Suggestions for Data Annotation with SetFit in Zero-shot Text Classification
Authored by: David Berenstein and Sara Han Díaz
Suggestions are a wonderful way to make things easier and faster for your annotation team. These preselected options will make the labeling process more efficient, as they will only need to correct the suggestions. In this example, we will demonstrate how to implement a zero-shot approach using SetFit to get some initial suggestions for a dataset in Argilla that combines two text classification tasks that include a LabelQuestion and a MultiLabelQuestion.
Argilla is a collaboration tool for AI engineers and domain experts who need to build high-quality datasets for their projects. Using Argilla, everyone can build robust language models through faster data curation using both human and machine feedback.
Feedback is a crucial part of the data curation process, and Argilla also provides a way to manage and visualize it so that the curated data can be later used to improve a language model. In this tutorial, we will show a real example of how to make our annotators’ job easier by providing them with suggestions. To achieve this, you will learn how to train zero-shot sentiment and topic classifiers using SetFit and then use them to suggest labels for the dataset.
In this tutorial, we will follow these steps:
- Create a dataset in Argilla.
- Train the zero-shot classifiers using SetFit.
- Get suggestions for the dataset using the trained classifiers.
- Visualize the suggestions in Argilla.
Let’s get started!
Setup
For this tutorial, you will need to have an Argilla server running. If you have already deployed Argilla, you can skip this step. Otherwise, you can quickly deploy Argilla in HF Spaces or locally following this guide. Once you do, complete the following steps:
- Install the Argilla client and the required third-party libraries using
pip:
!pip install argilla
!pip install setfit==1.0.3 transformers==4.40.2 huggingface_hub==0.23.5- Make the necessary imports:
import argilla as rg
from datasets import load_dataset
from setfit import SetFitModel, Trainer, get_templated_dataset- If you are running Argilla using the Docker quickstart image or Hugging Face Spaces, you need to init the Argilla client with the
API_URLandAPI_KEY:
# Replace api_url with your url if using Docker
# Replace api_key if you configured a custom API key
# Uncomment the last line and set your HF_TOKEN if your space is private
client = rg.Argilla(
api_url="https://[your-owner-name]-[your_space_name].hf.space",
api_key="[your-api-key]",
# headers={"Authorization": f"Bearer {HF_TOKEN}"}
)Configure the dataset
In this example, we will load the banking77 dataset, a popular open-source dataset that has customer requests in the banking domain.
data = load_dataset("PolyAI/banking77", split="test")Argilla works with the Dataset class, which easily enables you to create a dataset and manage the data and feedback. The Dataset has first to be configured. In the Settings, we can specify the guidelines, fields where the data to be annotated will be added and the questions for the annotators. However, more features can be added. For more information, check the Argilla how-to guides.
For our use case, we need a text field and two different questions. We will use the original labels of this dataset to make a multi-label classification of the topics mentioned in the request, and we will also set up a label question to classify the sentiment of the request as either “positive”, “neutral” or “negative”.
settings = rg.Settings(
fields=[rg.TextField(name="text")],
questions=[
rg.MultiLabelQuestion(
name="topics",
title="Select the topic(s) of the request",
labels=data.info.features["label"].names,
visible_labels=10,
),
rg.LabelQuestion(
name="sentiment",
title="What is the sentiment of the message?",
labels=["positive", "neutral", "negative"],
),
],
)
dataset = rg.Dataset(
name="setfit_tutorial_dataset",
settings=settings,
)
dataset.create()Train the models
Now, we will use the data we loaded from HF and the labels and questions we configured for our dataset to train a zero-shot text classification model for each of the questions in our dataset. As mentioned in previous sections, we will use the SetFit framework for few-shot fine-tuning of Sentence Transformers in both classifiers. In addition, the model we will use is all-MiniLM-L6-v2, a sentence embedding model fine-tuned on a 1B sentence pairs dataset using a contrastive objective.
def train_model(question_name, template, multi_label=False):
train_dataset = get_templated_dataset(
candidate_labels=dataset.questions[question_name].labels,
sample_size=8,
template=template,
multi_label=multi_label,
)
# Train a model using the training dataset we just built
if multi_label:
model = SetFitModel.from_pretrained(
"sentence-transformers/all-MiniLM-L6-v2",
multi_target_strategy="one-vs-rest",
)
else:
model = SetFitModel.from_pretrained("sentence-transformers/all-MiniLM-L6-v2")
trainer = Trainer(model=model, train_dataset=train_dataset)
trainer.train()
return modeltopic_model = train_model(
question_name="topics",
template="The customer request is about {}",
multi_label=True,
)
# topic_model.save_pretrained(
# "/path-to-your-models-folder/topic_model"
# )sentiment_model = train_model(question_name="sentiment", template="This message is {}", multi_label=False)
# topic_model.save_pretrained(
# "/path-to-your-models-folder/sentiment_model"
# )Make predictions
Once the training step is over, we can make predictions over our data.
def get_predictions(texts, model, question_name):
probas = model.predict_proba(texts, as_numpy=True)
labels = dataset.questions[question_name].labels
for pred in probas:
yield [{"label": label, "score": score} for label, score in zip(labels, pred)]data = data.map(
lambda batch: {
"topics": list(get_predictions(batch["text"], topic_model, "topics")),
"sentiment": list(get_predictions(batch["text"], sentiment_model, "sentiment")),
},
batched=True,
)data.to_pandas().head()
Log the records to Argilla
With the data and the predictions we have produced, we can now build records (each of the data items that will be annotated by the annotator team) that include the suggestions from our models. In the case of the LabelQuestion we will use the label that received the highest probability score and for the MultiLabelQuestion we will include all labels with a score above a certain threshold. In this case, we decided to go for 2/len(labels), but you can experiment with your data and decide to go for a more restrictive or more lenient threshold.
Note that more lenient thresholds (closer or equal to
1/len(labels)) will suggest more labels, and restrictive thresholds (between 2 and 3) will select fewer (or no) labels.
def add_suggestions(record):
suggestions = []
# Get label with max score for sentiment question
sentiment = max(record["sentiment"], key=lambda x: x["score"])["label"]
suggestions.append(rg.Suggestion(question_name="sentiment", value=sentiment))
# Get all labels above a threshold for topics questions
threshold = 2 / len(dataset.questions["topics"].labels)
topics = [label["label"] for label in record["topics"] if label["score"] >= threshold]
if topics:
suggestions.append(rg.Suggestion(question_name="topics", value=topics))
return suggestionsrecords = [rg.Record(fields={"text": record["text"]}, suggestions=add_suggestions(record)) for record in data]Once we are happy with the result, we can log the records to the dataset that we configured above. You can now access the dataset in Argilla and visualize the suggestions.
dataset.records.log(records)
This is how the UI will look like with the suggestions from our models:
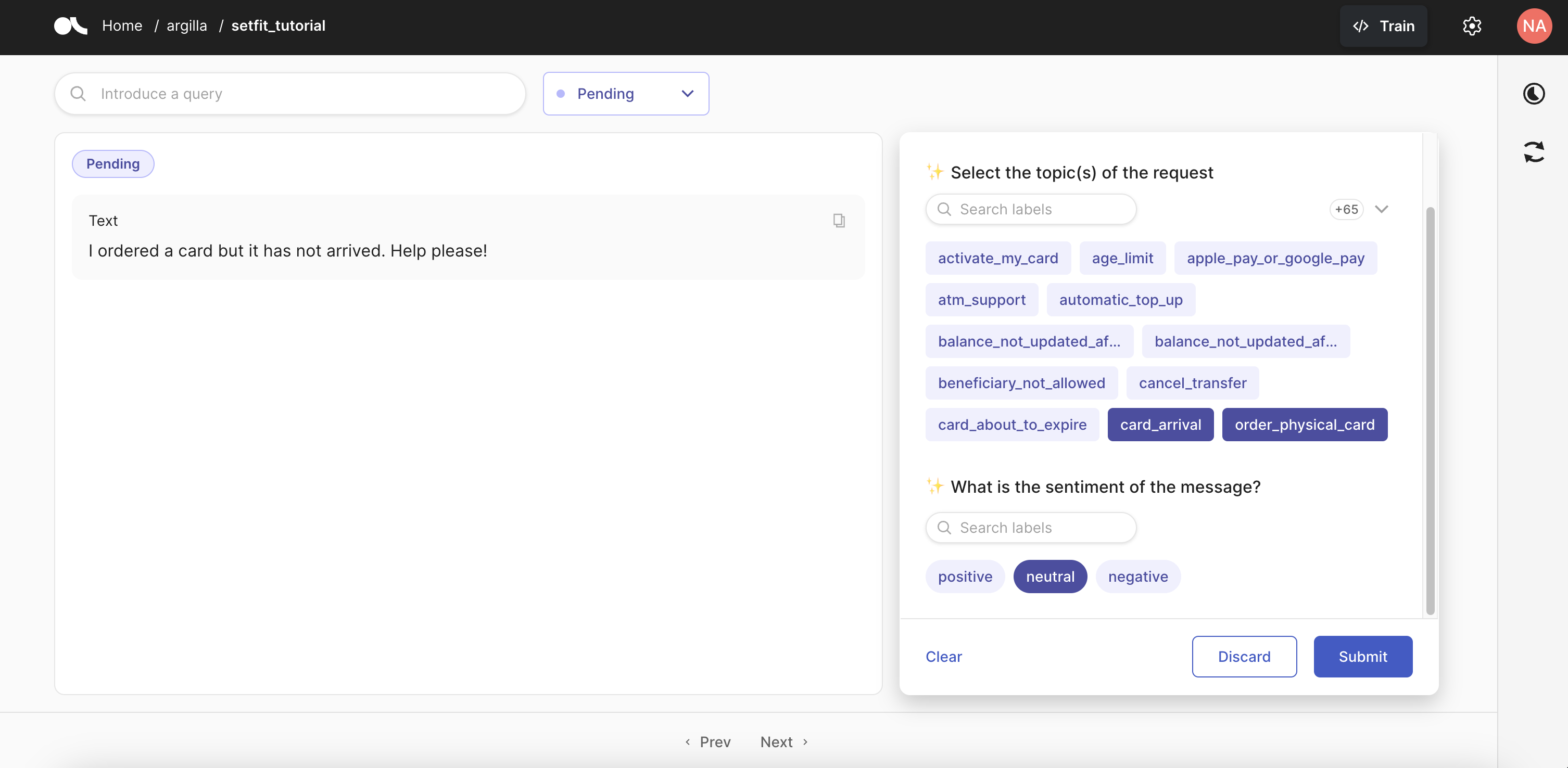
Optionally, you can also save and load your Argilla dataset into the Hugging Face Hub. Refer to the Argilla documentation for more information on how to do this.
# Export to HuggingFace Hub
dataset.to_hub(repo_id="argilla/my_setfit_dataset")
# Import from HuggingFace Hub
dataset = rg.Dataset.from_hub(repo_id="argilla/my_setfit_dataset")Conclusion
In this tutorial, we have covered how to add suggestions to an Argilla dataset using a zero-shot approach with the SetFit library. This will help with the efficiency of the labelling process by lowering the number of decisions and edits that the annotation team must make.
Check out these links for more resources:
< > Update on GitHub