
Executable Code Actions Elicit Better LLM Agents
💻 Code • 📃 Paper • 🤗 Data (CodeActInstruct) • 🤗 Model (CodeActAgent-Mistral-7b-v0.1) • 🤖 Chat with CodeActAgent!
We propose to use executable Python code to consolidate LLM agents’ actions into a unified action space (CodeAct). Integrated with a Python interpreter, CodeAct can execute code actions and dynamically revise prior actions or emit new actions upon new observations (e.g., code execution results) through multi-turn interactions.
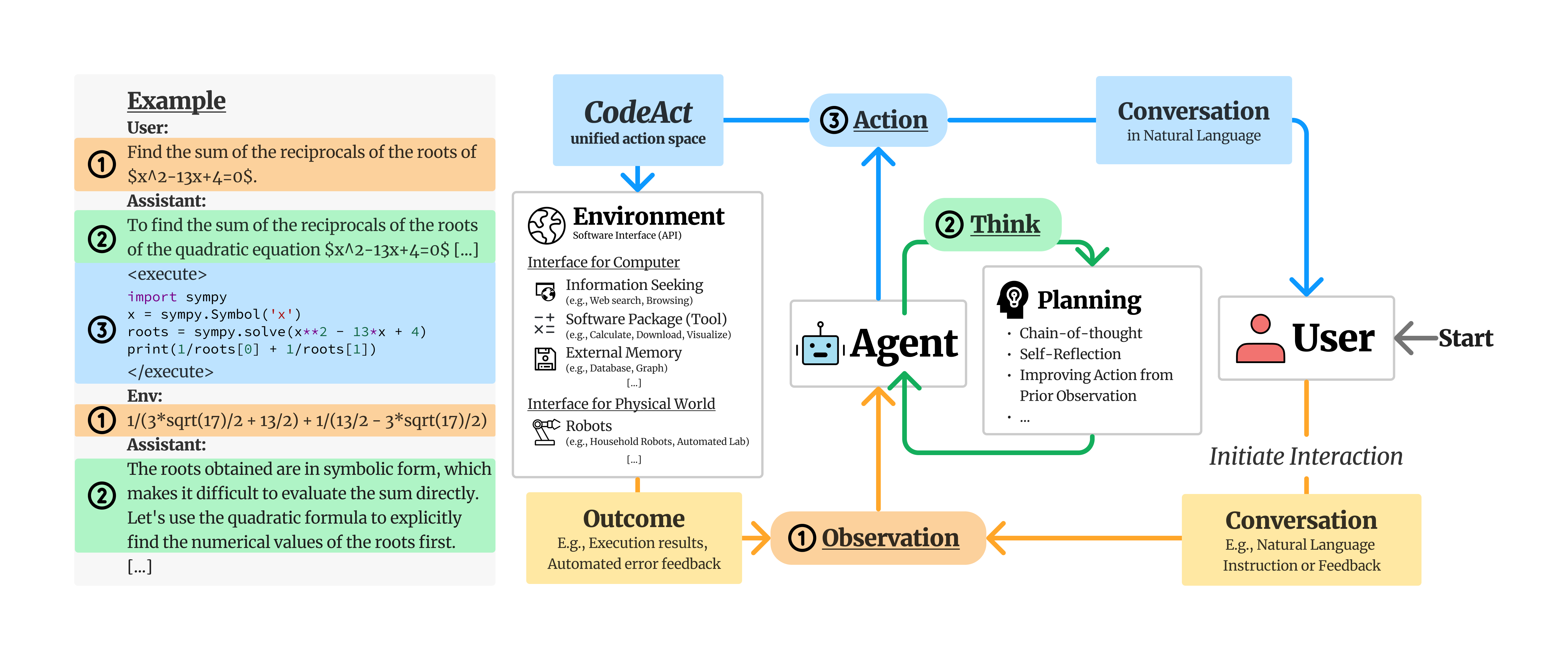
Why CodeAct?
Our extensive analysis of 17 LLMs on API-Bank and a newly curated benchmark M3ToolEval shows that CodeAct outperforms widely used alternatives like Text and JSON (up to 20% higher success rate). Please check our paper for more detailed analysis!
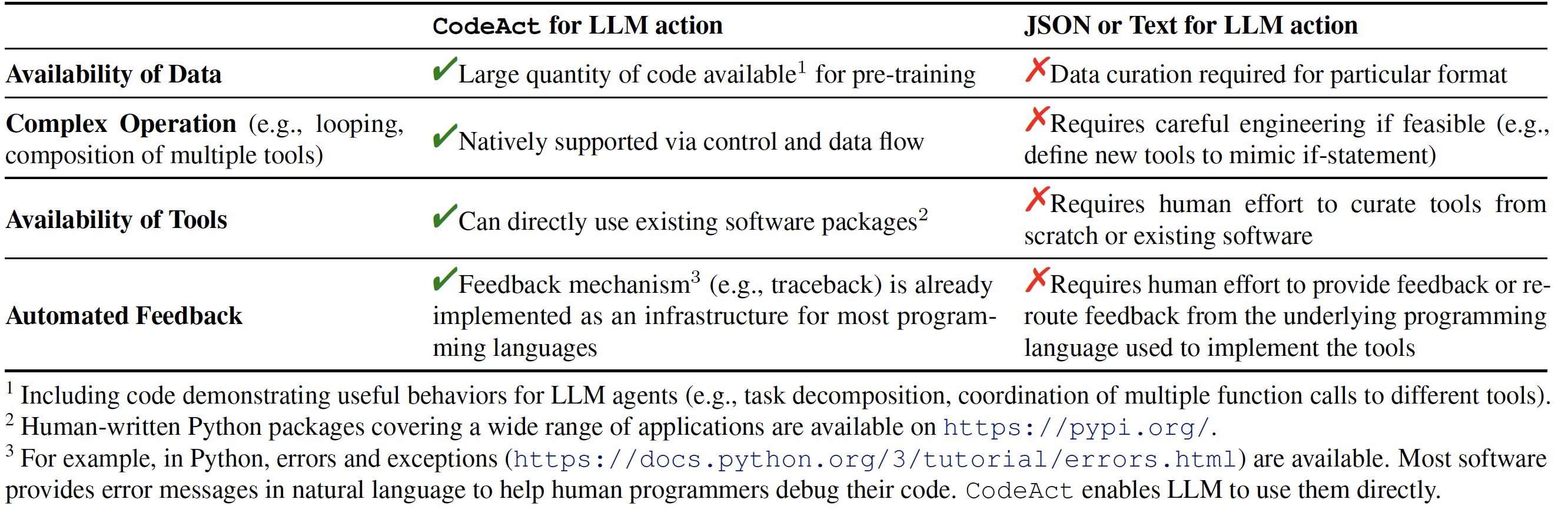 Comparison between CodeAct and Text / JSON as action.
Comparison between CodeAct and Text / JSON as action.
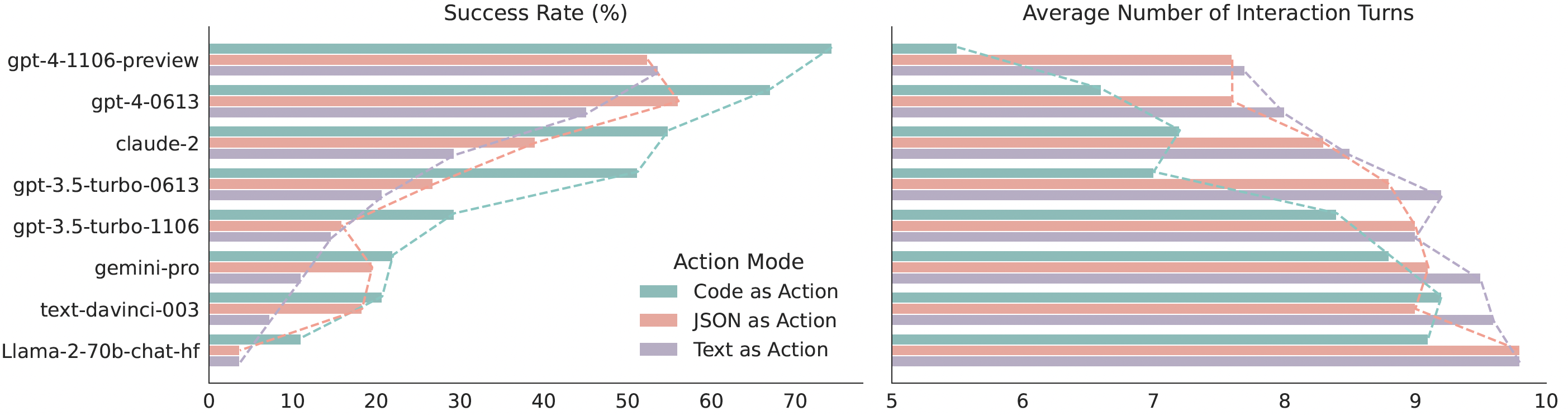 Quantitative results comparing CodeAct and {Text, JSON} on M3ToolEval.
Quantitative results comparing CodeAct and {Text, JSON} on M3ToolEval.
📁 CodeActInstruct
We collect an instruction-tuning dataset CodeActInstruct that consists of 7k multi-turn interactions using CodeAct. Dataset is release at huggingface dataset 🤗. Please refer to the paper and this section for details of data collection.
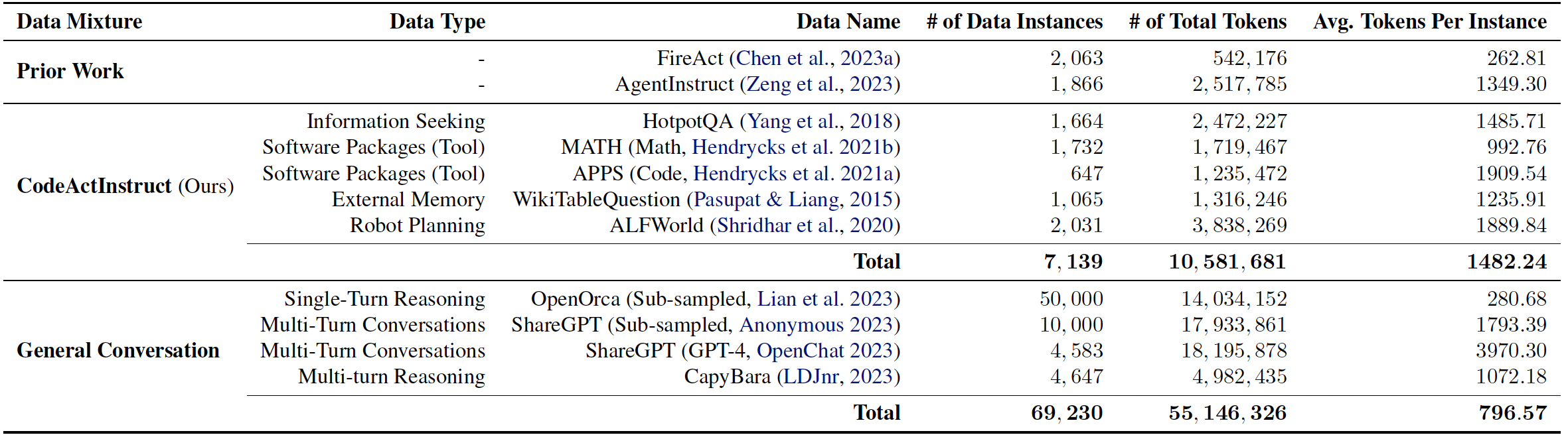 Dataset Statistics. Token statistics are computed using Llama-2 tokenizer.
Dataset Statistics. Token statistics are computed using Llama-2 tokenizer.
🪄 CodeActAgent
Trained on CodeActInstruct and general conversaions, CodeActAgent excels at out-of-domain agent tasks compared to open-source models of the same size, while not sacrificing generic performance (e.g., knowledge, dialog). We release two variants of CodeActAgent:
- CodeActAgent-Mistral-7b-v0.1 (recommended, model link): using Mistral-7b-v0.1 as the base model with 32k context window.
- CodeActAgent-Llama-7b (model link): using Llama-2-7b as the base model with 4k context window.
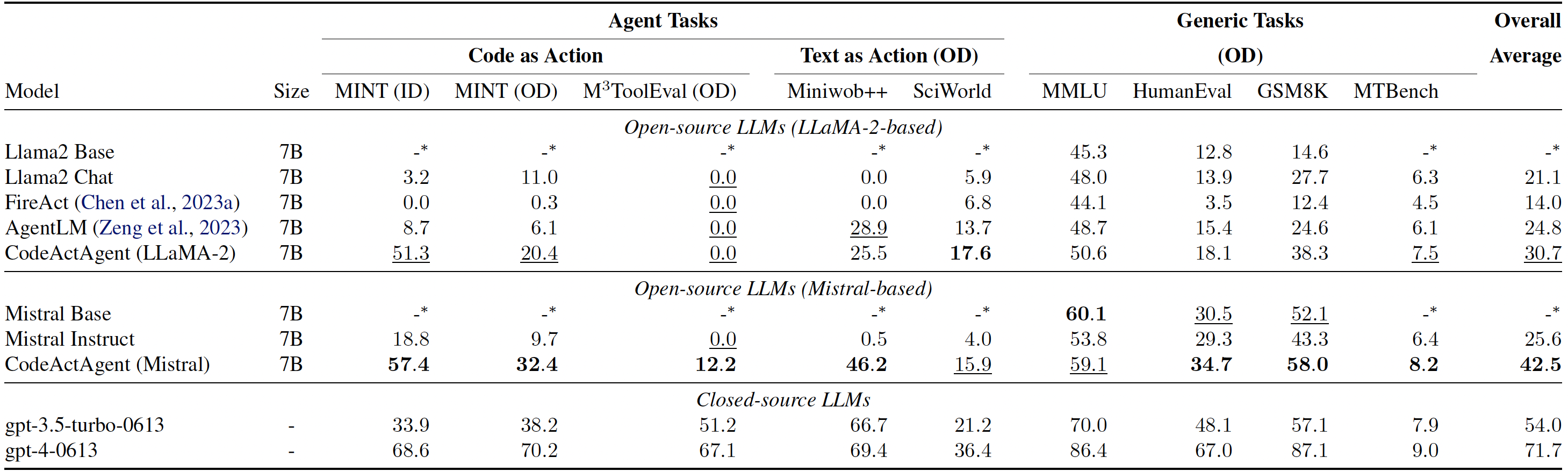 Evaluation results for CodeActAgent. ID and OD stand for in-domain and out-of-domain evaluation correspondingly. Overall averaged performance normalizes the MT-Bench score to be consistent with other tasks and excludes in-domain tasks for fair comparison.
Evaluation results for CodeActAgent. ID and OD stand for in-domain and out-of-domain evaluation correspondingly. Overall averaged performance normalizes the MT-Bench score to be consistent with other tasks and excludes in-domain tasks for fair comparison.
Please check out our paper and code for more details about data collection, model training, and evaluation.
📚 Citation
@misc{wang2024executable,
title={Executable Code Actions Elicit Better LLM Agents},
author={Xingyao Wang and Yangyi Chen and Lifan Yuan and Yizhe Zhang and Yunzhu Li and Hao Peng and Heng Ji},
year={2024},
eprint={2402.01030},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
- Downloads last month
- 41