Deep RL Course documentation
Q-Learning Recap
Q-Learning Recap
Q-Learning is the RL algorithm that :
Trains a Q-function, an action-value function encoded, in internal memory, by a Q-table containing all the state-action pair values.
Given a state and action, our Q-function will search its Q-table for the corresponding value.
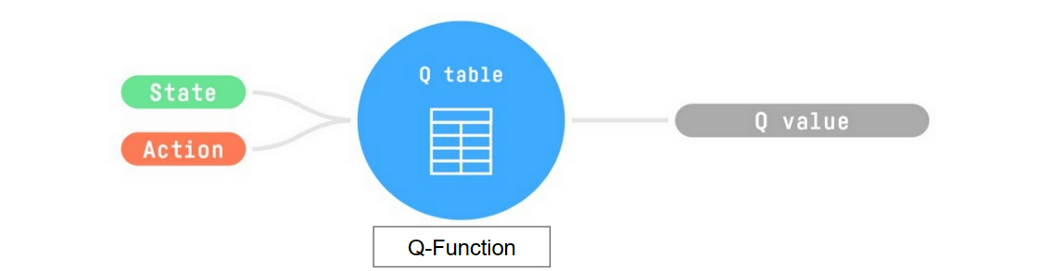
When the training is done, we have an optimal Q-function, or, equivalently, an optimal Q-table.
And if we have an optimal Q-function, we have an optimal policy, since we know, for each state, the best action to take.

But, in the beginning, our Q-table is useless since it gives arbitrary values for each state-action pair (most of the time we initialize the Q-table to 0 values). But, as we explore the environment and update our Q-table it will give us a better and better approximation.

This is the Q-Learning pseudocode:
 < > Update on GitHub
< > Update on GitHub