Transformers documentation
Perceiver
Perceiver
Overview
The Perceiver IO model was proposed in Perceiver IO: A General Architecture for Structured Inputs & Outputs by Andrew Jaegle, Sebastian Borgeaud, Jean-Baptiste Alayrac, Carl Doersch, Catalin Ionescu, David Ding, Skanda Koppula, Daniel Zoran, Andrew Brock, Evan Shelhamer, Olivier Hénaff, Matthew M. Botvinick, Andrew Zisserman, Oriol Vinyals, João Carreira.
Perceiver IO is a generalization of Perceiver to handle arbitrary outputs in addition to arbitrary inputs. The original Perceiver only produced a single classification label. In addition to classification labels, Perceiver IO can produce (for example) language, optical flow, and multimodal videos with audio. This is done using the same building blocks as the original Perceiver. The computational complexity of Perceiver IO is linear in the input and output size and the bulk of the processing occurs in the latent space, allowing us to process inputs and outputs that are much larger than can be handled by standard Transformers. This means, for example, Perceiver IO can do BERT-style masked language modeling directly using bytes instead of tokenized inputs.
The abstract from the paper is the following:
The recently-proposed Perceiver model obtains good results on several domains (images, audio, multimodal, point clouds) while scaling linearly in compute and memory with the input size. While the Perceiver supports many kinds of inputs, it can only produce very simple outputs such as class scores. Perceiver IO overcomes this limitation without sacrificing the original’s appealing properties by learning to flexibly query the model’s latent space to produce outputs of arbitrary size and semantics. Perceiver IO still decouples model depth from data size and still scales linearly with data size, but now with respect to both input and output sizes. The full Perceiver IO model achieves strong results on tasks with highly structured output spaces, such as natural language and visual understanding, StarCraft II, and multi-task and multi-modal domains. As highlights, Perceiver IO matches a Transformer-based BERT baseline on the GLUE language benchmark without the need for input tokenization and achieves state-of-the-art performance on Sintel optical flow estimation.
Here’s a TLDR explaining how Perceiver works:
The main problem with the self-attention mechanism of the Transformer is that the time and memory requirements scale quadratically with the sequence length. Hence, models like BERT and RoBERTa are limited to a max sequence length of 512 tokens. Perceiver aims to solve this issue by, instead of performing self-attention on the inputs, perform it on a set of latent variables, and only use the inputs for cross-attention. In this way, the time and memory requirements don’t depend on the length of the inputs anymore, as one uses a fixed amount of latent variables, like 256 or 512. These are randomly initialized, after which they are trained end-to-end using backpropagation.
Internally, PerceiverModel will create the latents, which is a tensor of shape (batch_size, num_latents, d_latents). One must provide inputs (which could be text, images, audio, you name it!) to the model, which it will
use to perform cross-attention with the latents. The output of the Perceiver encoder is a tensor of the same shape. One
can then, similar to BERT, convert the last hidden states of the latents to classification logits by averaging along
the sequence dimension, and placing a linear layer on top of that to project the d_latents to num_labels.
This was the idea of the original Perceiver paper. However, it could only output classification logits. In a follow-up work, PerceiverIO, they generalized it to let the model also produce outputs of arbitrary size. How, you might ask? The idea is actually relatively simple: one defines outputs of an arbitrary size, and then applies cross-attention with the last hidden states of the latents, using the outputs as queries, and the latents as keys and values.
So let’s say one wants to perform masked language modeling (BERT-style) with the Perceiver. As the Perceiver’s input
length will not have an impact on the computation time of the self-attention layers, one can provide raw bytes,
providing inputs of length 2048 to the model. If one now masks out certain of these 2048 tokens, one can define the
outputs as being of shape: (batch_size, 2048, 768). Next, one performs cross-attention with the final hidden states
of the latents to update the outputs tensor. After cross-attention, one still has a tensor of shape (batch_size, 2048, 768). One can then place a regular language modeling head on top, to project the last dimension to the
vocabulary size of the model, i.e. creating logits of shape (batch_size, 2048, 262) (as Perceiver uses a vocabulary
size of 262 byte IDs).
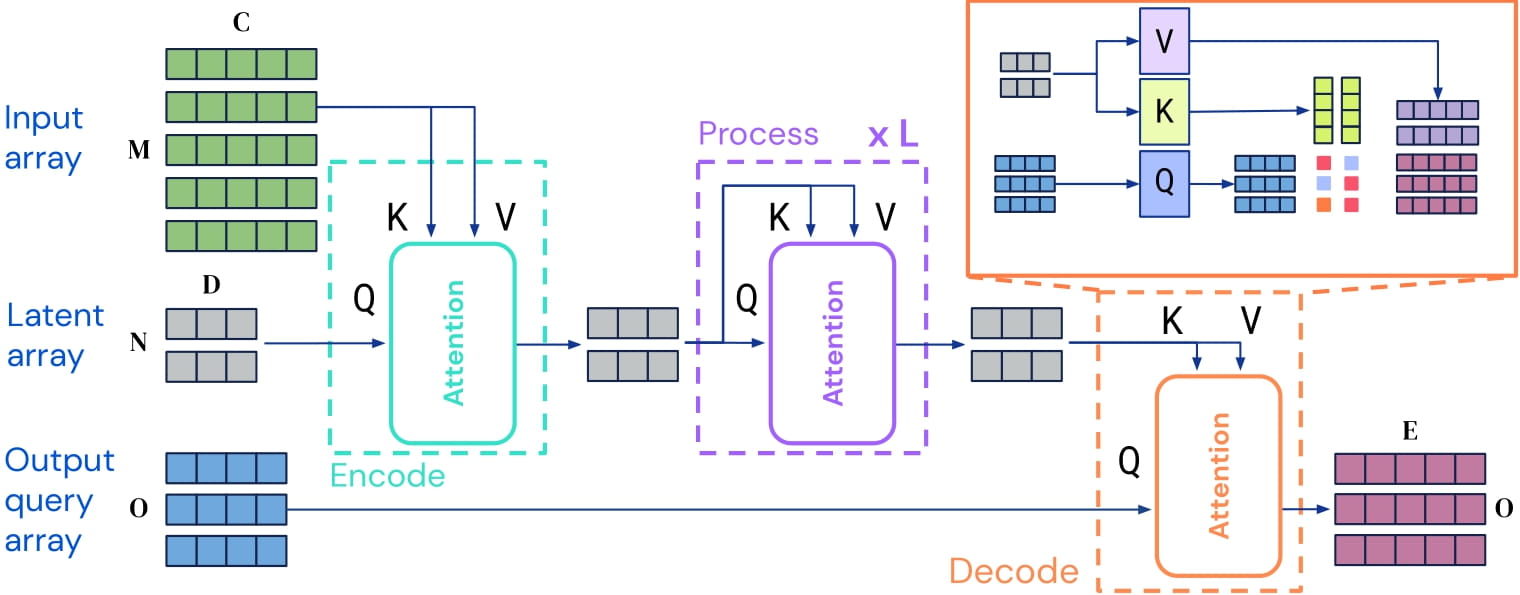 Perceiver IO architecture. Taken from the original paper
Perceiver IO architecture. Taken from the original paper This model was contributed by nielsr. The original code can be found here.
Perceiver does not work with torch.nn.DataParallel due to a bug in PyTorch, see issue #36035
Resources
- The quickest way to get started with the Perceiver is by checking the tutorial notebooks.
- Refer to the blog post if you want to fully understand how the model works and is implemented in the library. Note that the models available in the library only showcase some examples of what you can do with the Perceiver. There are many more use cases, including question answering, named-entity recognition, object detection, audio classification, video classification, etc.
- Text classification task guide
- Masked language modeling task guide
- Image classification task guide
Perceiver specific outputs
class transformers.models.perceiver.modeling_perceiver.PerceiverModelOutput
< source >( logits: FloatTensor = None last_hidden_state: FloatTensor = None hidden_states: Optional = None attentions: Optional = None cross_attentions: Optional = None )
Parameters
- logits (
torch.FloatTensorof shape(batch_size, num_labels)) — Classification (or regression if config.num_labels==1) scores (before SoftMax). - last_hidden_state (
torch.FloatTensorof shape(batch_size, sequence_length, hidden_size)) — Sequence of hidden-states at the output of the last layer of the model. - hidden_states (
tuple(torch.FloatTensor), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftorch.FloatTensor(one for the output of the embeddings + one for the output of each layer) of shape(batch_size, sequence_length, hidden_size). Hidden-states of the model at the output of each layer plus the initial embedding outputs. - attentions (
tuple(torch.FloatTensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftorch.FloatTensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length). Attentions weights after the attention softmax, used to compute the weighted average in the self-attention heads. - cross_attentions (
tuple(torch.FloatTensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftorch.FloatTensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length). Attentions weights of the decoder’s cross-attention layer, after the attention softmax, used to compute the weighted average in the cross-attention heads.
Base class for Perceiver base model’s outputs, with potential hidden states, attentions and cross-attentions.
class transformers.models.perceiver.modeling_perceiver.PerceiverDecoderOutput
< source >( logits: FloatTensor = None cross_attentions: Optional = None )
Parameters
- logits (
torch.FloatTensorof shape(batch_size, num_labels)) — Output of the basic decoder. - cross_attentions (
tuple(torch.FloatTensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftorch.FloatTensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length). Attentions weights of the decoder’s cross-attention layer, after the attention softmax, used to compute the weighted average in the cross-attention heads.
Base class for Perceiver decoder outputs, with potential cross-attentions.
class transformers.models.perceiver.modeling_perceiver.PerceiverMaskedLMOutput
< source >( loss: Optional = None logits: FloatTensor = None hidden_states: Optional = None attentions: Optional = None cross_attentions: Optional = None )
Parameters
- loss (
torch.FloatTensorof shape(1,), optional, returned whenlabelsis provided) — Masked language modeling (MLM) loss. - logits (
torch.FloatTensorof shape(batch_size, sequence_length, config.vocab_size)) — Prediction scores of the language modeling head (scores for each vocabulary token before SoftMax). - hidden_states (
tuple(torch.FloatTensor), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftorch.FloatTensor(one for the output of the embeddings + one for the output of each layer) of shape(batch_size, sequence_length, hidden_size). Hidden-states of the model at the output of each layer plus the initial embedding outputs. - attentions (
tuple(torch.FloatTensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftorch.FloatTensor(one for each layer) of shape(batch_size, num_heads, num_latents, num_latents). Attentions weights after the attention softmax, used to compute the weighted average in the self-attention heads. - cross_attentions (
tuple(torch.FloatTensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftorch.FloatTensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length). Attentions weights of the decoder’s cross-attention layer, after the attention softmax, used to compute the weighted average in the cross-attention heads.
Base class for Perceiver’s masked language model outputs.
class transformers.models.perceiver.modeling_perceiver.PerceiverClassifierOutput
< source >( loss: Optional = None logits: FloatTensor = None hidden_states: Optional = None attentions: Optional = None cross_attentions: Optional = None )
Parameters
- loss (
torch.FloatTensorof shape(1,), optional, returned whenlabelsis provided) — Classification (or regression if config.num_labels==1) loss. - logits (
torch.FloatTensorof shape(batch_size, config.num_labels)) — Classification (or regression if config.num_labels==1) scores (before SoftMax). - hidden_states (
tuple(torch.FloatTensor), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftorch.FloatTensor(one for the output of the embeddings + one for the output of each layer) of shape(batch_size, sequence_length, hidden_size). Hidden-states of the model at the output of each layer plus the initial embedding outputs. - attentions (
tuple(torch.FloatTensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftorch.FloatTensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length). Attentions weights after the attention softmax, used to compute the weighted average in the self-attention heads. - cross_attentions (
tuple(torch.FloatTensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftorch.FloatTensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length). Attentions weights of the decoder’s cross-attention layer, after the attention softmax, used to compute the weighted average in the cross-attention heads.
Base class for Perceiver’s outputs of sequence/image classification models, optical flow and multimodal autoencoding.
PerceiverConfig
class transformers.PerceiverConfig
< source >( num_latents = 256 d_latents = 1280 d_model = 768 num_blocks = 1 num_self_attends_per_block = 26 num_self_attention_heads = 8 num_cross_attention_heads = 8 qk_channels = None v_channels = None cross_attention_shape_for_attention = 'kv' self_attention_widening_factor = 1 cross_attention_widening_factor = 1 hidden_act = 'gelu' attention_probs_dropout_prob = 0.1 initializer_range = 0.02 layer_norm_eps = 1e-12 use_query_residual = True vocab_size = 262 max_position_embeddings = 2048 image_size = 56 train_size = [368, 496] num_frames = 16 audio_samples_per_frame = 1920 samples_per_patch = 16 output_shape = [1, 16, 224, 224] output_num_channels = 512 _label_trainable_num_channels = 1024 **kwargs )
Parameters
- num_latents (
int, optional, defaults to 256) — The number of latents. - d_latents (
int, optional, defaults to 1280) — Dimension of the latent embeddings. - d_model (
int, optional, defaults to 768) — Dimension of the inputs. Should only be provided in case [PerceiverTextPreprocessor] is used or no preprocessor is provided. - num_blocks (
int, optional, defaults to 1) — Number of blocks in the Transformer encoder. - num_self_attends_per_block (
int, optional, defaults to 26) — The number of self-attention layers per block. - num_self_attention_heads (
int, optional, defaults to 8) — Number of attention heads for each self-attention layer in the Transformer encoder. - num_cross_attention_heads (
int, optional, defaults to 8) — Number of attention heads for each cross-attention layer in the Transformer encoder. - qk_channels (
int, optional) — Dimension to project the queries + keys before applying attention in the cross-attention and self-attention layers of the encoder. Will default to preserving the dimension of the queries if not specified. - v_channels (
int, optional) — Dimension to project the values before applying attention in the cross-attention and self-attention layers of the encoder. Will default to preserving the dimension of the queries if not specified. - cross_attention_shape_for_attention (
str, optional, defaults to"kv") — Dimension to use when downsampling the queries and keys in the cross-attention layer of the encoder. - self_attention_widening_factor (
int, optional, defaults to 1) — Dimension of the feed-forward layer in the cross-attention layer of the Transformer encoder. - cross_attention_widening_factor (
int, optional, defaults to 1) — Dimension of the feed-forward layer in the self-attention layers of the Transformer encoder. - hidden_act (
strorfunction, optional, defaults to"gelu") — The non-linear activation function (function or string) in the encoder and pooler. If string,"gelu","relu","selu"and"gelu_new"are supported. - attention_probs_dropout_prob (
float, optional, defaults to 0.1) — The dropout ratio for the attention probabilities. - initializer_range (
float, optional, defaults to 0.02) — The standard deviation of the truncated_normal_initializer for initializing all weight matrices. - layer_norm_eps (
float, optional, defaults to 1e-12) — The epsilon used by the layer normalization layers. - use_query_residual (
float, optional, defaults toTrue) — Whether to add a query residual in the cross-attention layer of the encoder. - vocab_size (
int, optional, defaults to 262) — Vocabulary size for the masked language modeling model. - max_position_embeddings (
int, optional, defaults to 2048) — The maximum sequence length that the masked language modeling model might ever be used with. Typically set this to something large just in case (e.g., 512 or 1024 or 2048). - image_size (
int, optional, defaults to 56) — Size of the images after preprocessing, for PerceiverForImageClassificationLearned. - train_size (
List[int], optional, defaults to[368, 496]) — Training size of the images for the optical flow model. - num_frames (
int, optional, defaults to 16) — Number of video frames used for the multimodal autoencoding model. - audio_samples_per_frame (
int, optional, defaults to 1920) — Number of audio samples per frame for the multimodal autoencoding model. - samples_per_patch (
int, optional, defaults to 16) — Number of audio samples per patch when preprocessing the audio for the multimodal autoencoding model. - output_shape (
List[int], optional, defaults to[1, 16, 224, 224]) — Shape of the output (batch_size, num_frames, height, width) for the video decoder queries of the multimodal autoencoding model. This excludes the channel dimension. - output_num_channels (
int, optional, defaults to 512) — Number of output channels for each modalitiy decoder.
This is the configuration class to store the configuration of a PerceiverModel. It is used to instantiate an Perceiver model according to the specified arguments, defining the model architecture. Instantiating a configuration with the defaults will yield a similar configuration to that of the Perceiver deepmind/language-perceiver architecture.
Configuration objects inherit from PretrainedConfig and can be used to control the model outputs. Read the documentation from PretrainedConfig for more information.
Example:
>>> from transformers import PerceiverModel, PerceiverConfig
>>> # Initializing a Perceiver deepmind/language-perceiver style configuration
>>> configuration = PerceiverConfig()
>>> # Initializing a model from the deepmind/language-perceiver style configuration
>>> model = PerceiverModel(configuration)
>>> # Accessing the model configuration
>>> configuration = model.configPerceiverTokenizer
class transformers.PerceiverTokenizer
< source >( pad_token = '[PAD]' bos_token = '[BOS]' eos_token = '[EOS]' mask_token = '[MASK]' cls_token = '[CLS]' sep_token = '[SEP]' model_max_length = 2048 **kwargs )
Parameters
- pad_token (
str, optional, defaults to"[PAD]") — The token used for padding, for example when batching sequences of different lengths. - bos_token (
str, optional, defaults to"[BOS]") — The BOS token (reserved in the vocab, but not actually used). - eos_token (
str, optional, defaults to"[EOS]") — The end of sequence token (reserved in the vocab, but not actually used).When building a sequence using special tokens, this is not the token that is used for the end of sequence. The token used is the
sep_token. - mask_token (
str, optional, defaults to"[MASK]") — The MASK token, useful for masked language modeling. - cls_token (
str, optional, defaults to"[CLS]") — The CLS token (reserved in the vocab, but not actually used). - sep_token (
str, optional, defaults to"[SEP]") — The separator token, which is used when building a sequence from two sequences.
Construct a Perceiver tokenizer. The Perceiver simply uses raw bytes utf-8 encoding.
This tokenizer inherits from PreTrainedTokenizer which contains most of the main methods. Users should refer to this superclass for more information regarding those methods.
__call__
< source >( text: Union = None text_pair: Union = None text_target: Union = None text_pair_target: Union = None add_special_tokens: bool = True padding: Union = False truncation: Union = None max_length: Optional = None stride: int = 0 is_split_into_words: bool = False pad_to_multiple_of: Optional = None return_tensors: Union = None return_token_type_ids: Optional = None return_attention_mask: Optional = None return_overflowing_tokens: bool = False return_special_tokens_mask: bool = False return_offsets_mapping: bool = False return_length: bool = False verbose: bool = True **kwargs ) → BatchEncoding
Parameters
- text (
str,List[str],List[List[str]], optional) — The sequence or batch of sequences to be encoded. Each sequence can be a string or a list of strings (pretokenized string). If the sequences are provided as list of strings (pretokenized), you must setis_split_into_words=True(to lift the ambiguity with a batch of sequences). - text_pair (
str,List[str],List[List[str]], optional) — The sequence or batch of sequences to be encoded. Each sequence can be a string or a list of strings (pretokenized string). If the sequences are provided as list of strings (pretokenized), you must setis_split_into_words=True(to lift the ambiguity with a batch of sequences). - text_target (
str,List[str],List[List[str]], optional) — The sequence or batch of sequences to be encoded as target texts. Each sequence can be a string or a list of strings (pretokenized string). If the sequences are provided as list of strings (pretokenized), you must setis_split_into_words=True(to lift the ambiguity with a batch of sequences). - text_pair_target (
str,List[str],List[List[str]], optional) — The sequence or batch of sequences to be encoded as target texts. Each sequence can be a string or a list of strings (pretokenized string). If the sequences are provided as list of strings (pretokenized), you must setis_split_into_words=True(to lift the ambiguity with a batch of sequences). - add_special_tokens (
bool, optional, defaults toTrue) — Whether or not to add special tokens when encoding the sequences. This will use the underlyingPretrainedTokenizerBase.build_inputs_with_special_tokensfunction, which defines which tokens are automatically added to the input ids. This is usefull if you want to addbosoreostokens automatically. - padding (
bool,stror PaddingStrategy, optional, defaults toFalse) — Activates and controls padding. Accepts the following values:Trueor'longest': Pad to the longest sequence in the batch (or no padding if only a single sequence if provided).'max_length': Pad to a maximum length specified with the argumentmax_lengthor to the maximum acceptable input length for the model if that argument is not provided.Falseor'do_not_pad'(default): No padding (i.e., can output a batch with sequences of different lengths).
- truncation (
bool,stror TruncationStrategy, optional, defaults toFalse) — Activates and controls truncation. Accepts the following values:Trueor'longest_first': Truncate to a maximum length specified with the argumentmax_lengthor to the maximum acceptable input length for the model if that argument is not provided. This will truncate token by token, removing a token from the longest sequence in the pair if a pair of sequences (or a batch of pairs) is provided.'only_first': Truncate to a maximum length specified with the argumentmax_lengthor to the maximum acceptable input length for the model if that argument is not provided. This will only truncate the first sequence of a pair if a pair of sequences (or a batch of pairs) is provided.'only_second': Truncate to a maximum length specified with the argumentmax_lengthor to the maximum acceptable input length for the model if that argument is not provided. This will only truncate the second sequence of a pair if a pair of sequences (or a batch of pairs) is provided.Falseor'do_not_truncate'(default): No truncation (i.e., can output batch with sequence lengths greater than the model maximum admissible input size).
- max_length (
int, optional) — Controls the maximum length to use by one of the truncation/padding parameters.If left unset or set to
None, this will use the predefined model maximum length if a maximum length is required by one of the truncation/padding parameters. If the model has no specific maximum input length (like XLNet) truncation/padding to a maximum length will be deactivated. - stride (
int, optional, defaults to 0) — If set to a number along withmax_length, the overflowing tokens returned whenreturn_overflowing_tokens=Truewill contain some tokens from the end of the truncated sequence returned to provide some overlap between truncated and overflowing sequences. The value of this argument defines the number of overlapping tokens. - is_split_into_words (
bool, optional, defaults toFalse) — Whether or not the input is already pre-tokenized (e.g., split into words). If set toTrue, the tokenizer assumes the input is already split into words (for instance, by splitting it on whitespace) which it will tokenize. This is useful for NER or token classification. - pad_to_multiple_of (
int, optional) — If set will pad the sequence to a multiple of the provided value. Requirespaddingto be activated. This is especially useful to enable the use of Tensor Cores on NVIDIA hardware with compute capability>= 7.5(Volta). - return_tensors (
stror TensorType, optional) — If set, will return tensors instead of list of python integers. Acceptable values are:'tf': Return TensorFlowtf.constantobjects.'pt': Return PyTorchtorch.Tensorobjects.'np': Return Numpynp.ndarrayobjects.
- return_token_type_ids (
bool, optional) — Whether to return token type IDs. If left to the default, will return the token type IDs according to the specific tokenizer’s default, defined by thereturn_outputsattribute. - return_attention_mask (
bool, optional) — Whether to return the attention mask. If left to the default, will return the attention mask according to the specific tokenizer’s default, defined by thereturn_outputsattribute. - return_overflowing_tokens (
bool, optional, defaults toFalse) — Whether or not to return overflowing token sequences. If a pair of sequences of input ids (or a batch of pairs) is provided withtruncation_strategy = longest_firstorTrue, an error is raised instead of returning overflowing tokens. - return_special_tokens_mask (
bool, optional, defaults toFalse) — Whether or not to return special tokens mask information. - return_offsets_mapping (
bool, optional, defaults toFalse) — Whether or not to return(char_start, char_end)for each token.This is only available on fast tokenizers inheriting from PreTrainedTokenizerFast, if using Python’s tokenizer, this method will raise
NotImplementedError. - return_length (
bool, optional, defaults toFalse) — Whether or not to return the lengths of the encoded inputs. - verbose (
bool, optional, defaults toTrue) — Whether or not to print more information and warnings. **kwargs — passed to theself.tokenize()method
Returns
A BatchEncoding with the following fields:
-
input_ids — List of token ids to be fed to a model.
-
token_type_ids — List of token type ids to be fed to a model (when
return_token_type_ids=Trueor if “token_type_ids” is inself.model_input_names). -
attention_mask — List of indices specifying which tokens should be attended to by the model (when
return_attention_mask=Trueor if “attention_mask” is inself.model_input_names). -
overflowing_tokens — List of overflowing tokens sequences (when a
max_lengthis specified andreturn_overflowing_tokens=True). -
num_truncated_tokens — Number of tokens truncated (when a
max_lengthis specified andreturn_overflowing_tokens=True). -
special_tokens_mask — List of 0s and 1s, with 1 specifying added special tokens and 0 specifying regular sequence tokens (when
add_special_tokens=Trueandreturn_special_tokens_mask=True). -
length — The length of the inputs (when
return_length=True)
Main method to tokenize and prepare for the model one or several sequence(s) or one or several pair(s) of sequences.
PerceiverFeatureExtractor
Preprocess an image or a batch of images.
PerceiverImageProcessor
class transformers.PerceiverImageProcessor
< source >( do_center_crop: bool = True crop_size: Dict = None do_resize: bool = True size: Dict = None resample: Resampling = <Resampling.BICUBIC: 3> do_rescale: bool = True rescale_factor: Union = 0.00392156862745098 do_normalize: bool = True image_mean: Union = None image_std: Union = None **kwargs )
Parameters
- do_center_crop (
bool,optional, defaults toTrue) — Whether or not to center crop the image. If the input size if smaller thancrop_sizealong any edge, the image will be padded with zeros and then center cropped. Can be overridden by thedo_center_cropparameter in thepreprocessmethod. - crop_size (
Dict[str, int], optional, defaults to{"height" -- 256, "width": 256}): Desired output size when applying center-cropping. Can be overridden by thecrop_sizeparameter in thepreprocessmethod. - do_resize (
bool, optional, defaults toTrue) — Whether to resize the image to(size["height"], size["width"]). Can be overridden by thedo_resizeparameter in thepreprocessmethod. - size (
Dict[str, int]optional, defaults to{"height" -- 224, "width": 224}): Size of the image after resizing. Can be overridden by thesizeparameter in thepreprocessmethod. - resample (
PILImageResampling, optional, defaults toPILImageResampling.BICUBIC) — Defines the resampling filter to use if resizing the image. Can be overridden by theresampleparameter in thepreprocessmethod. - do_rescale (
bool, optional, defaults toTrue) — Whether to rescale the image by the specified scalerescale_factor. Can be overridden by thedo_rescaleparameter in thepreprocessmethod. - rescale_factor (
intorfloat, optional, defaults to1/255) — Defines the scale factor to use if rescaling the image. Can be overridden by therescale_factorparameter in thepreprocessmethod. do_normalize — Whether to normalize the image. Can be overridden by thedo_normalizeparameter in thepreprocessmethod. - image_mean (
floatorList[float], optional, defaults toIMAGENET_STANDARD_MEAN) — Mean to use if normalizing the image. This is a float or list of floats the length of the number of channels in the image. Can be overridden by theimage_meanparameter in thepreprocessmethod. - image_std (
floatorList[float], optional, defaults toIMAGENET_STANDARD_STD) — Standard deviation to use if normalizing the image. This is a float or list of floats the length of the number of channels in the image. Can be overridden by theimage_stdparameter in thepreprocessmethod.
Constructs a Perceiver image processor.
preprocess
< source >( images: Union do_center_crop: Optional = None crop_size: Optional = None do_resize: Optional = None size: Optional = None resample: Resampling = None do_rescale: Optional = None rescale_factor: Optional = None do_normalize: Optional = None image_mean: Union = None image_std: Union = None return_tensors: Union = None data_format: ChannelDimension = <ChannelDimension.FIRST: 'channels_first'> input_data_format: Union = None )
Parameters
- images (
ImageInput) — Image to preprocess. Expects a single or batch of images with pixel values ranging from 0 to 255. If passing in images with pixel values between 0 and 1, setdo_rescale=False. - do_center_crop (
bool, optional, defaults toself.do_center_crop) — Whether to center crop the image tocrop_size. - crop_size (
Dict[str, int], optional, defaults toself.crop_size) — Desired output size after applying the center crop. - do_resize (
bool, optional, defaults toself.do_resize) — Whether to resize the image. - size (
Dict[str, int], optional, defaults toself.size) — Size of the image after resizing. - resample (
int, optional, defaults toself.resample) — Resampling filter to use if resizing the image. This can be one of the enumPILImageResampling, Only has an effect ifdo_resizeis set toTrue. - do_rescale (
bool, optional, defaults toself.do_rescale) — Whether to rescale the image. - rescale_factor (
float, optional, defaults toself.rescale_factor) — Rescale factor to rescale the image by ifdo_rescaleis set toTrue. - do_normalize (
bool, optional, defaults toself.do_normalize) — Whether to normalize the image. - image_mean (
floatorList[float], optional, defaults toself.image_mean) — Image mean. - image_std (
floatorList[float], optional, defaults toself.image_std) — Image standard deviation. - return_tensors (
strorTensorType, optional) — The type of tensors to return. Can be one of:- Unset: Return a list of
np.ndarray. TensorType.TENSORFLOWor'tf': Return a batch of typetf.Tensor.TensorType.PYTORCHor'pt': Return a batch of typetorch.Tensor.TensorType.NUMPYor'np': Return a batch of typenp.ndarray.TensorType.JAXor'jax': Return a batch of typejax.numpy.ndarray.
- Unset: Return a list of
- data_format (
ChannelDimensionorstr, optional, defaults toChannelDimension.FIRST) — The channel dimension format for the output image. Can be one of:ChannelDimension.FIRST: image in (num_channels, height, width) format.ChannelDimension.LAST: image in (height, width, num_channels) format.
- input_data_format (
ChannelDimensionorstr, optional) — The channel dimension format for the input image. If unset, the channel dimension format is inferred from the input image. Can be one of:"channels_first"orChannelDimension.FIRST: image in (num_channels, height, width) format."channels_last"orChannelDimension.LAST: image in (height, width, num_channels) format."none"orChannelDimension.NONE: image in (height, width) format.
Preprocess an image or batch of images.
PerceiverTextPreprocessor
class transformers.models.perceiver.modeling_perceiver.PerceiverTextPreprocessor
< source >( config: PerceiverConfig )
Parameters
- config (PerceiverConfig) — Model configuration.
Text preprocessing for Perceiver Encoder. Can be used to embed inputs and add positional encodings.
The dimensionality of the embeddings is determined by the d_model attribute of the configuration.
PerceiverImagePreprocessor
class transformers.models.perceiver.modeling_perceiver.PerceiverImagePreprocessor
< source >( config prep_type = 'conv' spatial_downsample: int = 4 temporal_downsample: int = 1 position_encoding_type: str = 'fourier' in_channels: int = 3 out_channels: int = 64 conv_after_patching: bool = False conv_after_patching_in_channels: int = 54 conv2d_use_batchnorm: bool = True concat_or_add_pos: str = 'concat' project_pos_dim: int = -1 **position_encoding_kwargs )
Parameters
- config ([PerceiverConfig]) — Model configuration.
- prep_type (
str, optional, defaults to"conv") — Preprocessing type. Can be “conv1x1”, “conv”, “patches”, “pixels”. - spatial_downsample (
int, optional, defaults to 4) — Spatial downsampling factor. - temporal_downsample (
int, optional, defaults to 1) — Temporal downsampling factor (only relevant in case a time dimension is present). - position_encoding_type (
str, optional, defaults to"fourier") — Position encoding type. Can be “fourier” or “trainable”. - in_channels (
int, optional, defaults to 3) — Number of channels in the input. - out_channels (
int, optional, defaults to 64) — Number of channels in the output. - conv_after_patching (
bool, optional, defaults toFalse) — Whether to apply a convolutional layer after patching. - conv_after_patching_in_channels (
int, optional, defaults to 54) — Number of channels in the input of the convolutional layer after patching. - conv2d_use_batchnorm (
bool, optional, defaults toTrue) — Whether to use batch normalization in the convolutional layer. - concat_or_add_pos (
str, optional, defaults to"concat") — How to concatenate the position encoding to the input. Can be “concat” or “add”. - project_pos_dim (
int, optional, defaults to -1) — Dimension of the position encoding to project to. If -1, no projection is applied. - **position_encoding_kwargs (
Dict, optional) — Keyword arguments for the position encoding.
Image preprocessing for Perceiver Encoder.
Note: the out_channels argument refers to the output channels of a convolutional layer, if prep_type is set to “conv1x1” or “conv”. If one adds absolute position embeddings, one must make sure the num_channels of the position encoding kwargs are set equal to the out_channels.
PerceiverOneHotPreprocessor
class transformers.models.perceiver.modeling_perceiver.PerceiverOneHotPreprocessor
< source >( config: PerceiverConfig )
Parameters
- config (PerceiverConfig) — Model configuration.
One-hot preprocessor for Perceiver Encoder. Can be used to add a dummy index dimension to the input.
PerceiverAudioPreprocessor
class transformers.models.perceiver.modeling_perceiver.PerceiverAudioPreprocessor
< source >( config prep_type: str = 'patches' samples_per_patch: int = 96 position_encoding_type: str = 'fourier' concat_or_add_pos: str = 'concat' out_channels = 64 project_pos_dim = -1 **position_encoding_kwargs )
Parameters
- config ([PerceiverConfig]) — Model configuration.
- prep_type (
str, optional, defaults to"patches") — Preprocessor type to use. Only “patches” is supported. - samples_per_patch (
int, optional, defaults to 96) — Number of samples per patch. - position_encoding_type (
str, optional, defaults to"fourier") — Type of position encoding to use. Can be “trainable” or “fourier”. - concat_or_add_pos (
str, optional, defaults to"concat") — How to concatenate the position encoding to the input. Can be “concat” or “add”. - out_channels (
int, optional, defaults to 64) — Number of channels in the output. - project_pos_dim (
int, optional, defaults to -1) — Dimension of the position encoding to project to. If -1, no projection is applied. - **position_encoding_kwargs (
Dict, optional) — Keyword arguments for the position encoding.
Audio preprocessing for Perceiver Encoder.
PerceiverMultimodalPreprocessor
class transformers.models.perceiver.modeling_perceiver.PerceiverMultimodalPreprocessor
< source >( modalities: Mapping mask_probs: Optional = None min_padding_size: int = 2 )
Parameters
- modalities (
Mapping[str, PreprocessorType]) — Dict mapping modality name to preprocessor. - mask_probs (
Dict[str, float]) — Dict mapping modality name to masking probability of that modality. - min_padding_size (
int, optional, defaults to 2) — The minimum padding size for all modalities. The final output will have num_channels equal to the maximum channels across all modalities plus min_padding_size.
Multimodal preprocessing for Perceiver Encoder.
Inputs for each modality are preprocessed, then padded with trainable position embeddings to have the same number of channels.
PerceiverProjectionDecoder
class transformers.models.perceiver.modeling_perceiver.PerceiverProjectionDecoder
< source >( config )
Parameters
- config (PerceiverConfig) — Model configuration.
Baseline projection decoder (no cross-attention).
PerceiverBasicDecoder
class transformers.models.perceiver.modeling_perceiver.PerceiverBasicDecoder
< source >( config: PerceiverConfig output_num_channels: int position_encoding_type: Optional = 'trainable' output_index_dims: Optional = None num_channels: Optional = 128 subsampled_index_dims: Optional = None qk_channels: Optional = None v_channels: Optional = None num_heads: Optional = 1 widening_factor: Optional = 1 use_query_residual: Optional = False concat_preprocessed_input: Optional = False final_project: Optional = True position_encoding_only: Optional = False **position_encoding_kwargs )
Parameters
- config ([PerceiverConfig]) — Model configuration.
- output_num_channels (
int, optional) — The number of channels in the output. Will only be used in case final_project is set toTrue. - position_encoding_type (
str, optional, defaults to “trainable”) — The type of position encoding to use. Can be either “trainable”, “fourier”, or “none”. - output_index_dims (
int, optional) — The number of dimensions of the output queries. Ignored if ‘position_encoding_type’ == ‘none’. - num_channels (
int, optional, defaults to 128) — The number of channels of the decoder queries. Ignored if ‘position_encoding_type’ == ‘none’. - qk_channels (
int, optional) — The number of channels of the queries and keys in the cross-attention layer. - v_channels (
int, optional) — The number of channels of the values in the cross-attention layer. - num_heads (
int, optional, defaults to 1) — The number of attention heads in the cross-attention layer. - widening_factor (
int, optional, defaults to 1) — The widening factor of the cross-attention layer. - use_query_residual (
bool, optional, defaults toFalse) — Whether to use a residual connection between the query and the output of the cross-attention layer. - concat_preprocessed_input (
bool, optional, defaults toFalse) — Whether to concatenate the preprocessed input to the query. - final_project (
bool, optional, defaults toTrue) — Whether to project the output of the cross-attention layer to a target dimension. - position_encoding_only (
bool, optional, defaults toFalse) — Whether to only use this class to define output queries.
Cross-attention-based decoder. This class can be used to decode the final hidden states of the latents using a cross-attention operation, in which the latents produce keys and values.
The shape of the output of this class depends on how one defines the output queries (also called decoder queries).
PerceiverClassificationDecoder
class transformers.models.perceiver.modeling_perceiver.PerceiverClassificationDecoder
< source >( config **decoder_kwargs )
Parameters
- config (PerceiverConfig) — Model configuration.
Cross-attention based classification decoder. Light-weight wrapper of PerceiverBasicDecoder for logit output.
Will turn the output of the Perceiver encoder which is of shape (batch_size, num_latents, d_latents) to a tensor of
shape (batch_size, num_labels). The queries are of shape (batch_size, 1, num_labels).
PerceiverOpticalFlowDecoder
class transformers.models.perceiver.modeling_perceiver.PerceiverOpticalFlowDecoder
< source >( config output_image_shape output_num_channels = 2 rescale_factor = 100.0 **decoder_kwargs )
Cross-attention based optical flow decoder.
PerceiverBasicVideoAutoencodingDecoder
class transformers.models.perceiver.modeling_perceiver.PerceiverBasicVideoAutoencodingDecoder
< source >( config: PerceiverConfig output_shape: List position_encoding_type: str **decoder_kwargs )
Parameters
Cross-attention based video-autoencoding decoder. Light-weight wrapper of [PerceiverBasicDecoder] with video reshaping logic.
PerceiverMultimodalDecoder
class transformers.models.perceiver.modeling_perceiver.PerceiverMultimodalDecoder
< source >( config: PerceiverConfig modalities: Dict num_outputs: int output_num_channels: int min_padding_size: Optional = 2 subsampled_index_dims: Optional = None **decoder_kwargs )
Parameters
- config ([PerceiverConfig]) — Model configuration.
- modalities (
Dict[str, PerceiverAbstractDecoder]) — Dictionary mapping modality name to the decoder of that modality. - num_outputs (
int) — The number of outputs of the decoder. - output_num_channels (
int) — The number of channels in the output. - min_padding_size (
int, optional, defaults to 2) — The minimum padding size for all modalities. The final output will have num_channels equal to the maximum channels across all modalities plus min_padding_size. - subsampled_index_dims (
Dict[str, PerceiverAbstractDecoder], optional) — Dictionary mapping modality name to the subsampled index dimensions to use for the decoder query of that modality.
Multimodal decoding by composing uni-modal decoders. The modalities argument of the constructor is a dictionary mapping modality name to the decoder of that modality. That decoder will be used to construct queries for that modality. Modality-specific queries are padded with trainable modality-specific parameters, after which they are concatenated along the time dimension.
Next, there is a shared cross attention operation across all modalities.
PerceiverProjectionPostprocessor
class transformers.models.perceiver.modeling_perceiver.PerceiverProjectionPostprocessor
< source >( in_channels: int out_channels: int )
Projection postprocessing for Perceiver. Can be used to project the channels of the decoder output to a lower dimension.
PerceiverAudioPostprocessor
class transformers.models.perceiver.modeling_perceiver.PerceiverAudioPostprocessor
< source >( config: PerceiverConfig in_channels: int postproc_type: str = 'patches' )
Audio postprocessing for Perceiver. Can be used to convert the decoder output to audio features.
PerceiverClassificationPostprocessor
class transformers.models.perceiver.modeling_perceiver.PerceiverClassificationPostprocessor
< source >( config: PerceiverConfig in_channels: int )
Classification postprocessing for Perceiver. Can be used to convert the decoder output to classification logits.
PerceiverMultimodalPostprocessor
class transformers.models.perceiver.modeling_perceiver.PerceiverMultimodalPostprocessor
< source >( modalities: Mapping input_is_dict: bool = False )
Parameters
- modalities (
Mapping[str, PostprocessorType]) — Dictionary mapping modality name to postprocessor class for that modality. - input_is_dict (
bool, optional, defaults toFalse) — If True, input is assumed to be dictionary structured, and outputs keep the same dictionary shape. If False, input is a tensor which is sliced up during postprocessing by modality_sizes.
Multimodal postprocessing for Perceiver. Can be used to combine modality-specific postprocessors into a single postprocessor.
PerceiverModel
class transformers.PerceiverModel
< source >( config decoder = None input_preprocessor: Callable = None output_postprocessor: Callable = None )
Parameters
- config (PerceiverConfig) — Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out the from_pretrained() method to load the model weights.
- decoder (DecoderType, optional) — Optional decoder to use to decode the latent representation of the encoder. Examples include transformers.models.perceiver.modeling_perceiver.PerceiverBasicDecoder, transformers.models.perceiver.modeling_perceiver.PerceiverClassificationDecoder, transformers.models.perceiver.modeling_perceiver.PerceiverMultimodalDecoder.
- input_preprocessor (PreprocessorType, optional) — Optional input preprocessor to use. Examples include transformers.models.perceiver.modeling_perceiver.PerceiverImagePreprocessor, transformers.models.perceiver.modeling_perceiver.PerceiverAudioPreprocessor, transformers.models.perceiver.modeling_perceiver.PerceiverTextPreprocessor, transformers.models.perceiver.modeling_perceiver.PerceiverMultimodalPreprocessor.
- output_postprocessor (PostprocessorType, optional) — Optional output postprocessor to use. Examples include transformers.models.perceiver.modeling_perceiver.PerceiverImagePostprocessor, transformers.models.perceiver.modeling_perceiver.PerceiverAudioPostprocessor, transformers.models.perceiver.modeling_perceiver.PerceiverClassificationPostprocessor, transformers.models.perceiver.modeling_perceiver.PerceiverProjectionPostprocessor, transformers.models.perceiver.modeling_perceiver.PerceiverMultimodalPostprocessor.
- Note that you can define your own decoders, preprocessors and/or postprocessors to fit your use-case. —
The Perceiver: a scalable, fully attentional architecture.
Note that it’s possible to fine-tune Perceiver on higher resolution images than the ones it has been trained on, by
setting interpolate_pos_encoding to True in the forward of the model. This will interpolate the pre-trained
position embeddings to the higher resolution.
This model is a PyTorch torch.nn.Module sub-class. Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and behavior.
forward
< source >( inputs: FloatTensor attention_mask: Optional = None subsampled_output_points: Optional = None head_mask: Optional = None output_attentions: Optional = None output_hidden_states: Optional = None interpolate_pos_encoding: bool = False return_dict: Optional = None ) → transformers.models.perceiver.modeling_perceiver.PerceiverModelOutput or tuple(torch.FloatTensor)
Parameters
- inputs (
torch.FloatTensor) — Inputs to the perceiver. Can be anything: images, text, audio, video, etc. - attention_mask (
torch.FloatTensorof shape(batch_size, sequence_length), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
- head_mask (
torch.FloatTensorof shape(num_heads,)or(num_layers, num_heads), optional) — Mask to nullify selected heads of the self-attention modules. Mask values selected in[0, 1]:- 1 indicates the head is not masked,
- 0 indicates the head is masked.
- output_attentions (
bool, optional) — Whether or not to return the attentions tensors of all attention layers. Seeattentionsunder returned tensors for more detail. - output_hidden_states (
bool, optional) — Whether or not to return the hidden states of all layers. Seehidden_statesunder returned tensors for more detail. - interpolate_pos_encoding (
bool, optional, defaults toFalse) — Whether to interpolate the pre-trained position encodings. - return_dict (
bool, optional) — Whether or not to return a ModelOutput instead of a plain tuple.
Returns
transformers.models.perceiver.modeling_perceiver.PerceiverModelOutput or tuple(torch.FloatTensor)
A transformers.models.perceiver.modeling_perceiver.PerceiverModelOutput or a tuple of
torch.FloatTensor (if return_dict=False is passed or when config.return_dict=False) comprising various
elements depending on the configuration (PerceiverConfig) and inputs.
- logits (
torch.FloatTensorof shape(batch_size, num_labels)) — Classification (or regression if config.num_labels==1) scores (before SoftMax). - last_hidden_state (
torch.FloatTensorof shape(batch_size, sequence_length, hidden_size)) — Sequence of hidden-states at the output of the last layer of the model. - hidden_states (
tuple(torch.FloatTensor), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftorch.FloatTensor(one for the output of the embeddings + one for the output of each layer) of shape(batch_size, sequence_length, hidden_size). Hidden-states of the model at the output of each layer plus the initial embedding outputs. - attentions (
tuple(torch.FloatTensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftorch.FloatTensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length). Attentions weights after the attention softmax, used to compute the weighted average in the self-attention heads. - cross_attentions (
tuple(torch.FloatTensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftorch.FloatTensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length). Attentions weights of the decoder’s cross-attention layer, after the attention softmax, used to compute the weighted average in the cross-attention heads.
The PerceiverModel forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the Module
instance afterwards instead of this since the former takes care of running the pre and post processing steps while
the latter silently ignores them.
Examples:
>>> from transformers import PerceiverConfig, PerceiverTokenizer, PerceiverImageProcessor, PerceiverModel
>>> from transformers.models.perceiver.modeling_perceiver import (
... PerceiverTextPreprocessor,
... PerceiverImagePreprocessor,
... PerceiverClassificationDecoder,
... )
>>> import torch
>>> import requests
>>> from PIL import Image
>>> # EXAMPLE 1: using the Perceiver to classify texts
>>> # - we define a TextPreprocessor, which can be used to embed tokens
>>> # - we define a ClassificationDecoder, which can be used to decode the
>>> # final hidden states of the latents to classification logits
>>> # using trainable position embeddings
>>> config = PerceiverConfig()
>>> preprocessor = PerceiverTextPreprocessor(config)
>>> decoder = PerceiverClassificationDecoder(
... config,
... num_channels=config.d_latents,
... trainable_position_encoding_kwargs=dict(num_channels=config.d_latents, index_dims=1),
... use_query_residual=True,
... )
>>> model = PerceiverModel(config, input_preprocessor=preprocessor, decoder=decoder)
>>> # you can then do a forward pass as follows:
>>> tokenizer = PerceiverTokenizer()
>>> text = "hello world"
>>> inputs = tokenizer(text, return_tensors="pt").input_ids
>>> with torch.no_grad():
... outputs = model(inputs=inputs)
>>> logits = outputs.logits
>>> list(logits.shape)
[1, 2]
>>> # to train, one can train the model using standard cross-entropy:
>>> criterion = torch.nn.CrossEntropyLoss()
>>> labels = torch.tensor([1])
>>> loss = criterion(logits, labels)
>>> # EXAMPLE 2: using the Perceiver to classify images
>>> # - we define an ImagePreprocessor, which can be used to embed images
>>> config = PerceiverConfig(image_size=224)
>>> preprocessor = PerceiverImagePreprocessor(
... config,
... prep_type="conv1x1",
... spatial_downsample=1,
... out_channels=256,
... position_encoding_type="trainable",
... concat_or_add_pos="concat",
... project_pos_dim=256,
... trainable_position_encoding_kwargs=dict(
... num_channels=256,
... index_dims=config.image_size**2,
... ),
... )
>>> model = PerceiverModel(
... config,
... input_preprocessor=preprocessor,
... decoder=PerceiverClassificationDecoder(
... config,
... num_channels=config.d_latents,
... trainable_position_encoding_kwargs=dict(num_channels=config.d_latents, index_dims=1),
... use_query_residual=True,
... ),
... )
>>> # you can then do a forward pass as follows:
>>> image_processor = PerceiverImageProcessor()
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> inputs = image_processor(image, return_tensors="pt").pixel_values
>>> with torch.no_grad():
... outputs = model(inputs=inputs)
>>> logits = outputs.logits
>>> list(logits.shape)
[1, 2]
>>> # to train, one can train the model using standard cross-entropy:
>>> criterion = torch.nn.CrossEntropyLoss()
>>> labels = torch.tensor([1])
>>> loss = criterion(logits, labels)PerceiverForMaskedLM
class transformers.PerceiverForMaskedLM
< source >( config: PerceiverConfig )
Parameters
- config (PerceiverConfig) — Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out the from_pretrained() method to load the model weights.
Example use of Perceiver for masked language modeling. This model is a PyTorch torch.nn.Module sub-class. Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and behavior.
forward
< source >( inputs: Optional = None attention_mask: Optional = None head_mask: Optional = None output_attentions: Optional = None output_hidden_states: Optional = None labels: Optional = None return_dict: Optional = None input_ids: Optional = None ) → transformers.models.perceiver.modeling_perceiver.PerceiverMaskedLMOutput or tuple(torch.FloatTensor)
Parameters
- inputs (
torch.FloatTensor) — Inputs to the perceiver. Can be anything: images, text, audio, video, etc. - attention_mask (
torch.FloatTensorof shapebatch_size, sequence_length, optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
- head_mask (
torch.FloatTensorof shape(num_heads,)or(num_layers, num_heads), optional) — Mask to nullify selected heads of the self-attention modules. Mask values selected in[0, 1]:- 1 indicates the head is not masked,
- 0 indicates the head is masked.
- output_attentions (
bool, optional) — Whether or not to return the attentions tensors of all attention layers. Seeattentionsunder returned tensors for more detail. - output_hidden_states (
bool, optional) — Whether or not to return the hidden states of all layers. Seehidden_statesunder returned tensors for more detail. - interpolate_pos_encoding (
bool, optional, defaults toFalse) — Whether to interpolate the pre-trained position encodings. - return_dict (
bool, optional) — Whether or not to return a ModelOutput instead of a plain tuple. - labels (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Labels for computing the masked language modeling loss. Indices should be in[-100, 0, ..., config.vocab_size](seeinput_idsdocstring) Tokens with indices set to-100are ignored (masked), the loss is only computed for the tokens with labels in[0, ..., config.vocab_size]
Returns
transformers.models.perceiver.modeling_perceiver.PerceiverMaskedLMOutput or tuple(torch.FloatTensor)
A transformers.models.perceiver.modeling_perceiver.PerceiverMaskedLMOutput or a tuple of
torch.FloatTensor (if return_dict=False is passed or when config.return_dict=False) comprising various
elements depending on the configuration (PerceiverConfig) and inputs.
- loss (
torch.FloatTensorof shape(1,), optional, returned whenlabelsis provided) — Masked language modeling (MLM) loss. - logits (
torch.FloatTensorof shape(batch_size, sequence_length, config.vocab_size)) — Prediction scores of the language modeling head (scores for each vocabulary token before SoftMax). - hidden_states (
tuple(torch.FloatTensor), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftorch.FloatTensor(one for the output of the embeddings + one for the output of each layer) of shape(batch_size, sequence_length, hidden_size). Hidden-states of the model at the output of each layer plus the initial embedding outputs. - attentions (
tuple(torch.FloatTensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftorch.FloatTensor(one for each layer) of shape(batch_size, num_heads, num_latents, num_latents). Attentions weights after the attention softmax, used to compute the weighted average in the self-attention heads. - cross_attentions (
tuple(torch.FloatTensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftorch.FloatTensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length). Attentions weights of the decoder’s cross-attention layer, after the attention softmax, used to compute the weighted average in the cross-attention heads.
The PerceiverForMaskedLM forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the Module
instance afterwards instead of this since the former takes care of running the pre and post processing steps while
the latter silently ignores them.
Examples:
>>> from transformers import AutoTokenizer, PerceiverForMaskedLM
>>> import torch
>>> tokenizer = AutoTokenizer.from_pretrained("deepmind/language-perceiver")
>>> model = PerceiverForMaskedLM.from_pretrained("deepmind/language-perceiver")
>>> # training
>>> text = "This is an incomplete sentence where some words are missing."
>>> inputs = tokenizer(text, padding="max_length", return_tensors="pt")
>>> # mask " missing."
>>> inputs["input_ids"][0, 52:61] = tokenizer.mask_token_id
>>> labels = tokenizer(text, padding="max_length", return_tensors="pt").input_ids
>>> outputs = model(**inputs, labels=labels)
>>> loss = outputs.loss
>>> round(loss.item(), 2)
19.87
>>> logits = outputs.logits
>>> list(logits.shape)
[1, 2048, 262]
>>> # inference
>>> text = "This is an incomplete sentence where some words are missing."
>>> encoding = tokenizer(text, padding="max_length", return_tensors="pt")
>>> # mask bytes corresponding to " missing.". Note that the model performs much better if the masked span starts with a space.
>>> encoding["input_ids"][0, 52:61] = tokenizer.mask_token_id
>>> # forward pass
>>> with torch.no_grad():
... outputs = model(**encoding)
>>> logits = outputs.logits
>>> list(logits.shape)
[1, 2048, 262]
>>> masked_tokens_predictions = logits[0, 52:61].argmax(dim=-1).tolist()
>>> tokenizer.decode(masked_tokens_predictions)
' missing.'PerceiverForSequenceClassification
class transformers.PerceiverForSequenceClassification
< source >( config )
Parameters
- config (PerceiverConfig) — Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out the from_pretrained() method to load the model weights.
Example use of Perceiver for text classification. This model is a PyTorch torch.nn.Module sub-class. Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and behavior.
forward
< source >( inputs: Optional = None attention_mask: Optional = None head_mask: Optional = None output_attentions: Optional = None output_hidden_states: Optional = None labels: Optional = None return_dict: Optional = None input_ids: Optional = None ) → transformers.models.perceiver.modeling_perceiver.PerceiverClassifierOutput or tuple(torch.FloatTensor)
Parameters
- inputs (
torch.FloatTensor) — Inputs to the perceiver. Can be anything: images, text, audio, video, etc. - attention_mask (
torch.FloatTensorof shapebatch_size, sequence_length, optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
- head_mask (
torch.FloatTensorof shape(num_heads,)or(num_layers, num_heads), optional) — Mask to nullify selected heads of the self-attention modules. Mask values selected in[0, 1]:- 1 indicates the head is not masked,
- 0 indicates the head is masked.
- output_attentions (
bool, optional) — Whether or not to return the attentions tensors of all attention layers. Seeattentionsunder returned tensors for more detail. - output_hidden_states (
bool, optional) — Whether or not to return the hidden states of all layers. Seehidden_statesunder returned tensors for more detail. - interpolate_pos_encoding (
bool, optional, defaults toFalse) — Whether to interpolate the pre-trained position encodings. - return_dict (
bool, optional) — Whether or not to return a ModelOutput instead of a plain tuple. - labels (
torch.LongTensorof shape(batch_size,), optional) — Labels for computing the classification/regression loss. Indices should be in[0, ..., config.num_labels - 1]. Ifconfig.num_labels == 1a regression loss is computed (Mean-Square loss), Ifconfig.num_labels > 1a classification loss is computed (Cross-Entropy).
Returns
transformers.models.perceiver.modeling_perceiver.PerceiverClassifierOutput or tuple(torch.FloatTensor)
A transformers.models.perceiver.modeling_perceiver.PerceiverClassifierOutput or a tuple of
torch.FloatTensor (if return_dict=False is passed or when config.return_dict=False) comprising various
elements depending on the configuration (PerceiverConfig) and inputs.
- loss (
torch.FloatTensorof shape(1,), optional, returned whenlabelsis provided) — Classification (or regression if config.num_labels==1) loss. - logits (
torch.FloatTensorof shape(batch_size, config.num_labels)) — Classification (or regression if config.num_labels==1) scores (before SoftMax). - hidden_states (
tuple(torch.FloatTensor), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftorch.FloatTensor(one for the output of the embeddings + one for the output of each layer) of shape(batch_size, sequence_length, hidden_size). Hidden-states of the model at the output of each layer plus the initial embedding outputs. - attentions (
tuple(torch.FloatTensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftorch.FloatTensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length). Attentions weights after the attention softmax, used to compute the weighted average in the self-attention heads. - cross_attentions (
tuple(torch.FloatTensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftorch.FloatTensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length). Attentions weights of the decoder’s cross-attention layer, after the attention softmax, used to compute the weighted average in the cross-attention heads.
The PerceiverForSequenceClassification forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the Module
instance afterwards instead of this since the former takes care of running the pre and post processing steps while
the latter silently ignores them.
Examples:
>>> from transformers import AutoTokenizer, PerceiverForSequenceClassification
>>> tokenizer = AutoTokenizer.from_pretrained("deepmind/language-perceiver")
>>> model = PerceiverForSequenceClassification.from_pretrained("deepmind/language-perceiver")
>>> text = "hello world"
>>> inputs = tokenizer(text, return_tensors="pt").input_ids
>>> outputs = model(inputs=inputs)
>>> logits = outputs.logits
>>> list(logits.shape)
[1, 2]PerceiverForImageClassificationLearned
class transformers.PerceiverForImageClassificationLearned
< source >( config )
Parameters
- config (PerceiverConfig) — Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out the from_pretrained() method to load the model weights.
Example use of Perceiver for image classification, for tasks such as ImageNet.
This model uses learned position embeddings. In other words, this model is not given any privileged information about the structure of images. As shown in the paper, this model can achieve a top-1 accuracy of 72.7 on ImageNet.
PerceiverForImageClassificationLearned uses PerceiverImagePreprocessor
(with prep_type="conv1x1") to preprocess the input images, and
PerceiverClassificationDecoder to decode the latent representation of
PerceiverModel into classification logits.
This model is a PyTorch torch.nn.Module sub-class. Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and behavior.
forward
< source >( inputs: Optional = None attention_mask: Optional = None head_mask: Optional = None output_attentions: Optional = None output_hidden_states: Optional = None labels: Optional = None interpolate_pos_encoding: bool = False return_dict: Optional = None pixel_values: Optional = None ) → transformers.models.perceiver.modeling_perceiver.PerceiverClassifierOutput or tuple(torch.FloatTensor)
Parameters
- inputs (
torch.FloatTensor) — Inputs to the perceiver. Can be anything: images, text, audio, video, etc. - attention_mask (
torch.FloatTensorof shapebatch_size, sequence_length, optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
- head_mask (
torch.FloatTensorof shape(num_heads,)or(num_layers, num_heads), optional) — Mask to nullify selected heads of the self-attention modules. Mask values selected in[0, 1]:- 1 indicates the head is not masked,
- 0 indicates the head is masked.
- output_attentions (
bool, optional) — Whether or not to return the attentions tensors of all attention layers. Seeattentionsunder returned tensors for more detail. - output_hidden_states (
bool, optional) — Whether or not to return the hidden states of all layers. Seehidden_statesunder returned tensors for more detail. - interpolate_pos_encoding (
bool, optional, defaults toFalse) — Whether to interpolate the pre-trained position encodings. - return_dict (
bool, optional) — Whether or not to return a ModelOutput instead of a plain tuple. - labels (
torch.LongTensorof shape(batch_size,), optional) — Labels for computing the image classification/regression loss. Indices should be in[0, ..., config.num_labels - 1]. Ifconfig.num_labels == 1a regression loss is computed (Mean-Square loss), Ifconfig.num_labels > 1a classification loss is computed (Cross-Entropy).
Returns
transformers.models.perceiver.modeling_perceiver.PerceiverClassifierOutput or tuple(torch.FloatTensor)
A transformers.models.perceiver.modeling_perceiver.PerceiverClassifierOutput or a tuple of
torch.FloatTensor (if return_dict=False is passed or when config.return_dict=False) comprising various
elements depending on the configuration (PerceiverConfig) and inputs.
- loss (
torch.FloatTensorof shape(1,), optional, returned whenlabelsis provided) — Classification (or regression if config.num_labels==1) loss. - logits (
torch.FloatTensorof shape(batch_size, config.num_labels)) — Classification (or regression if config.num_labels==1) scores (before SoftMax). - hidden_states (
tuple(torch.FloatTensor), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftorch.FloatTensor(one for the output of the embeddings + one for the output of each layer) of shape(batch_size, sequence_length, hidden_size). Hidden-states of the model at the output of each layer plus the initial embedding outputs. - attentions (
tuple(torch.FloatTensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftorch.FloatTensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length). Attentions weights after the attention softmax, used to compute the weighted average in the self-attention heads. - cross_attentions (
tuple(torch.FloatTensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftorch.FloatTensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length). Attentions weights of the decoder’s cross-attention layer, after the attention softmax, used to compute the weighted average in the cross-attention heads.
The PerceiverForImageClassificationLearned forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the Module
instance afterwards instead of this since the former takes care of running the pre and post processing steps while
the latter silently ignores them.
Examples:
>>> from transformers import AutoImageProcessor, PerceiverForImageClassificationLearned
>>> from PIL import Image
>>> import requests
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> image_processor = AutoImageProcessor.from_pretrained("deepmind/vision-perceiver-learned")
>>> model = PerceiverForImageClassificationLearned.from_pretrained("deepmind/vision-perceiver-learned")
>>> inputs = image_processor(images=image, return_tensors="pt").pixel_values
>>> outputs = model(inputs=inputs)
>>> logits = outputs.logits
>>> list(logits.shape)
[1, 1000]
>>> # model predicts one of the 1000 ImageNet classes
>>> predicted_class_idx = logits.argmax(-1).item()
>>> print("Predicted class:", model.config.id2label[predicted_class_idx])
Predicted class: tabby, tabby catPerceiverForImageClassificationFourier
class transformers.PerceiverForImageClassificationFourier
< source >( config )
Parameters
- config (PerceiverConfig) — Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out the from_pretrained() method to load the model weights.
Example use of Perceiver for image classification, for tasks such as ImageNet.
This model uses fixed 2D Fourier position embeddings. As shown in the paper, this model can achieve a top-1 accuracy of 79.0 on ImageNet, and 84.5 when pre-trained on a large-scale dataset (i.e. JFT).
PerceiverForImageClassificationLearned uses PerceiverImagePreprocessor
(with prep_type="pixels") to preprocess the input images, and
PerceiverClassificationDecoder to decode the latent representation of
PerceiverModel into classification logits.
This model is a PyTorch torch.nn.Module sub-class. Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and behavior.
forward
< source >( inputs: Optional = None attention_mask: Optional = None head_mask: Optional = None output_attentions: Optional = None output_hidden_states: Optional = None labels: Optional = None return_dict: Optional = None pixel_values: Optional = None ) → transformers.models.perceiver.modeling_perceiver.PerceiverClassifierOutput or tuple(torch.FloatTensor)
Parameters
- inputs (
torch.FloatTensor) — Inputs to the perceiver. Can be anything: images, text, audio, video, etc. - attention_mask (
torch.FloatTensorof shapebatch_size, sequence_length, optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
- head_mask (
torch.FloatTensorof shape(num_heads,)or(num_layers, num_heads), optional) — Mask to nullify selected heads of the self-attention modules. Mask values selected in[0, 1]:- 1 indicates the head is not masked,
- 0 indicates the head is masked.
- output_attentions (
bool, optional) — Whether or not to return the attentions tensors of all attention layers. Seeattentionsunder returned tensors for more detail. - output_hidden_states (
bool, optional) — Whether or not to return the hidden states of all layers. Seehidden_statesunder returned tensors for more detail. - interpolate_pos_encoding (
bool, optional, defaults toFalse) — Whether to interpolate the pre-trained position encodings. - return_dict (
bool, optional) — Whether or not to return a ModelOutput instead of a plain tuple. - labels (
torch.LongTensorof shape(batch_size,), optional) — Labels for computing the image classification/regression loss. Indices should be in[0, ..., config.num_labels - 1]. Ifconfig.num_labels == 1a regression loss is computed (Mean-Square loss), Ifconfig.num_labels > 1a classification loss is computed (Cross-Entropy).
Returns
transformers.models.perceiver.modeling_perceiver.PerceiverClassifierOutput or tuple(torch.FloatTensor)
A transformers.models.perceiver.modeling_perceiver.PerceiverClassifierOutput or a tuple of
torch.FloatTensor (if return_dict=False is passed or when config.return_dict=False) comprising various
elements depending on the configuration (PerceiverConfig) and inputs.
- loss (
torch.FloatTensorof shape(1,), optional, returned whenlabelsis provided) — Classification (or regression if config.num_labels==1) loss. - logits (
torch.FloatTensorof shape(batch_size, config.num_labels)) — Classification (or regression if config.num_labels==1) scores (before SoftMax). - hidden_states (
tuple(torch.FloatTensor), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftorch.FloatTensor(one for the output of the embeddings + one for the output of each layer) of shape(batch_size, sequence_length, hidden_size). Hidden-states of the model at the output of each layer plus the initial embedding outputs. - attentions (
tuple(torch.FloatTensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftorch.FloatTensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length). Attentions weights after the attention softmax, used to compute the weighted average in the self-attention heads. - cross_attentions (
tuple(torch.FloatTensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftorch.FloatTensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length). Attentions weights of the decoder’s cross-attention layer, after the attention softmax, used to compute the weighted average in the cross-attention heads.
The PerceiverForImageClassificationFourier forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the Module
instance afterwards instead of this since the former takes care of running the pre and post processing steps while
the latter silently ignores them.
Examples:
>>> from transformers import AutoImageProcessor, PerceiverForImageClassificationFourier
>>> from PIL import Image
>>> import requests
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> image_processor = AutoImageProcessor.from_pretrained("deepmind/vision-perceiver-fourier")
>>> model = PerceiverForImageClassificationFourier.from_pretrained("deepmind/vision-perceiver-fourier")
>>> inputs = image_processor(images=image, return_tensors="pt").pixel_values
>>> outputs = model(inputs=inputs)
>>> logits = outputs.logits
>>> list(logits.shape)
[1, 1000]
>>> # model predicts one of the 1000 ImageNet classes
>>> predicted_class_idx = logits.argmax(-1).item()
>>> print("Predicted class:", model.config.id2label[predicted_class_idx])
Predicted class: tabby, tabby catPerceiverForImageClassificationConvProcessing
class transformers.PerceiverForImageClassificationConvProcessing
< source >( config )
Parameters
- config (PerceiverConfig) — Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out the from_pretrained() method to load the model weights.
Example use of Perceiver for image classification, for tasks such as ImageNet.
This model uses a 2D conv+maxpool preprocessing network. As shown in the paper, this model can achieve a top-1 accuracy of 82.1 on ImageNet.
PerceiverForImageClassificationLearned uses PerceiverImagePreprocessor
(with prep_type="conv") to preprocess the input images, and
PerceiverClassificationDecoder to decode the latent representation of
PerceiverModel into classification logits.
This model is a PyTorch torch.nn.Module sub-class. Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and behavior.
forward
< source >( inputs: Optional = None attention_mask: Optional = None head_mask: Optional = None output_attentions: Optional = None output_hidden_states: Optional = None labels: Optional = None return_dict: Optional = None pixel_values: Optional = None ) → transformers.models.perceiver.modeling_perceiver.PerceiverClassifierOutput or tuple(torch.FloatTensor)
Parameters
- inputs (
torch.FloatTensor) — Inputs to the perceiver. Can be anything: images, text, audio, video, etc. - attention_mask (
torch.FloatTensorof shapebatch_size, sequence_length, optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
- head_mask (
torch.FloatTensorof shape(num_heads,)or(num_layers, num_heads), optional) — Mask to nullify selected heads of the self-attention modules. Mask values selected in[0, 1]:- 1 indicates the head is not masked,
- 0 indicates the head is masked.
- output_attentions (
bool, optional) — Whether or not to return the attentions tensors of all attention layers. Seeattentionsunder returned tensors for more detail. - output_hidden_states (
bool, optional) — Whether or not to return the hidden states of all layers. Seehidden_statesunder returned tensors for more detail. - interpolate_pos_encoding (
bool, optional, defaults toFalse) — Whether to interpolate the pre-trained position encodings. - return_dict (
bool, optional) — Whether or not to return a ModelOutput instead of a plain tuple. - labels (
torch.LongTensorof shape(batch_size,), optional) — Labels for computing the image classification/regression loss. Indices should be in[0, ..., config.num_labels - 1]. Ifconfig.num_labels == 1a regression loss is computed (Mean-Square loss), Ifconfig.num_labels > 1a classification loss is computed (Cross-Entropy).
Returns
transformers.models.perceiver.modeling_perceiver.PerceiverClassifierOutput or tuple(torch.FloatTensor)
A transformers.models.perceiver.modeling_perceiver.PerceiverClassifierOutput or a tuple of
torch.FloatTensor (if return_dict=False is passed or when config.return_dict=False) comprising various
elements depending on the configuration (PerceiverConfig) and inputs.
- loss (
torch.FloatTensorof shape(1,), optional, returned whenlabelsis provided) — Classification (or regression if config.num_labels==1) loss. - logits (
torch.FloatTensorof shape(batch_size, config.num_labels)) — Classification (or regression if config.num_labels==1) scores (before SoftMax). - hidden_states (
tuple(torch.FloatTensor), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftorch.FloatTensor(one for the output of the embeddings + one for the output of each layer) of shape(batch_size, sequence_length, hidden_size). Hidden-states of the model at the output of each layer plus the initial embedding outputs. - attentions (
tuple(torch.FloatTensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftorch.FloatTensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length). Attentions weights after the attention softmax, used to compute the weighted average in the self-attention heads. - cross_attentions (
tuple(torch.FloatTensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftorch.FloatTensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length). Attentions weights of the decoder’s cross-attention layer, after the attention softmax, used to compute the weighted average in the cross-attention heads.
The PerceiverForImageClassificationConvProcessing forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the Module
instance afterwards instead of this since the former takes care of running the pre and post processing steps while
the latter silently ignores them.
Examples:
>>> from transformers import AutoImageProcessor, PerceiverForImageClassificationConvProcessing
>>> from PIL import Image
>>> import requests
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> image_processor = AutoImageProcessor.from_pretrained("deepmind/vision-perceiver-conv")
>>> model = PerceiverForImageClassificationConvProcessing.from_pretrained("deepmind/vision-perceiver-conv")
>>> inputs = image_processor(images=image, return_tensors="pt").pixel_values
>>> outputs = model(inputs=inputs)
>>> logits = outputs.logits
>>> list(logits.shape)
[1, 1000]
>>> # model predicts one of the 1000 ImageNet classes
>>> predicted_class_idx = logits.argmax(-1).item()
>>> print("Predicted class:", model.config.id2label[predicted_class_idx])
Predicted class: tabby, tabby catPerceiverForOpticalFlow
class transformers.PerceiverForOpticalFlow
< source >( config )
Parameters
- config (PerceiverConfig) — Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out the from_pretrained() method to load the model weights.
Example use of Perceiver for optical flow, for tasks such as Sintel and KITTI. PerceiverForOpticalFlow uses PerceiverImagePreprocessor (with prep_type=“patches”) to preprocess the input images, and PerceiverOpticalFlowDecoder to decode the latent representation of PerceiverModel.
As input, one concatenates 2 subsequent frames along the channel dimension and extract a 3 x 3 patch around each pixel (leading to 3 x 3 x 3 x 2 = 54 values for each pixel). Fixed Fourier position encodings are used to encode the position of each pixel in the patch. Next, one applies the Perceiver encoder. To decode, one queries the latent representation using the same encoding used for the input.
This model is a PyTorch torch.nn.Module sub-class. Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and behavior.
forward
< source >( inputs: Optional = None attention_mask: Optional = None head_mask: Optional = None output_attentions: Optional = None output_hidden_states: Optional = None labels: Optional = None return_dict: Optional = None ) → transformers.models.perceiver.modeling_perceiver.PerceiverClassifierOutput or tuple(torch.FloatTensor)
Parameters
- inputs (
torch.FloatTensor) — Inputs to the perceiver. Can be anything: images, text, audio, video, etc. - attention_mask (
torch.FloatTensorof shapebatch_size, sequence_length, optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
- head_mask (
torch.FloatTensorof shape(num_heads,)or(num_layers, num_heads), optional) — Mask to nullify selected heads of the self-attention modules. Mask values selected in[0, 1]:- 1 indicates the head is not masked,
- 0 indicates the head is masked.
- output_attentions (
bool, optional) — Whether or not to return the attentions tensors of all attention layers. Seeattentionsunder returned tensors for more detail. - output_hidden_states (
bool, optional) — Whether or not to return the hidden states of all layers. Seehidden_statesunder returned tensors for more detail. - interpolate_pos_encoding (
bool, optional, defaults toFalse) — Whether to interpolate the pre-trained position encodings. - return_dict (
bool, optional) — Whether or not to return a ModelOutput instead of a plain tuple. - labels (
torch.LongTensorof shape(batch_size,), optional) — Labels for computing the optical flow loss. Indices should be in[0, ..., config.num_labels - 1].
Returns
transformers.models.perceiver.modeling_perceiver.PerceiverClassifierOutput or tuple(torch.FloatTensor)
A transformers.models.perceiver.modeling_perceiver.PerceiverClassifierOutput or a tuple of
torch.FloatTensor (if return_dict=False is passed or when config.return_dict=False) comprising various
elements depending on the configuration (PerceiverConfig) and inputs.
- loss (
torch.FloatTensorof shape(1,), optional, returned whenlabelsis provided) — Classification (or regression if config.num_labels==1) loss. - logits (
torch.FloatTensorof shape(batch_size, config.num_labels)) — Classification (or regression if config.num_labels==1) scores (before SoftMax). - hidden_states (
tuple(torch.FloatTensor), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftorch.FloatTensor(one for the output of the embeddings + one for the output of each layer) of shape(batch_size, sequence_length, hidden_size). Hidden-states of the model at the output of each layer plus the initial embedding outputs. - attentions (
tuple(torch.FloatTensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftorch.FloatTensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length). Attentions weights after the attention softmax, used to compute the weighted average in the self-attention heads. - cross_attentions (
tuple(torch.FloatTensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftorch.FloatTensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length). Attentions weights of the decoder’s cross-attention layer, after the attention softmax, used to compute the weighted average in the cross-attention heads.
The PerceiverForOpticalFlow forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the Module
instance afterwards instead of this since the former takes care of running the pre and post processing steps while
the latter silently ignores them.
Examples:
>>> from transformers import PerceiverForOpticalFlow
>>> import torch
>>> model = PerceiverForOpticalFlow.from_pretrained("deepmind/optical-flow-perceiver")
>>> # in the Perceiver IO paper, the authors extract a 3 x 3 patch around each pixel,
>>> # leading to 3 x 3 x 3 = 27 values for each pixel (as each pixel also has 3 color channels)
>>> # patches have shape (batch_size, num_frames, num_channels, height, width)
>>> # the authors train on resolutions of 368 x 496
>>> patches = torch.randn(1, 2, 27, 368, 496)
>>> outputs = model(inputs=patches)
>>> logits = outputs.logits
>>> list(logits.shape)
[1, 368, 496, 2]PerceiverForMultimodalAutoencoding
class transformers.PerceiverForMultimodalAutoencoding
< source >( config: PerceiverConfig )
Parameters
- config (PerceiverConfig) — Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out the from_pretrained() method to load the model weights.
Example use of Perceiver for multimodal (video) autoencoding, for tasks such as Kinetics-700.
PerceiverForMultimodalAutoencoding uses PerceiverMultimodalPreprocessor to preprocess the 3 modalities: images, audio and class labels. This preprocessor uses modality-specific preprocessors to preprocess every modality separately, after which they are concatenated. Trainable position embeddings are used to pad each modality to the same number of channels to make concatenation along the time dimension possible. Next, one applies the Perceiver encoder.
PerceiverMultimodalDecoder is used to decode the latent representation of PerceiverModel. This decoder uses each modality-specific decoder to construct queries. The decoder queries are created based on the inputs after preprocessing. However, autoencoding an entire video in a single forward pass is computationally infeasible, hence one only uses parts of the decoder queries to do cross-attention with the latent representation. This is determined by the subsampled indices for each modality, which can be provided as additional input to the forward pass of PerceiverForMultimodalAutoencoding.
PerceiverMultimodalDecoder also pads the decoder queries of the different modalities to the same number of channels, in order to concatenate them along the time dimension. Next, cross-attention is performed with the latent representation of PerceiverModel.
Finally, ~models.perceiver.modeling_perceiver.PerceiverMultiModalPostprocessor is used to turn this tensor into an
actual video. It first splits up the output into the different modalities, and then applies the respective
postprocessor for each modality.
Note that, by masking the classification label during evaluation (i.e. simply providing a tensor of zeros for the “label” modality), this auto-encoding model becomes a Kinetics 700 video classifier.
This model is a PyTorch torch.nn.Module sub-class. Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and behavior.
forward
< source >( inputs: Optional = None attention_mask: Optional = None subsampled_output_points: Optional = None head_mask: Optional = None output_attentions: Optional = None output_hidden_states: Optional = None labels: Optional = None return_dict: Optional = None ) → transformers.models.perceiver.modeling_perceiver.PerceiverClassifierOutput or tuple(torch.FloatTensor)
Parameters
- inputs (
torch.FloatTensor) — Inputs to the perceiver. Can be anything: images, text, audio, video, etc. - attention_mask (
torch.FloatTensorof shapebatch_size, sequence_length, optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
- head_mask (
torch.FloatTensorof shape(num_heads,)or(num_layers, num_heads), optional) — Mask to nullify selected heads of the self-attention modules. Mask values selected in[0, 1]:- 1 indicates the head is not masked,
- 0 indicates the head is masked.
- output_attentions (
bool, optional) — Whether or not to return the attentions tensors of all attention layers. Seeattentionsunder returned tensors for more detail. - output_hidden_states (
bool, optional) — Whether or not to return the hidden states of all layers. Seehidden_statesunder returned tensors for more detail. - interpolate_pos_encoding (
bool, optional, defaults toFalse) — Whether to interpolate the pre-trained position encodings. - return_dict (
bool, optional) — Whether or not to return a ModelOutput instead of a plain tuple. - labels (
torch.LongTensorof shape(batch_size,), optional) — Labels for computing the image classification/regression loss. Indices should be in[0, ..., config.num_labels - 1]. Ifconfig.num_labels == 1a regression loss is computed (Mean-Square loss), Ifconfig.num_labels > 1a classification loss is computed (Cross-Entropy).
Returns
transformers.models.perceiver.modeling_perceiver.PerceiverClassifierOutput or tuple(torch.FloatTensor)
A transformers.models.perceiver.modeling_perceiver.PerceiverClassifierOutput or a tuple of
torch.FloatTensor (if return_dict=False is passed or when config.return_dict=False) comprising various
elements depending on the configuration (PerceiverConfig) and inputs.
- loss (
torch.FloatTensorof shape(1,), optional, returned whenlabelsis provided) — Classification (or regression if config.num_labels==1) loss. - logits (
torch.FloatTensorof shape(batch_size, config.num_labels)) — Classification (or regression if config.num_labels==1) scores (before SoftMax). - hidden_states (
tuple(torch.FloatTensor), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftorch.FloatTensor(one for the output of the embeddings + one for the output of each layer) of shape(batch_size, sequence_length, hidden_size). Hidden-states of the model at the output of each layer plus the initial embedding outputs. - attentions (
tuple(torch.FloatTensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftorch.FloatTensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length). Attentions weights after the attention softmax, used to compute the weighted average in the self-attention heads. - cross_attentions (
tuple(torch.FloatTensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftorch.FloatTensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length). Attentions weights of the decoder’s cross-attention layer, after the attention softmax, used to compute the weighted average in the cross-attention heads.
The PerceiverForMultimodalAutoencoding forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the Module
instance afterwards instead of this since the former takes care of running the pre and post processing steps while
the latter silently ignores them.
Examples:
>>> from transformers import PerceiverForMultimodalAutoencoding
>>> import torch
>>> import numpy as np
>>> # create multimodal inputs
>>> images = torch.randn((1, 16, 3, 224, 224))
>>> audio = torch.randn((1, 30720, 1))
>>> inputs = dict(image=images, audio=audio, label=torch.zeros((images.shape[0], 700)))
>>> model = PerceiverForMultimodalAutoencoding.from_pretrained("deepmind/multimodal-perceiver")
>>> # in the Perceiver IO paper, videos are auto-encoded in chunks
>>> # each chunk subsamples different index dimensions of the image and audio modality decoder queries
>>> nchunks = 128
>>> image_chunk_size = np.prod((16, 224, 224)) // nchunks
>>> audio_chunk_size = audio.shape[1] // model.config.samples_per_patch // nchunks
>>> # process the first chunk
>>> chunk_idx = 0
>>> subsampling = {
... "image": torch.arange(image_chunk_size * chunk_idx, image_chunk_size * (chunk_idx + 1)),
... "audio": torch.arange(audio_chunk_size * chunk_idx, audio_chunk_size * (chunk_idx + 1)),
... "label": None,
... }
>>> outputs = model(inputs=inputs, subsampled_output_points=subsampling)
>>> logits = outputs.logits
>>> list(logits["audio"].shape)
[1, 240]
>>> list(logits["image"].shape)
[1, 6272, 3]
>>> list(logits["label"].shape)
[1, 700]