What is RL? A short recap
In RL, we build an agent that can make smart decisions. For instance, an agent that learns to play a video game. Or a trading agent that learns to maximize its benefits by deciding on what stocks to buy and when to sell.
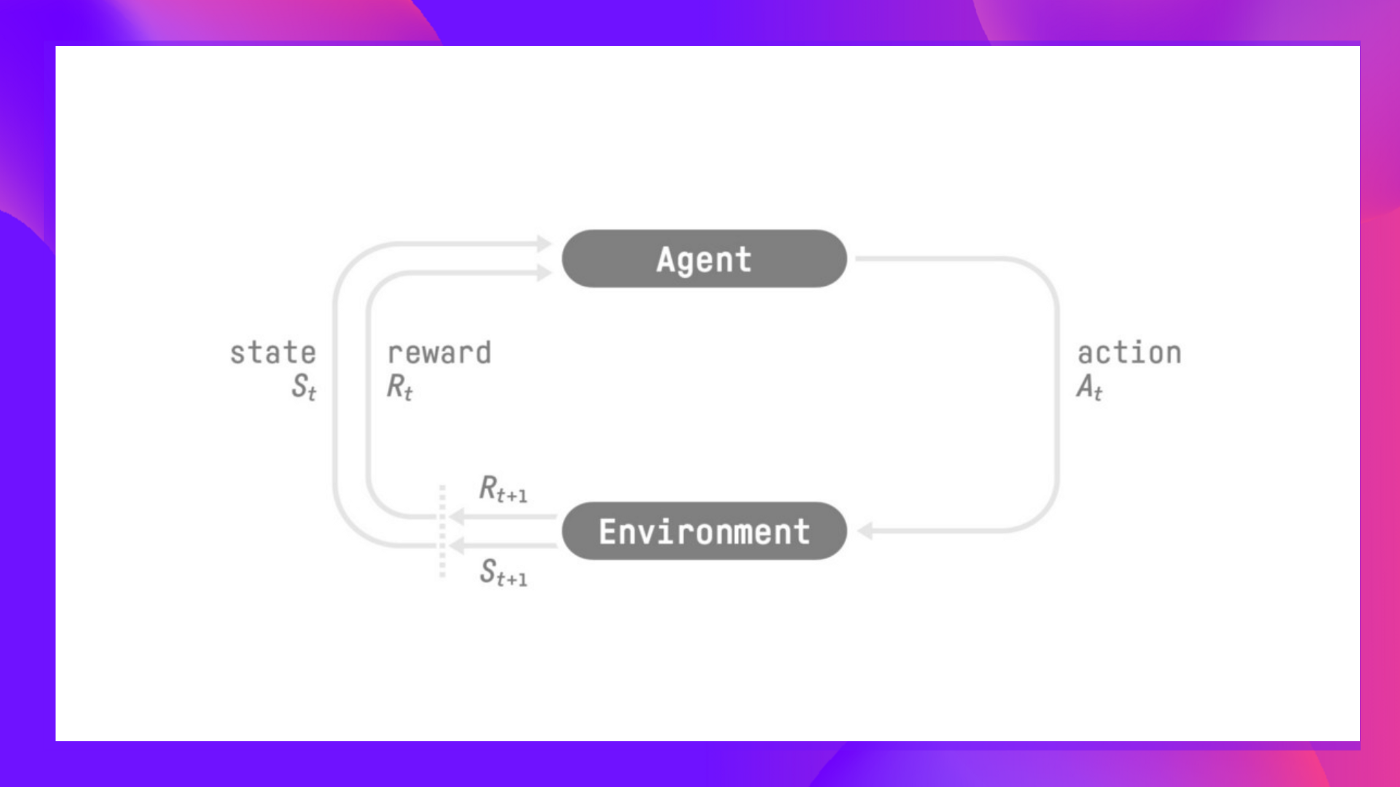
To make intelligent decisions, our agent will learn from the environment by interacting with it through trial and error and receiving rewards (positive or negative) as unique feedback.
Its goal is to maximize its expected cumulative reward (because of the reward hypothesis).
The agent’s decision-making process is called the policy π: given a state, a policy will output an action or a probability distribution over actions. That is, given an observation of the environment, a policy will provide an action (or multiple probabilities for each action) that the agent should take.

Our goal is to find an optimal policy π* , aka., a policy that leads to the best expected cumulative reward.
And to find this optimal policy (hence solving the RL problem), there are two main types of RL methods:
- Policy-based methods: Train the policy directly to learn which action to take given a state.
- Value-based methods: Train a value function to learn which state is more valuable and use this value function to take the action that leads to it.

And in this unit, we’ll dive deeper into the value-based methods.
< > Update on GitHub