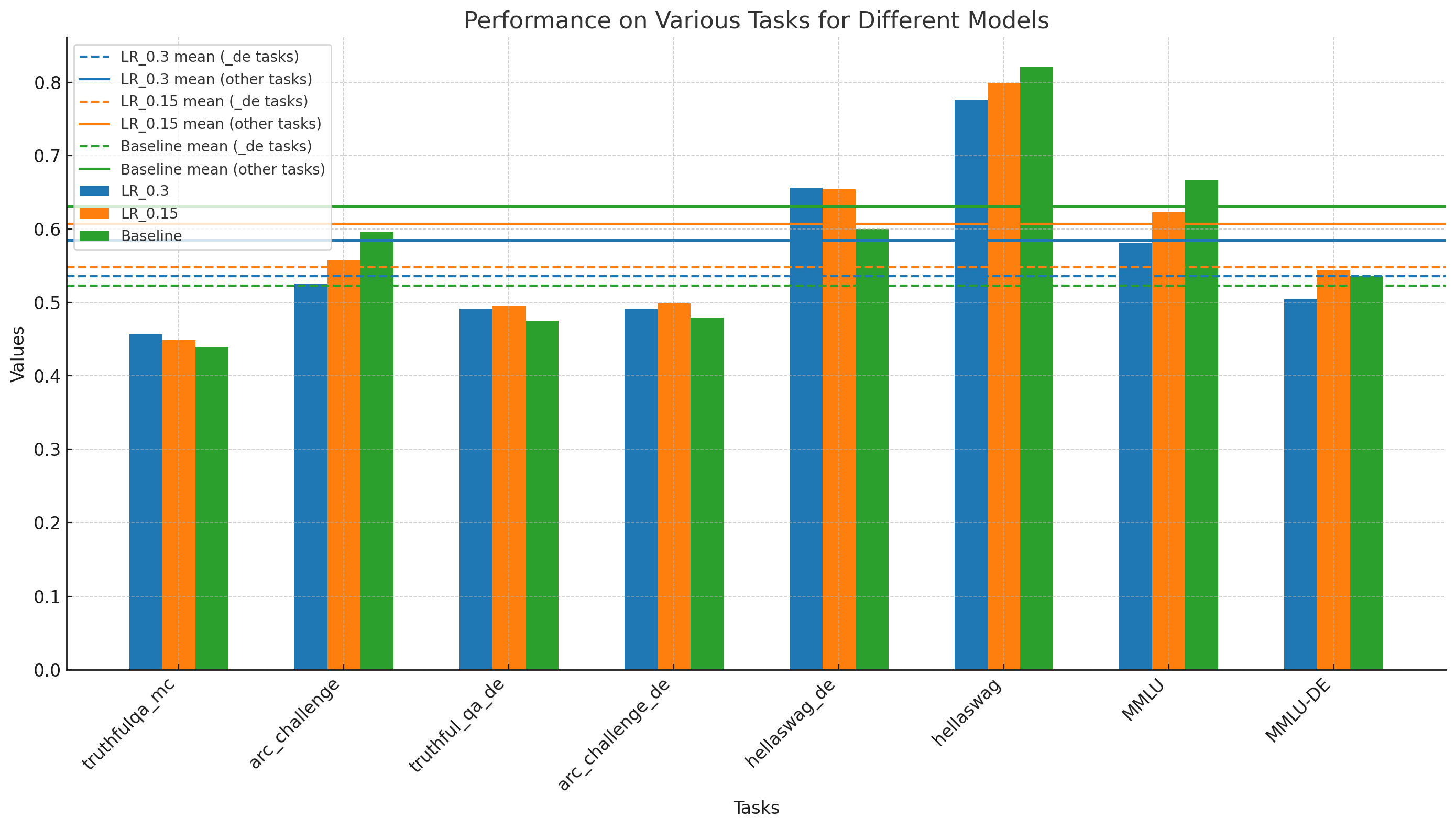
Find the detailed benchmark scores for the base and long-context models in this table.
| Model |
truthful_qa_de |
truthfulqa_mc |
arc_challenge |
arc_challenge_de |
hellaswag |
hellaswag_de |
MMLU |
MMLU-DE |
mean |
| DiscoResearch/Llama3-German-8B |
0.49499 |
0.44838 |
0.55802 |
0.49829 |
0.79924 |
0.65395 |
0.62240 |
0.54413 |
0.57743 |
| DiscoResearch/Llama3-German-8B-32k |
0.48920 |
0.45138 |
0.54437 |
0.49232 |
0.79078 |
0.64310 |
0.58774 |
0.47971 |
0.55982 |
| meta-llama/Meta-Llama-3-8B-Instruct |
0.47498 |
0.43923 |
0.59642 |
0.47952 |
0.82025 |
0.60008 |
0.66658 |
0.53541 |
0.57656 |
Long-Context Extension
In addition to the base model, we release a long-context version of Llama3-German-8B (DiscoResearch/Llama3-German-8B-32k capable of processing context lengths up to 65k tokens. This variant was trained on an additional 100 million tokens at 32k context length, using a rope_theta value of 1.5e6 and a learning rate of 1.5e-5 with a batch size of 256*8192 tokens and otherwise equal hyperparameters to the base model.
Instruction Tuning
We also provide an instruction-tuned version: DiscoResearch/Llama3-DiscoLeo-Instruct-8B-v0.1, utilizing the DiscoLM German dataset for fine-tuning (also available as a long-context model at DiscoResearch/Llama3-DiscoLeo-Instruct-8B-32k-v0.1).
Find more details in the respective model cards. Also check out our experimental merge (DiscoResearch/Llama3-DiscoLeo-8B-DARE-Experimental) between meta-llama/Meta-Llama3-8B-Instruct and our finetuned model in an attempt to keep the extraordinary capabilities of Llama3-Instruct and add exceptional German skills.
Document Packing
We employed a more intelligent document packing strategy based on the "Fewer Truncations Improve Language Modeling" paper by Ding et al., using the first-fit-decreasing algorithm to pack documents into batches without truncation.
We packed our data in chunks of 10000 documents for more efficient processing while maintaining >99% packing efficiency. Documents longer than the sequence length are split into chunks of sequence length.
This approach results in overall higher benchmark scores when training on the same data with equal hyperparameters. The following numbers are from initial experiments with 3e-5 lr and 12k steps and show improvements comparable to those shown in the original paper.
| Task |
Naive Packing |
Fewer Truncations Packing |
Percentage Increase |
| truthfulqa_mc |
0.452648 |
0.467687 |
3.32% |
| arc_challenge |
0.517918 |
0.528157 |
1.98% |
| truthful_qa_de |
0.485529 |
0.492979 |
1.53% |
| arc_challenge_de |
0.480375 |
0.493174 |
2.66% |
| hellaswag |
0.776041 |
0.773352 |
-0.35% |
| hellaswag_de |
0.655248 |
0.653356 |
-0.29% |
| MMLU |
0.573719 |
0.579802 |
1.06% |
| MMLU-DE |
0.504509 |
0.503863 |
-0.13% |
The following is our simple implementation of the first-fit-decreasing algorithm described in the paper.
def pack_documents(tokenized_documents):
sorted_docs = sorted(tokenized_documents, key=len, reverse=True)
bins = []
def find_bin(doc):
for b in bins:
if sum(len(d) for d in b) + len(doc) <= 8192:
return b
return None
for doc in sorted_docs:
target_bin = find_bin(doc)
if target_bin is not None:
target_bin.append(doc)
else:
bins.append([doc])
return bins
Model Configurations
We release DiscoLeo-8B in the following configurations:
- Base model with continued pretraining
- Long-context version (32k context length)
- Instruction-tuned version of the base model
- Instruction-tuned version of the long-context model
- Experimental
DARE-TIES Merge with Llama3-Instruct
- Collection of Quantized versions
How to use:
Here's how to use the model with transformers:
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
device="cuda"
model = AutoModelForCausalLM.from_pretrained(
"DiscoResearch/Llama3-DiscoLeo-Instruct-8B-v0.1",
torch_dtype="auto",
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained("DiscoResearch/Llama3-DiscoLeo-Instruct-8B-v0.1")
prompt = "Schreibe ein Essay über die Bedeutung der Energiewende für Deutschlands Wirtschaft"
messages = [
{"role": "system", "content": "Du bist ein hilfreicher Assistent."},
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(device)
generated_ids = model.generate(
model_inputs.input_ids,
max_new_tokens=512
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
Acknowledgements
The model was trained and evaluated by Björn Plüster (DiscoResearch, ellamind) with data preparation and project supervision by Manuel Brack (DFKI, TU-Darmstadt). Initial work on dataset collection and curation was performed by Malte Ostendorff and Pedro Ortiz Suarez. Instruction tuning was done with the DiscoLM German dataset created by Jan-Philipp Harries and Daniel Auras (DiscoResearch, ellamind). We extend our gratitude to LAION and friends, especially Christoph Schuhmann and Jenia Jitsev, for initiating this collaboration.
The model training was supported by a compute grant at the 42 supercomputer which is a central component in the development of hessian AI, the AI Innovation Lab (funded by the Hessian Ministry of Higher Education, Research and the Art (HMWK) & the Hessian Ministry of the Interior, for Security and Homeland Security (HMinD)) and the AI Service Centers (funded by the Federal Ministry of Education and Research (BMBF)).
The curation of the training data is partially funded by the German Federal Ministry for Economic Affairs and Climate Action (BMWK)
through the project OpenGPT-X (project no. 68GX21007D).

