
SDXL LoRA DreamBooth - multimodalart/mouse-public-domain-rank16

- Prompt
- A <s0><s1> mouse cartoon piloting a boat

- Prompt
- A <s0><s1> mouse cartoon piloting a boat

- Prompt
- A <s0><s1> mouse cartoon pulling the boat's horn

- Prompt
- A <s0><s1> mouse cartoon zoom out piloting a boat

- Prompt
- A <s0><s1> mouse cartoon mad at a bucket
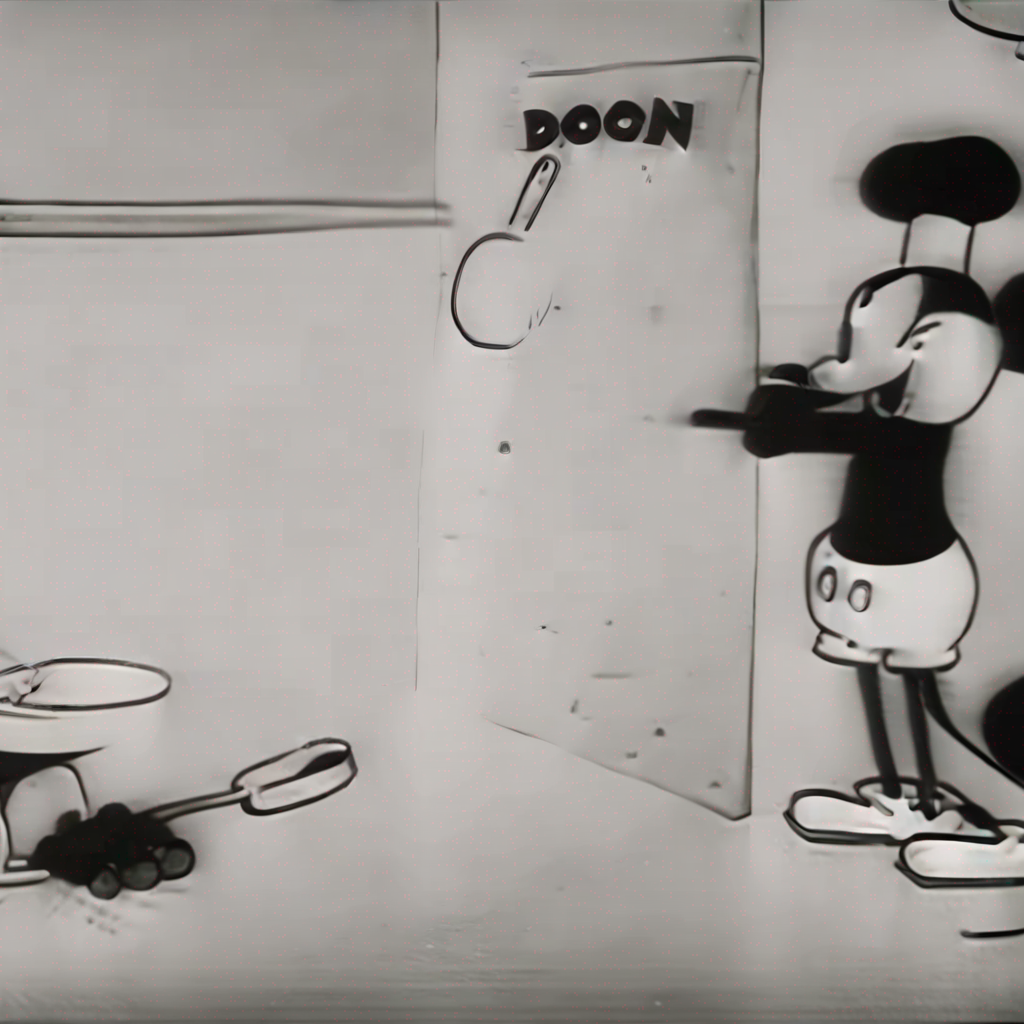
- Prompt
- A <s0><s1> mouse cartoon opening a dog's mouth

- Prompt
- A <s0><s1> mouse cartoon dancing in the kitchen

- Prompt
- A <s0><s1> mouse cartoon looking at a cow

- Prompt
- A <s0><s1> mouse cartoon plahying musical instruments

- Prompt
- A <s0><s1> mouse cartoon sitting down
Model description
These are multimodalart/mouse-public-domain-rank16 LoRA adaption weights for stabilityai/stable-diffusion-xl-base-1.0.
Download model
Use it with UIs such as AUTOMATIC1111, Comfy UI, SD.Next, Invoke
- LoRA: download
mouse-public-domain-rank16.safetensorshere 💾.- Place it on your
models/Lorafolder. - On AUTOMATIC1111, load the LoRA by adding
<lora:mouse-public-domain-rank16:1>to your prompt. On ComfyUI just load it as a regular LoRA.
- Place it on your
- Embeddings: download
mouse-public-domain-rank16_emb.safetensorshere 💾.- Place it on it on your
embeddingsfolder - Use it by adding
mouse-public-domain-rank16_embto your prompt. For example,A mouse-public-domain-rank16_emb mouse cartoon(you need both the LoRA and the embeddings as they were trained together for this LoRA)
- Place it on it on your
Use it with the 🧨 diffusers library
from diffusers import AutoPipelineForText2Image
import torch
from huggingface_hub import hf_hub_download
from safetensors.torch import load_file
pipeline = AutoPipelineForText2Image.from_pretrained('stabilityai/stable-diffusion-xl-base-1.0', torch_dtype=torch.float16).to('cuda')
pipeline.load_lora_weights('multimodalart/mouse-public-domain-rank16', weight_name='pytorch_lora_weights.safetensors')
embedding_path = hf_hub_download(repo_id='multimodalart/mouse-public-domain-rank16', filename='mouse-public-domain-rank16_emb.safetensors' repo_type="model")
state_dict = load_file(embedding_path)
pipeline.load_textual_inversion(state_dict["clip_l"], token=["<s0>", "<s1>"], text_encoder=pipeline.text_encoder, tokenizer=pipeline.tokenizer)
pipeline.load_textual_inversion(state_dict["clip_g"], token=["<s0>", "<s1>"], text_encoder=pipeline.text_encoder_2, tokenizer=pipeline.tokenizer_2)
image = pipeline('A <s0><s1> mouse cartoon ').images[0]
For more details, including weighting, merging and fusing LoRAs, check the documentation on loading LoRAs in diffusers
Trigger words
To trigger image generation of trained concept(or concepts) replace each concept identifier in you prompt with the new inserted tokens:
to trigger concept TOK → use <s0><s1> in your prompt
Details
All Files & versions.
The weights were trained using 🧨 diffusers Advanced Dreambooth Training Script.
LoRA for the text encoder was enabled. False.
Pivotal tuning was enabled: True.
Special VAE used for training: madebyollin/sdxl-vae-fp16-fix.
- Downloads last month
- 4
Model tree for multimodalart/mouse-public-domain-rank16
Base model
stabilityai/stable-diffusion-xl-base-1.0