Open-Source AI Cookbook documentation
Migrating from OpenAI to Open LLMs Using TGI’s Messages API
Migrating from OpenAI to Open LLMs Using TGI’s Messages API
Authored by: Andrew Reed
This notebook demonstrates how you can easily transition from OpenAI models to Open LLMs without needing to refactor any existing code.
Text Generation Inference (TGI) now offers a Messages API, making it directly compatible with the OpenAI Chat Completion API. This means that any existing scripts that use OpenAI models (via the OpenAI client library or third-party tools like LangChain or LlamaIndex) can be directly swapped out to use any open LLM running on a TGI endpoint!
This allows you to quickly test out and benefit from the numerous advantages offered by open models. Things like:
- Complete control and transparency over models and data
- No more worrying about rate limits
- The ability to fully customize systems according to your specific needs
In this notebook, we’ll show you how to:
- Create Inference Endpoint to Deploy a Model with TGI
- Query the Inference Endpoint with OpenAI Client Libraries
- Integrate the Endpoint with LangChain and LlamaIndex Workflows
Let’s dive in!
Setup
First we need to install dependencies and set an HF API key.
!pip install --upgrade -q huggingface_hub langchain langchain-community langchainhub langchain-openai llama-index chromadb bs4 sentence_transformers torch torchvision torchaudio llama-index-llms-openai-like llama-index-embeddings-huggingface
import os
import getpass
# enter API key
os.environ["HF_TOKEN"] = HF_API_KEY = getpass.getpass()1. Create an Inference Endpoint
To get started, let’s deploy Nous-Hermes-2-Mixtral-8x7B-DPO, a fine-tuned Mixtral model, to Inference Endpoints using TGI.
We can deploy the model in just a few clicks from the UI, or take advantage of the huggingface_hub Python library to programmatically create and manage Inference Endpoints.
We’ll use the Hub library here by specifing an endpoint name and model repository, along with the task of text-generation. In this example, we use a protected type so access to the deployed model will require a valid Hugging Face token. We also need to configure the hardware requirements like vendor, region, accelerator, instance type, and size. You can check out the list of available resource options using this API call, and view recommended configurations for select models in the catalog here.
Note: You may need to request a quota upgrade by sending an email to api-enterprise@huggingface.co
>>> from huggingface_hub import create_inference_endpoint
>>> endpoint = create_inference_endpoint(
... "nous-hermes-2-mixtral-8x7b-demo",
... repository="NousResearch/Nous-Hermes-2-Mixtral-8x7B-DPO",
... framework="pytorch",
... task="text-generation",
... accelerator="gpu",
... vendor="aws",
... region="us-east-1",
... type="protected",
... instance_type="p4de",
... instance_size="2xlarge",
... custom_image={
... "health_route": "/health",
... "env": {
... "MAX_INPUT_LENGTH": "4096",
... "MAX_BATCH_PREFILL_TOKENS": "4096",
... "MAX_TOTAL_TOKENS": "32000",
... "MAX_BATCH_TOTAL_TOKENS": "1024000",
... "MODEL_ID": "/repository",
... },
... "url": "ghcr.io/huggingface/text-generation-inference:sha-1734540", # must be >= 1.4.0
... },
... )
>>> endpoint.wait()
>>> print(endpoint.status)running
It will take a few minutes for our deployment to spin up. We can use the .wait() utility to block the running thread until the endpoint reaches a final “running” state. Once running, we can confirm its status and take it for a spin via the UI Playground:
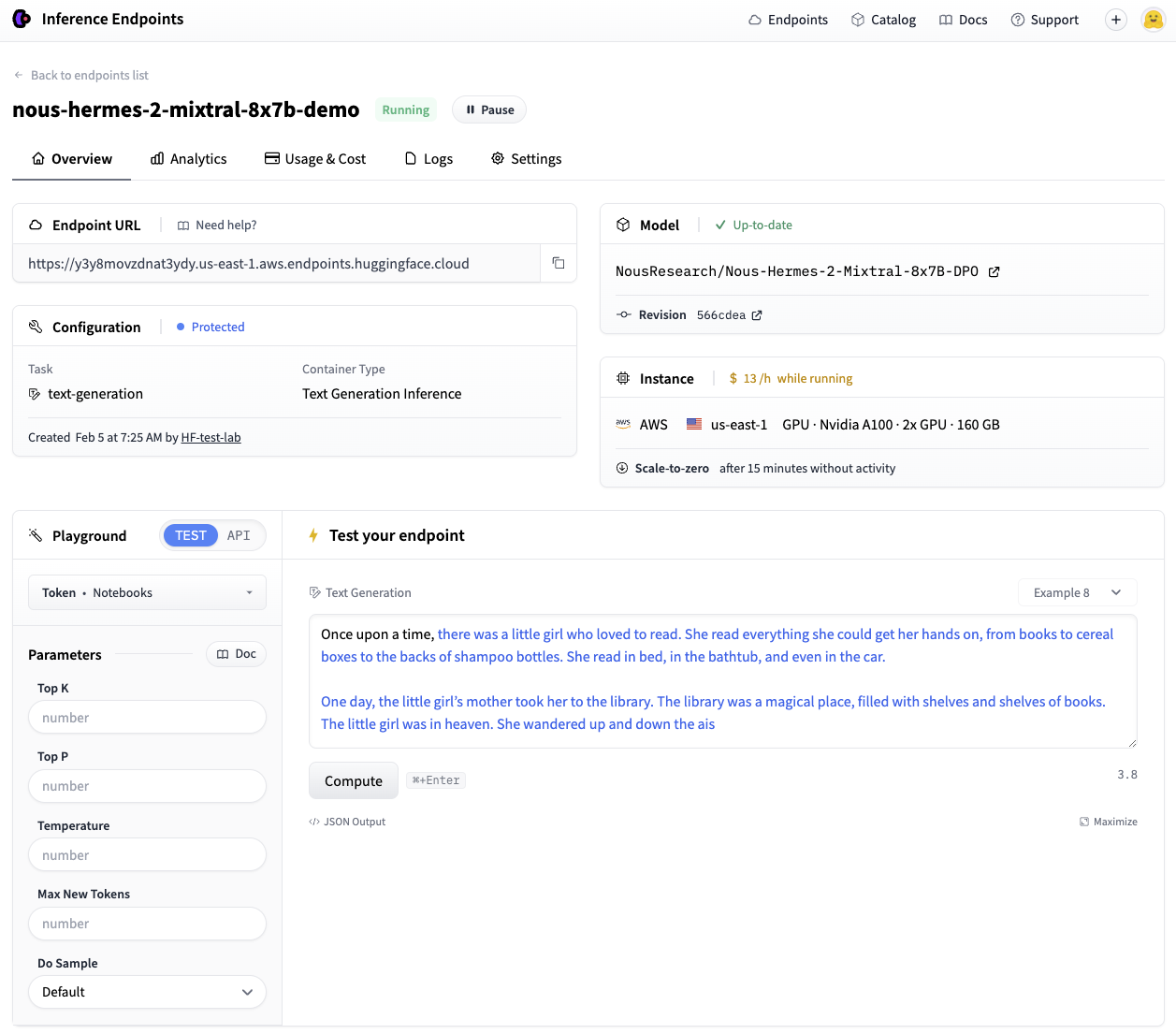
Great, we now have a working endpoint!
Note: When deploying with huggingface_hub, your endpoint will scale-to-zero after 15 minutes of idle time by default to optimize cost during periods of inactivity. Check out the Hub Python Library documentation to see all the functionality available for managing your endpoint lifecycle.
2. Query the Inference Endpoint with OpenAI Client Libraries
As mentioned above, since our model is hosted with TGI it now supports a Messages API meaning we can query it directly using the familiar OpenAI client libraries.
With the Python client
The example below shows how to make this transition using the OpenAI Python Library. Simply replace the <ENDPOINT_URL> with your endpoint URL (be sure to include the v1/ the suffix) and populate the <HF_API_KEY> field with a valid Hugging Face user token. The <ENDPOINT_URL> can be gathered from Inference Endpoints UI, or from the endpoint object we created above with endpoint.url.
We can then use the client as usual, passing a list of messages to stream responses from our Inference Endpoint.
>>> from openai import OpenAI
>>> BASE_URL = endpoint.url
>>> # init the client but point it to TGI
>>> client = OpenAI(
... base_url=os.path.join(BASE_URL, "v1/"),
... api_key=HF_API_KEY,
... )
>>> chat_completion = client.chat.completions.create(
... model="tgi",
... messages=[
... {"role": "system", "content": "You are a helpful assistant."},
... {"role": "user", "content": "Why is open-source software important?"},
... ],
... stream=True,
... max_tokens=500,
... )
>>> # iterate and print stream
>>> for message in chat_completion:
... print(message.choices[0].delta.content, end="")Open-source software is important due to a number of reasons, including: 1. Collaboration: The collaborative nature of open-source software allows developers from around the world to work together, share their ideas and improve the code. This often results in faster progress and better software. 2. Transparency: With open-source software, the code is publicly available, making it easy to see exactly how the software functions, and allowing users to determine if there are any security vulnerabilities. 3. Customization: Being able to access the code also allows users to customize the software to better suit their needs. This makes open-source software incredibly versatile, as users can tweak it to suit their specific use case. 4. Quality: Open-source software is often developed by large communities of dedicated developers, who work together to improve the software. This results in a higher level of quality than might be found in proprietary software. 5. Cost: Open-source software is often provided free of charge, which makes it accessible to a wider range of users. This can be especially important for organizations with limited budgets for software. 6. Shared Benefit: By sharing the code of open-source software, everyone can benefit from the hard work of the developers. This contributes to the overall advancement of technology, as users and developers work together to improve and build upon the software. In summary, open-source software provides a collaborative platform that leads to high-quality, customizable, and transparent software, all available at little or no cost, benefiting both individuals and the technology community as a whole.<|im_end|>
Behind the scenes, TGI’s Messages API automatically converts the list of messages into the model’s required instruction format using its chat template.
Note: Certain OpenAI features, like function calling, are not compatible with TGI. Currently, the Messages API supports the following chat completion parameters: stream, max_new_tokens, frequency_penalty, logprobs, seed, temperature, and top_p.
With the JavaScript client
Here’s the same streaming example above, but using the OpenAI Javascript/Typescript Library.
import OpenAI from "openai";
const openai = new OpenAI({
baseURL: "<ENDPOINT_URL>" + "/v1/", // replace with your endpoint url
apiKey: "<HF_API_TOKEN>", // replace with your token
});
async function main() {
const stream = await openai.chat.completions.create({
model: "tgi",
messages: [
{ role: "system", content: "You are a helpful assistant." },
{ role: "user", content: "Why is open-source software important?" },
],
stream: true,
max_tokens: 500,
});
for await (const chunk of stream) {
process.stdout.write(chunk.choices[0]?.delta?.content || "");
}
}
main();3. Integrate with LangChain and LlamaIndex
Now, let’s see how to use this newly created endpoint with popular RAG frameworks like LangChain and LlamaIndex.
How to use with LangChain
To use it in LangChain, simply create an instance of ChatOpenAI and pass your <ENDPOINT_URL> and <HF_API_TOKEN> as follows:
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(
model_name="tgi",
openai_api_key=HF_API_KEY,
openai_api_base=os.path.join(BASE_URL, "v1/"),
)
llm.invoke("Why is open-source software important?")We’re able to directly leverage the same ChatOpenAI class that we would have used with the OpenAI models. This allows all previous code to work with our endpoint by changing just one line of code.
Let’s now use our Mixtral model in a simple RAG pipeline to answer a question over the contents of a HF blog post.
from langchain import hub
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.document_loaders import WebBaseLoader
from langchain_community.vectorstores import Chroma
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
from langchain_core.runnables import RunnableParallel
from langchain_community.embeddings import HuggingFaceEmbeddings
# Load, chunk and index the contents of the blog
loader = WebBaseLoader(
web_paths=("https://huggingface.co/blog/open-source-llms-as-agents",),
)
docs = loader.load()
# declare an HF embedding model
hf_embeddings = HuggingFaceEmbeddings(model_name="BAAI/bge-large-en-v1.5")
text_splitter = RecursiveCharacterTextSplitter(chunk_size=512, chunk_overlap=200)
splits = text_splitter.split_documents(docs)
vectorstore = Chroma.from_documents(documents=splits, embedding=hf_embeddings)
# Retrieve and generate using the relevant snippets of the blog
retriever = vectorstore.as_retriever()
prompt = hub.pull("rlm/rag-prompt")
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
rag_chain_from_docs = (
RunnablePassthrough.assign(context=(lambda x: format_docs(x["context"])))
| prompt
| llm
| StrOutputParser()
)
rag_chain_with_source = RunnableParallel(
{"context": retriever, "question": RunnablePassthrough()}
).assign(answer=rag_chain_from_docs)
rag_chain_with_source.invoke(
"According to this article which open-source model is the best for an agent behaviour?"
)How to use with LlamaIndex
Similarly, you can also use a TGI endpoint in LlamaIndex. We’ll use the OpenAILike class, and instantiate it by configuring some additional arguments (i.e. is_local, is_function_calling_model, is_chat_model, context_window).
Note: that the context window argument should match the value previously set for MAX_TOTAL_TOKENS of your endpoint.
from llama_index.llms.openai_like import OpenAILike
llm = OpenAILike(
model="tgi",
api_key=HF_API_KEY,
api_base=BASE_URL + "/v1/",
is_chat_model=True,
is_local=False,
is_function_calling_model=False,
context_window=4096,
)
llm.complete("Why is open-source software important?")We can now use it in a similar RAG pipeline. Keep in mind that the previous choice of MAX_INPUT_LENGTH in your Inference Endpoint will directly influence the number of retrieved chunk (similarity_top_k) the model can process.
from llama_index.core import VectorStoreIndex, download_loader
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
from llama_index.core.query_engine import CitationQueryEngine
SimpleWebPageReader = download_loader("SimpleWebPageReader")
documents = SimpleWebPageReader(html_to_text=True).load_data(
["https://huggingface.co/blog/open-source-llms-as-agents"]
)
# Load embedding model
embed_model = HuggingFaceEmbedding(model_name="BAAI/bge-large-en-v1.5")
# Pass LLM to pipeline
index = VectorStoreIndex.from_documents(
documents, embed_model=embed_model, show_progress=True
)
# Query the index
query_engine = CitationQueryEngine.from_args(
index,
similarity_top_k=2,
)
response = query_engine.query(
"According to this article which open-source model is the best for an agent behaviour?"
)
response.responseWrap up
After you are done with your endpoint, you can either pause or delete it. This step can be completed via the UI, or programmatically like follows.
# pause our running endpoint
endpoint.pause()
# optionally delete
# endpoint.delete()