
mT5-base-nsp
mT5-base-nsp is fine-tuned for Next Sentence Prediction task on the wikipedia dataset using google/mt5-base model. It was introduced in this paper and first released on this page.
Model description
mT5-base-nsp is a Transformer-based model which was fine-tuned for Next Sentence Prediction task on 2500 English, 2500 German, 2500 Turkish, 2500 Spanish and 2500 French Wikipedia articles.
Intended uses
- Apply Next Sentence Prediction tasks. (compare the results with BERT models since BERT natively supports this task)
- See how to fine-tune an mT5 model using our code
- Check our paper to see its results
How to use
You can use this model directly with a pipeline for next sentence prediction. Here is how to use this model in PyTorch:
Necessary Initialization
import torch
from transformers import MT5ForConditionalGeneration, MT5Tokenizer
from huggingface_hub import hf_hub_download
class ModelNSP(torch.nn.Module):
def __init__(self, pretrained_model, tokenizer, nsp_dim=300):
super(ModelNSP, self).__init__()
self.zero_token, self.one_token = (self.find_label_encoding(x, tokenizer).item() for x in ["0", "1"])
self.core_model = MT5ForConditionalGeneration.from_pretrained(pretrained_model)
self.nsp_head = torch.nn.Sequential(torch.nn.Linear(self.core_model.config.hidden_size, nsp_dim),
torch.nn.Linear(nsp_dim, nsp_dim), torch.nn.Linear(nsp_dim, 2))
def forward(self, input_ids, attention_mask=None):
outputs = self.core_model.generate(input_ids=input_ids, attention_mask=attention_mask, max_length=3,
output_scores=True, return_dict_in_generate=True)
logits = [torch.Tensor([score[self.zero_token], score[self.one_token]]) for score in outputs.scores[1]]
return torch.stack(logits).softmax(dim=-1)
@staticmethod
def find_label_encoding(input_str, tokenizer):
encoded_str = tokenizer.encode(input_str, add_special_tokens=False, return_tensors="pt")
return (torch.index_select(encoded_str, 1, torch.tensor([1])) if encoded_str.size(dim=1) == 2 else encoded_str)
tokenizer = MT5Tokenizer.from_pretrained("tolga-ozturk/mT5-base-nsp")
model = torch.nn.DataParallel(ModelNSP("google/mt5-base", tokenizer).eval())
model.load_state_dict(torch.load(hf_hub_download(repo_id="tolga-ozturk/mT5-base-nsp", filename="model_weights.bin")))
Inference
batch_texts = [("In Italy, pizza is presented unsliced.", "The sky is blue."),
("In Italy, pizza is presented unsliced.", "However, it is served sliced in Turkey.")]
encoded_dict = tokenizer.batch_encode_plus(batch_text_or_text_pairs=batch_texts, truncation="longest_first", padding=True, return_tensors="pt", return_attention_mask=True, max_length=256)
print(torch.argmax(model(encoded_dict.input_ids, attention_mask=encoded_dict.attention_mask), dim=-1))
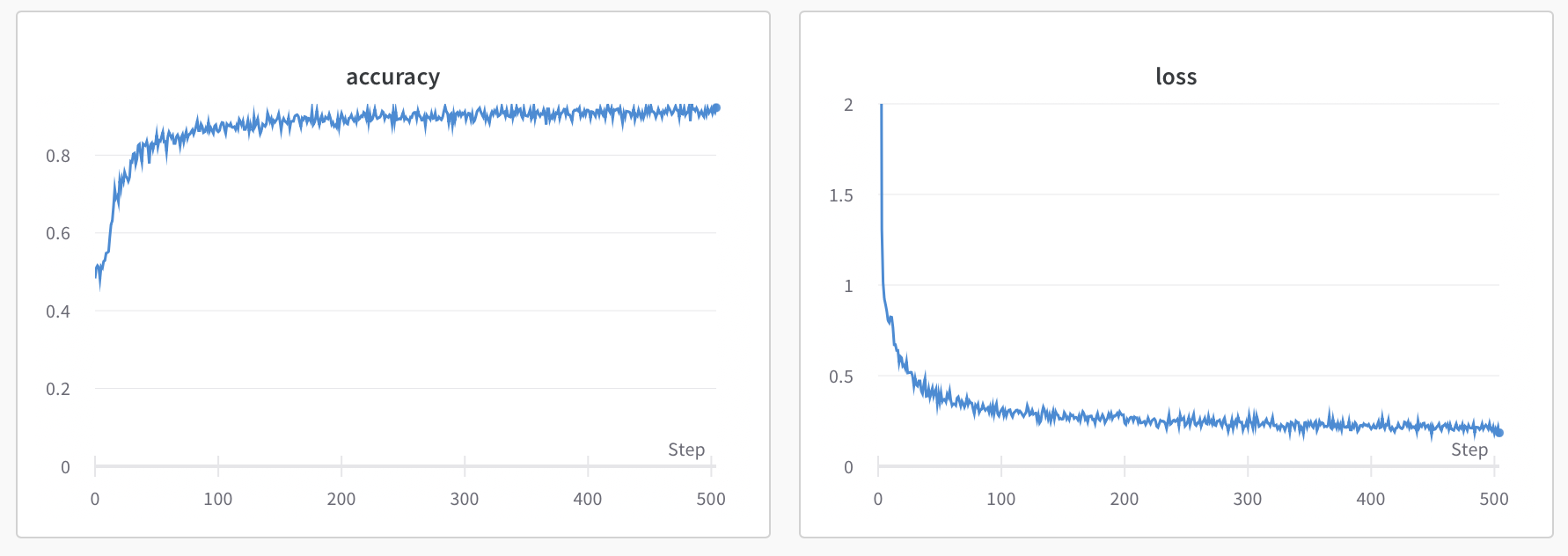
Training Metrics
BibTeX entry and citation info
@misc{title={How Different Is Stereotypical Bias Across Languages?},
author={Ibrahim Tolga Öztürk and Rostislav Nedelchev and Christian Heumann and Esteban Garces Arias and Marius Roger and Bernd Bischl and Matthias Aßenmacher},
year={2023},
eprint={2307.07331},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
The work is done with Ludwig-Maximilians-Universität Statistics group, don't forget to check out their huggingface page for other interesting works!
- Downloads last month
- 18
Inference Providers
NEW
This model isn't deployed by any Inference Provider.
🙋
Ask for provider support
HF Inference deployability: The model has no pipeline_tag.