
Image
Collection
text-to-image and image-to-image models
•
8 items
•
Updated
•
83

This model is built upon the Würstchen architecture and its main
difference to other models like Stable Diffusion is that it is working at a much smaller latent space. Why is this
important? The smaller the latent space, the faster you can run inference and the cheaper the training becomes.
How small is the latent space? Stable Diffusion uses a compression factor of 8, resulting in a 1024x1024 image being
encoded to 128x128. Stable Cascade achieves a compression factor of 42, meaning that it is possible to encode a
1024x1024 image to 24x24, while maintaining crisp reconstructions. The text-conditional model is then trained in the
highly compressed latent space. Previous versions of this architecture, achieved a 16x cost reduction over Stable
Diffusion 1.5.
Therefore, this kind of model is well suited for usages where efficiency is important. Furthermore, all known extensions
like finetuning, LoRA, ControlNet, IP-Adapter, LCM etc. are possible with this method as well.
Stable Cascade is a diffusion model trained to generate images given a text prompt.
For research purposes, we recommend our StableCascade Github repository (https://github.com/Stability-AI/StableCascade).
Stable Cascade consists of three models: Stage A, Stage B and Stage C, representing a cascade to generate images, hence the name "Stable Cascade". Stage A & B are used to compress images, similar to what the job of the VAE is in Stable Diffusion. However, with this setup, a much higher compression of images can be achieved. While the Stable Diffusion models use a spatial compression factor of 8, encoding an image with resolution of 1024 x 1024 to 128 x 128, Stable Cascade achieves a compression factor of 42. This encodes a 1024 x 1024 image to 24 x 24, while being able to accurately decode the image. This comes with the great benefit of cheaper training and inference. Furthermore, Stage C is responsible for generating the small 24 x 24 latents given a text prompt. The following picture shows this visually.
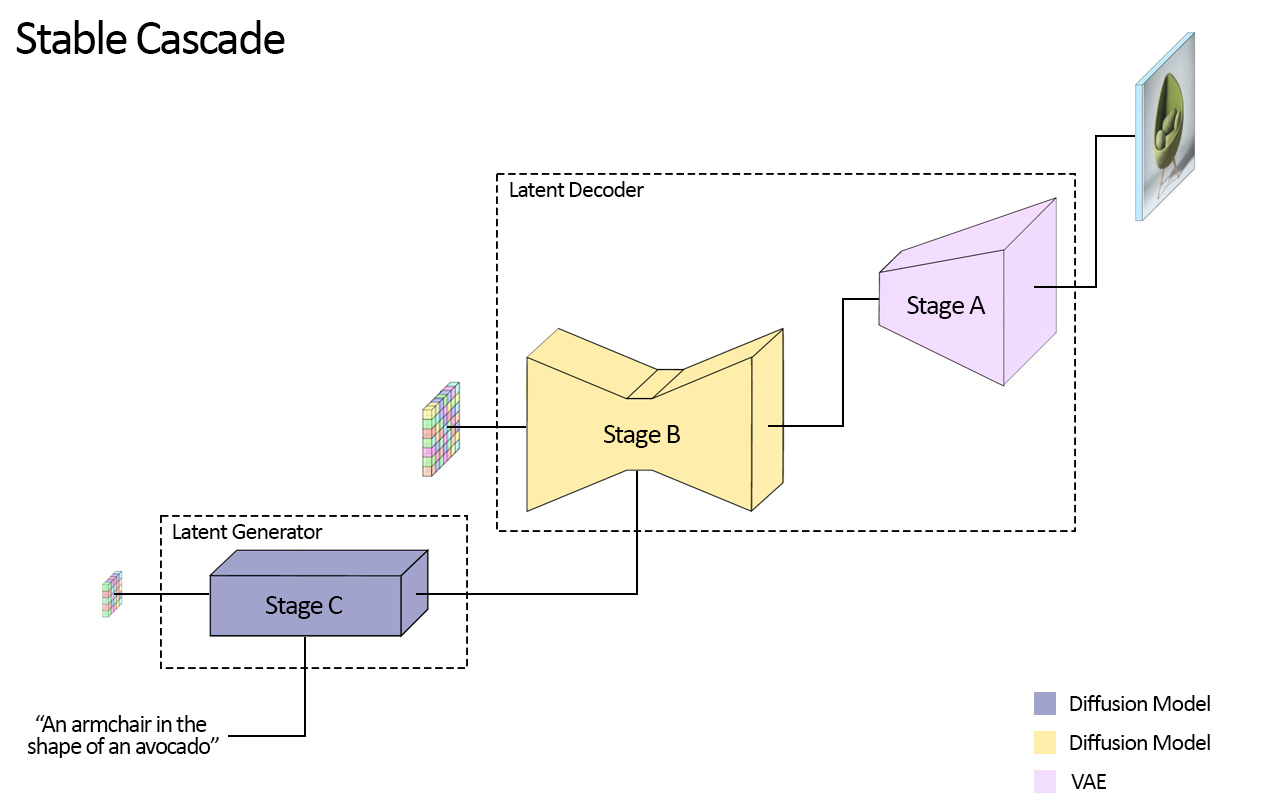
For this release, we are providing two checkpoints for Stage C, two for Stage B and one for Stage A. Stage C comes with a 1 billion and 3.6 billion parameter version, but we highly recommend using the 3.6 billion version, as most work was put into its finetuning. The two versions for Stage B amount to 700 million and 1.5 billion parameters. Both achieve great results, however the 1.5 billion excels at reconstructing small and fine details. Therefore, you will achieve the best results if you use the larger variant of each. Lastly, Stage A contains 20 million parameters and is fixed due to its small size.
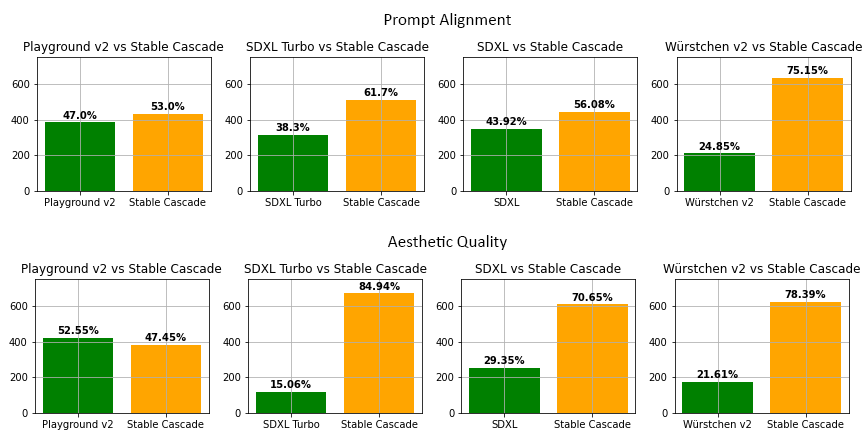 According to our evaluation, Stable Cascade performs best in both prompt alignment and aesthetic quality in almost all
comparisons. The above picture shows the results from a human evaluation using a mix of parti-prompts (link) and
aesthetic prompts. Specifically, Stable Cascade (30 inference steps) was compared against Playground v2 (50 inference
steps), SDXL (50 inference steps), SDXL Turbo (1 inference step) and Würstchen v2 (30 inference steps).
According to our evaluation, Stable Cascade performs best in both prompt alignment and aesthetic quality in almost all
comparisons. The above picture shows the results from a human evaluation using a mix of parti-prompts (link) and
aesthetic prompts. Specifically, Stable Cascade (30 inference steps) was compared against Playground v2 (50 inference
steps), SDXL (50 inference steps), SDXL Turbo (1 inference step) and Würstchen v2 (30 inference steps).
Note: In order to use the torch.bfloat16 data type with the StableCascadeDecoderPipeline you need to have PyTorch 2.2.0 or higher installed. This also means that using the StableCascadeCombinedPipeline with torch.bfloat16 requires PyTorch 2.2.0 or higher, since it calls the StableCascadeDecoderPipeline internally.
If it is not possible to install PyTorch 2.2.0 or higher in your environment, the StableCascadeDecoderPipeline can be used on its own with the torch.float16 data type. You can download the full precision or bf16 variant weights for the pipeline and cast the weights to torch.float16.
pip install diffusers
import torch
from diffusers import StableCascadeDecoderPipeline, StableCascadePriorPipeline
prompt = "an image of a shiba inu, donning a spacesuit and helmet"
negative_prompt = ""
prior = StableCascadePriorPipeline.from_pretrained("stabilityai/stable-cascade-prior", variant="bf16", torch_dtype=torch.bfloat16)
decoder = StableCascadeDecoderPipeline.from_pretrained("stabilityai/stable-cascade", variant="bf16", torch_dtype=torch.float16)
prior.enable_model_cpu_offload()
prior_output = prior(
prompt=prompt,
height=1024,
width=1024,
negative_prompt=negative_prompt,
guidance_scale=4.0,
num_images_per_prompt=1,
num_inference_steps=20
)
decoder.enable_model_cpu_offload()
decoder_output = decoder(
image_embeddings=prior_output.image_embeddings.to(torch.float16),
prompt=prompt,
negative_prompt=negative_prompt,
guidance_scale=0.0,
output_type="pil",
num_inference_steps=10
).images[0]
decoder_output.save("cascade.png")
import torch
from diffusers import (
StableCascadeDecoderPipeline,
StableCascadePriorPipeline,
StableCascadeUNet,
)
prompt = "an image of a shiba inu, donning a spacesuit and helmet"
negative_prompt = ""
prior_unet = StableCascadeUNet.from_pretrained("stabilityai/stable-cascade-prior", subfolder="prior_lite")
decoder_unet = StableCascadeUNet.from_pretrained("stabilityai/stable-cascade", subfolder="decoder_lite")
prior = StableCascadePriorPipeline.from_pretrained("stabilityai/stable-cascade-prior", prior=prior_unet)
decoder = StableCascadeDecoderPipeline.from_pretrained("stabilityai/stable-cascade", decoder=decoder_unet)
prior.enable_model_cpu_offload()
prior_output = prior(
prompt=prompt,
height=1024,
width=1024,
negative_prompt=negative_prompt,
guidance_scale=4.0,
num_images_per_prompt=1,
num_inference_steps=20
)
decoder.enable_model_cpu_offload()
decoder_output = decoder(
image_embeddings=prior_output.image_embeddings,
prompt=prompt,
negative_prompt=negative_prompt,
guidance_scale=0.0,
output_type="pil",
num_inference_steps=10
).images[0]
decoder_output.save("cascade.png")
from_single_file
Loading the original format checkpoints is supported via from_single_file method in the StableCascadeUNet.
import torch
from diffusers import (
StableCascadeDecoderPipeline,
StableCascadePriorPipeline,
StableCascadeUNet,
)
prompt = "an image of a shiba inu, donning a spacesuit and helmet"
negative_prompt = ""
prior_unet = StableCascadeUNet.from_single_file(
"https://huggingface.co/stabilityai/stable-cascade/resolve/main/stage_c_bf16.safetensors",
torch_dtype=torch.bfloat16
)
decoder_unet = StableCascadeUNet.from_single_file(
"https://huggingface.co/stabilityai/stable-cascade/blob/main/stage_b_bf16.safetensors",
torch_dtype=torch.bfloat16
)
prior = StableCascadePriorPipeline.from_pretrained("stabilityai/stable-cascade-prior", prior=prior_unet, torch_dtype=torch.bfloat16)
decoder = StableCascadeDecoderPipeline.from_pretrained("stabilityai/stable-cascade", decoder=decoder_unet, torch_dtype=torch.bfloat16)
prior.enable_model_cpu_offload()
prior_output = prior(
prompt=prompt,
height=1024,
width=1024,
negative_prompt=negative_prompt,
guidance_scale=4.0,
num_images_per_prompt=1,
num_inference_steps=20
)
decoder.enable_model_cpu_offload()
decoder_output = decoder(
image_embeddings=prior_output.image_embeddings,
prompt=prompt,
negative_prompt=negative_prompt,
guidance_scale=0.0,
output_type="pil",
num_inference_steps=10
).images[0]
decoder_output.save("cascade-single-file.png")
StableCascadeCombinedPipeline
from diffusers import StableCascadeCombinedPipeline
pipe = StableCascadeCombinedPipeline.from_pretrained("stabilityai/stable-cascade", variant="bf16", torch_dtype=torch.bfloat16)
prompt = "an image of a shiba inu, donning a spacesuit and helmet"
pipe(
prompt=prompt,
negative_prompt="",
num_inference_steps=10,
prior_num_inference_steps=20,
prior_guidance_scale=3.0,
width=1024,
height=1024,
).images[0].save("cascade-combined.png")
The model is intended for research purposes for now. Possible research areas and tasks include
Excluded uses are described below.
The model was not trained to be factual or true representations of people or events, and therefore using the model to generate such content is out-of-scope for the abilities of this model. The model should not be used in any way that violates Stability AI's Acceptable Use Policy.
The model is intended for research purposes only.