
Kandinsky 2.2
Collection
5 items
•
Updated
•
1
Kandinsky inherits best practices from Dall-E 2 and Latent diffusion while introducing some new ideas.
It uses the CLIP model as a text and image encoder, and diffusion image prior (mapping) between latent spaces of CLIP modalities. This approach increases the visual performance of the model and unveils new horizons in blending images and text-guided image manipulation.
The Kandinsky model is created by Arseniy Shakhmatov, Anton Razzhigaev, Aleksandr Nikolich, Igor Pavlov, Andrey Kuznetsov and Denis Dimitrov
Kandinsky 2.2 is available in diffusers!
pip install diffusers transformers accelerate
from diffusers import AutoPipelineForText2Image
import torch
pipe = AutoPipelineForText2Image.from_pretrained("kandinsky-community/kandinsky-2-2-decoder", torch_dtype=torch.float16)
pipe = pipe.to("cuda")
prompt = "portrait of a young women, blue eyes, cinematic"
negative_prompt = "low quality, bad quality"
image = pipe(prompt=prompt, negative_prompt=negative_prompt, prior_guidance_scale =1.0, height=768, width=768).images[0]
image.save("portrait.png")

from PIL import Image
import requests
from io import BytesIO
url = "https://raw.githubusercontent.com/CompVis/stable-diffusion/main/assets/stable-samples/img2img/sketch-mountains-input.jpg"
response = requests.get(url)
original_image = Image.open(BytesIO(response.content)).convert("RGB")
original_image = original_image.resize((768, 512))

from diffusers import AutoPipelineForImage2Image
import torch
pipe = AutoPipelineForImage2Image.from_pretrained("kandinsky-community/kandinsky-2-2-decoder", torch_dtype=torch.float16)
pipe.enable_model_cpu_offload()
prompt = "A fantasy landscape, Cinematic lighting"
negative_prompt = "low quality, bad quality"
image = pipe(prompt=prompt, image=original_image, strength=0.3, height=768, width=768).images[0]
out.images[0].save("fantasy_land.png")

from diffusers import KandinskyV22PriorPipeline, KandinskyV22Pipeline
from diffusers.utils import load_image
import PIL
import torch
pipe_prior = KandinskyV22PriorPipeline.from_pretrained(
"kandinsky-community/kandinsky-2-2-prior", torch_dtype=torch.float16
)
pipe_prior.to("cuda")
img1 = load_image(
"https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main" "/kandinsky/cat.png"
)
img2 = load_image(
"https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main" "/kandinsky/starry_night.jpeg"
)
# add all the conditions we want to interpolate, can be either text or image
images_texts = ["a cat", img1, img2]
# specify the weights for each condition in images_texts
weights = [0.3, 0.3, 0.4]
# We can leave the prompt empty
prompt = ""
prior_out = pipe_prior.interpolate(images_texts, weights)
pipe = KandinskyV22Pipeline.from_pretrained("kandinsky-community/kandinsky-2-2-decoder", torch_dtype=torch.float16)
pipe.to("cuda")
image = pipe(**prior_out, height=768, width=768).images[0]
image.save("starry_cat.png")

Kandinsky 2.2 is a text-conditional diffusion model based on unCLIP and latent diffusion, composed of a transformer-based image prior model, a unet diffusion model, and a decoder.
The model architectures are illustrated in the figure below - the chart on the left describes the process to train the image prior model, the figure in the center is the text-to-image generation process, and the figure on the right is image interpolation.
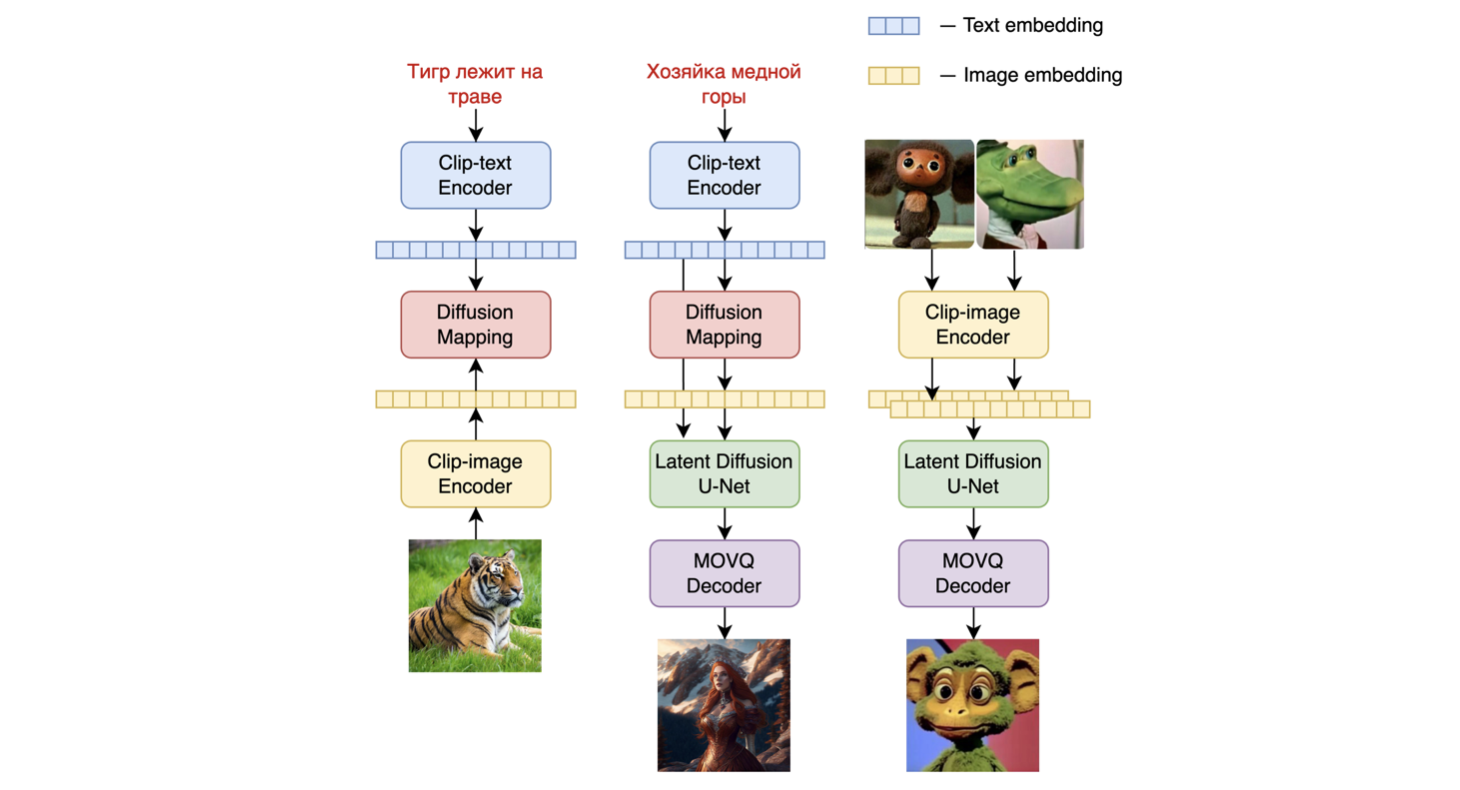
Specifically, the image prior model was trained on CLIP text and image embeddings generated with a pre-trained CLIP-ViT-G model. The trained image prior model is then used to generate CLIP image embeddings for input text prompts. Both the input text prompts and its CLIP image embeddings are used in the diffusion process. A MoVQGAN model acts as the final block of the model, which decodes the latent representation into an actual image.
The image prior training of the model was performed on the LAION Improved Aesthetics dataset, and then fine-tuning was performed on the LAION HighRes data.
The main Text2Image diffusion model was trained on LAION HighRes dataset and then fine-tuned with a dataset of 2M very high-quality high-resolution images with descriptions (COYO, anime, landmarks_russia, and a number of others) was used separately collected from open sources.
The main change in Kandinsky 2.2 is the replacement of CLIP-ViT-G. Its image encoder significantly increases the model's capability to generate more aesthetic pictures and better understand text, thus enhancing its overall performance.
Due to the switch CLIP model, the image prior model was retrained, and the Text2Image diffusion model was fine-tuned for 2000 iterations. Kandinsky 2.2 was trained on data of various resolutions, from 512 x 512 to 1536 x 1536, and also as different aspect ratios. As a result, Kandinsky 2.2 can generate 1024 x 1024 outputs with any aspect ratio.
We quantitatively measure the performance of Kandinsky 2.1 on the COCO_30k dataset, in zero-shot mode. The table below presents FID.
FID metric values for generative models on COCO_30k
| FID (30k) | |
|---|---|
| eDiff-I (2022) | 6.95 |
| Image (2022) | 7.27 |
| Kandinsky 2.1 (2023) | 8.21 |
| Stable Diffusion 2.1 (2022) | 8.59 |
| GigaGAN, 512x512 (2023) | 9.09 |
| DALL-E 2 (2022) | 10.39 |
| GLIDE (2022) | 12.24 |
| Kandinsky 1.0 (2022) | 15.40 |
| DALL-E (2021) | 17.89 |
| Kandinsky 2.0 (2022) | 20.00 |
| GLIGEN (2022) | 21.04 |
For more information, please refer to the upcoming technical report.
If you find this repository useful in your research, please cite:
@misc{kandinsky 2.2,
title = {kandinsky 2.2},
author = {Arseniy Shakhmatov, Anton Razzhigaev, Aleksandr Nikolich, Vladimir Arkhipkin, Igor Pavlov, Andrey Kuznetsov, Denis Dimitrov},
year = {2023},
howpublished = {},
}