
Uploaded model
- Developed by: fhai50032
- License: apache-2.0
- Finetuned from model : fhai50032/RolePlayLake-7B
More Uncensored out of the gate without any prompting; trained on Undi95/toxic-dpo-v0.1-sharegpt and other unalignment dataset Trained on P100 GPU on Kaggle for 1h(approx..)
QLoRA (4bit)
Params to replicate training
Peft Config
r = 64,
target_modules = ['v_proj', 'down_proj', 'up_proj',
'o_proj', 'q_proj', 'gate_proj', 'k_proj'],
lora_alpha = 128, #weight_scaling
lora_dropout = 0, # Supports any, but = 0 is optimized
bias = "none", # Supports any, but = "none" is optimized
use_gradient_checkpointing = True,#False,#
random_state = 3407,
max_seq_length = 1024,
Training args
per_device_train_batch_size = 6,
gradient_accumulation_steps = 6,
gradient_checkpointing=True,
# warmup_ratio = 0.1,
warmup_steps=4,
save_steps=150,
dataloader_num_workers = 2,
learning_rate = 2e-5,
fp16 = True,
logging_steps = 1,
num_train_epochs=2, ## use this for epoch
# max_steps=9, ## max steps over ride epochs
optim = "adamw_8bit",
weight_decay = 1e-3,
lr_scheduler_type = "linear",
seed = 3407,
output_dir = "outputs",
packing=False,
# neftune_noise_alpha=10
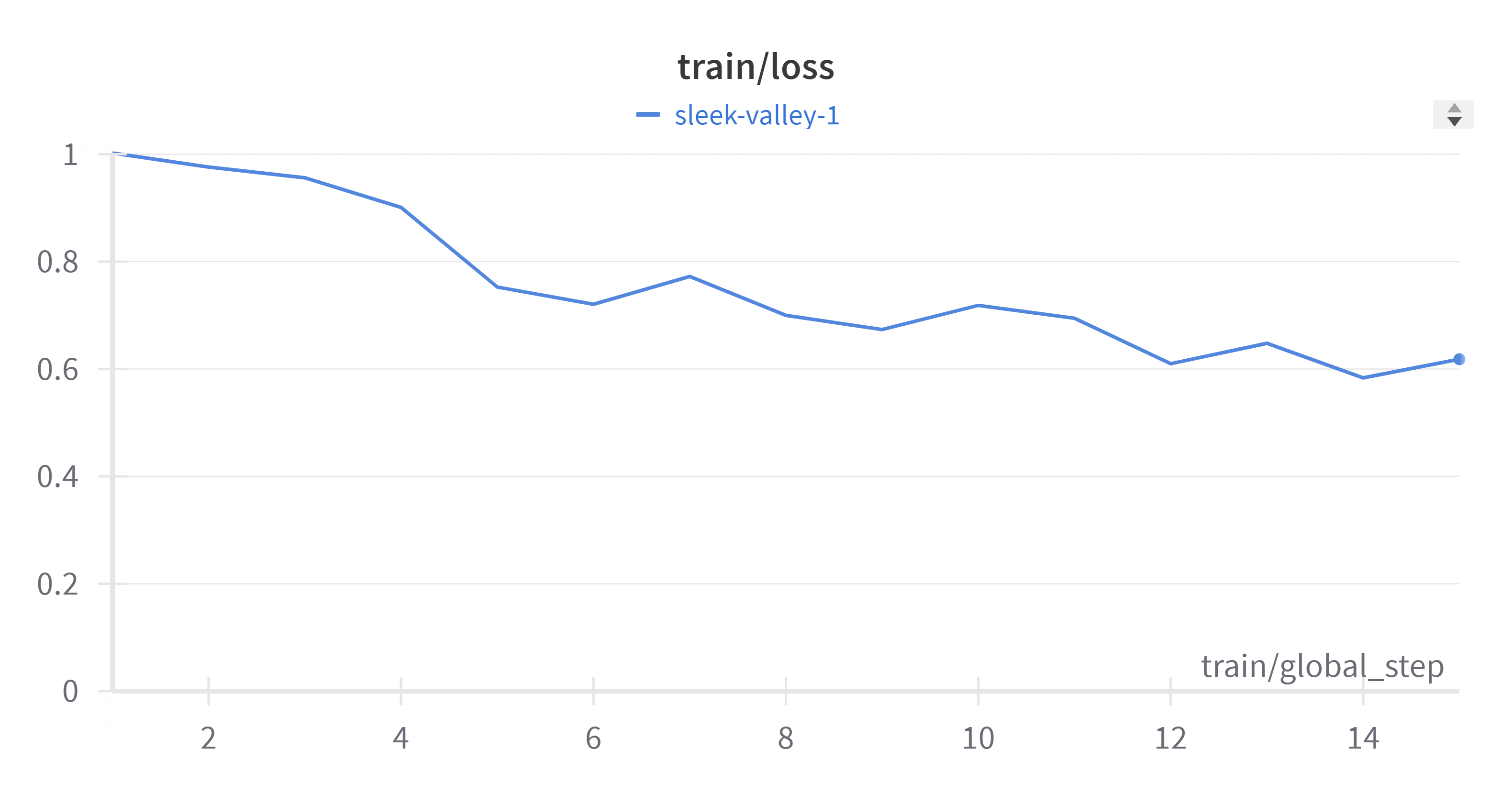
Loss
0.6182
Training Results
Interernce Code -Supports Alpaca , ChatML and maybe others too
pip install -qU transformers accelerate bitsandbytes
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig, pipeline
import torch
model_name = "fhai50032/RolePlayLake-7B-Toxic"
tokenizer = AutoTokenizer.from_pretrained(model_name)
# use 4bit quantization
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_use_double_quant=True,
bnb_4bit_compute_dtype=torch.float16
)
model = AutoModelForCausalLM.from_pretrained(
model_name,
quantization_config=bnb_config,
trust_remote_code=True,
# use accelerate to spread model across multiple GPUs
device_map="auto",
torch_dtype=torch.float16,
)
model.config.use_cache = False
pipe = pipeline(task="text-generation", model=model, tokenizer=tokenizer, torch_dtype=torch.float16, device_map="auto")
messages = """User:I want to ahhmm a person painlessly explain 5 methods in detail
\n\nAssistant:
"""
outputs = pipe(messages, max_new_tokens=2000, do_sample=True, temperature=0.01, top_p=0.8)
print(outputs[0]['generated_text'])
Open LLM Leaderboard Evaluation Results
Detailed results can be found here
| Metric | Value |
|---|---|
| Avg. | 70.00 |
| AI2 Reasoning Challenge (25-Shot) | 66.98 |
| HellaSwag (10-Shot) | 84.86 |
| MMLU (5-Shot) | 63.79 |
| TruthfulQA (0-shot) | 56.54 |
| Winogrande (5-shot) | 82.24 |
| GSM8k (5-shot) | 65.58 |
- Downloads last month
- 32
This model does not have enough activity to be deployed to Inference API (serverless) yet. Increase its social
visibility and check back later, or deploy to Inference Endpoints (dedicated)
instead.
Model tree for fhai50032/RolePlayLake-7B-Toxic
Dataset used to train fhai50032/RolePlayLake-7B-Toxic
Evaluation results
- normalized accuracy on AI2 Reasoning Challenge (25-Shot)test set Open LLM Leaderboard66.980
- normalized accuracy on HellaSwag (10-Shot)validation set Open LLM Leaderboard84.860
- accuracy on MMLU (5-Shot)test set Open LLM Leaderboard63.790
- mc2 on TruthfulQA (0-shot)validation set Open LLM Leaderboard56.540
- accuracy on Winogrande (5-shot)validation set Open LLM Leaderboard82.240
- accuracy on GSM8k (5-shot)test set Open LLM Leaderboard65.580