Transformers documentation
GPU inference
GPU inference
GPUs are the standard choice of hardware for machine learning, unlike CPUs, because they are optimized for memory bandwidth and parallelism. To keep up with the larger sizes of modern models or to run these large models on existing and older hardware, there are several optimizations you can use to speed up GPU inference. In this guide, you’ll learn how to use FlashAttention-2 (a more memory-efficient attention mechanism), BetterTransformer (a PyTorch native fastpath execution), and bitsandbytes to quantize your model to a lower precision. Finally, learn how to use 🤗 Optimum to accelerate inference with ONNX Runtime on Nvidia and AMD GPUs.
The majority of the optimizations described here also apply to multi-GPU setups!
FlashAttention-2
FlashAttention-2 is experimental and may change considerably in future versions.
FlashAttention-2 is a faster and more efficient implementation of the standard attention mechanism that can significantly speedup inference by:
- additionally parallelizing the attention computation over sequence length
- partitioning the work between GPU threads to reduce communication and shared memory reads/writes between them
FlashAttention-2 is currently supported for the following architectures:
- Bark
- Bart
- Chameleon
- CLIP
- Cohere
- Dbrx
- DistilBert
- Gemma
- Gemma2
- GPT2
- GPTBigCode
- GPTNeo
- GPTNeoX
- GPT-J
- Idefics2
- Falcon
- JetMoe
- Jamba
- Llama
- Llava
- Llava-NeXT
- Llava-NeXT-Video
- VipLlava
- VideoLlava
- M2M100
- MBart
- Mistral
- Mixtral
- Musicgen
- MusicGen Melody
- Nemotron
- NLLB
- OLMo
- OPT
- Phi
- Phi3
- SigLIP
- StableLm
- Starcoder2
- Qwen2
- Qwen2MoE
- Whisper
- Wav2Vec2
- Hubert
- data2vec_audio
- Sew
- UniSpeech
- unispeech_sat
You can request to add FlashAttention-2 support for another model by opening a GitHub Issue or Pull Request.
Before you begin, make sure you have FlashAttention-2 installed.
pip install flash-attn --no-build-isolation
We strongly suggest referring to the detailed installation instructions to learn more about supported hardware and data types!
To enable FlashAttention-2, pass the argument attn_implementation="flash_attention_2" to from_pretrained():
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, LlamaForCausalLM
model_id = "tiiuae/falcon-7b"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.bfloat16,
attn_implementation="flash_attention_2",
)FlashAttention-2 can only be used when the model’s dtype is fp16 or bf16. Make sure to cast your model to the appropriate dtype and load them on a supported device before using FlashAttention-2.
You can also set use_flash_attention_2=True to enable FlashAttention-2 but it is deprecated in favor of attn_implementation="flash_attention_2".
FlashAttention-2 can be combined with other optimization techniques like quantization to further speedup inference. For example, you can combine FlashAttention-2 with 8-bit or 4-bit quantization:
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, LlamaForCausalLM
model_id = "tiiuae/falcon-7b"
tokenizer = AutoTokenizer.from_pretrained(model_id)
# load in 8bit
model = AutoModelForCausalLM.from_pretrained(
model_id,
load_in_8bit=True,
attn_implementation="flash_attention_2",
)
# load in 4bit
model = AutoModelForCausalLM.from_pretrained(
model_id,
load_in_4bit=True,
attn_implementation="flash_attention_2",
)Expected speedups
You can benefit from considerable speedups for inference, especially for inputs with long sequences. However, since FlashAttention-2 does not support computing attention scores with padding tokens, you must manually pad/unpad the attention scores for batched inference when the sequence contains padding tokens. This leads to a significant slowdown for batched generations with padding tokens.
To overcome this, you should use FlashAttention-2 without padding tokens in the sequence during training (by packing a dataset or concatenating sequences until reaching the maximum sequence length).
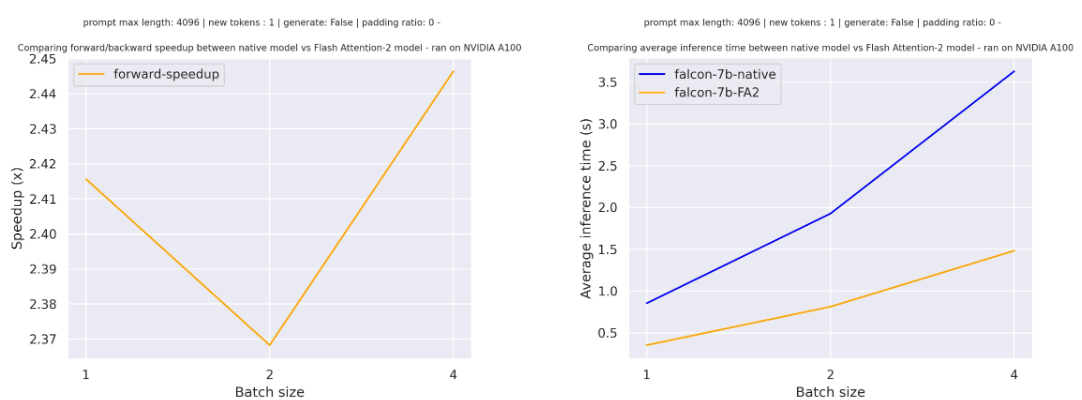
For a single forward pass on tiiuae/falcon-7b with a sequence length of 4096 and various batch sizes without padding tokens, the expected speedup is:
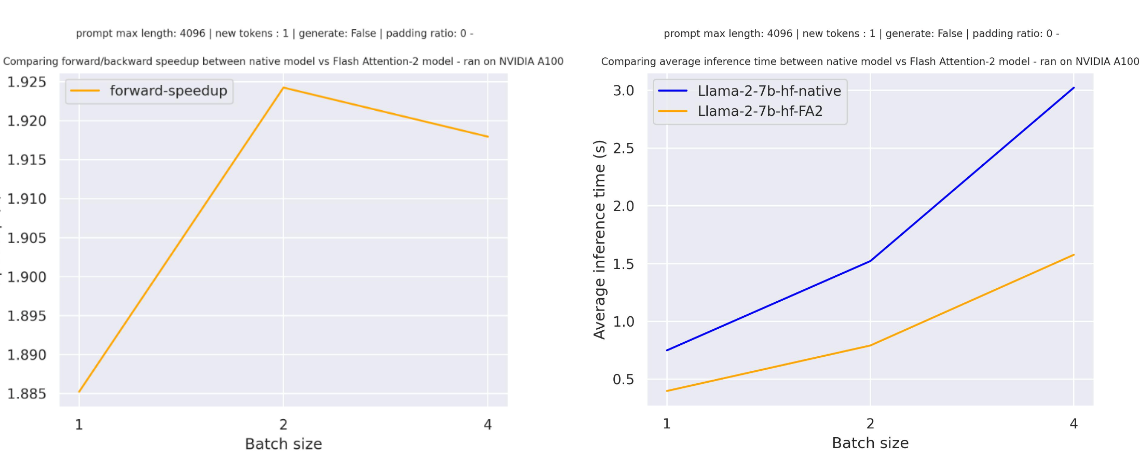
For a single forward pass on meta-llama/Llama-7b-hf with a sequence length of 4096 and various batch sizes without padding tokens, the expected speedup is:
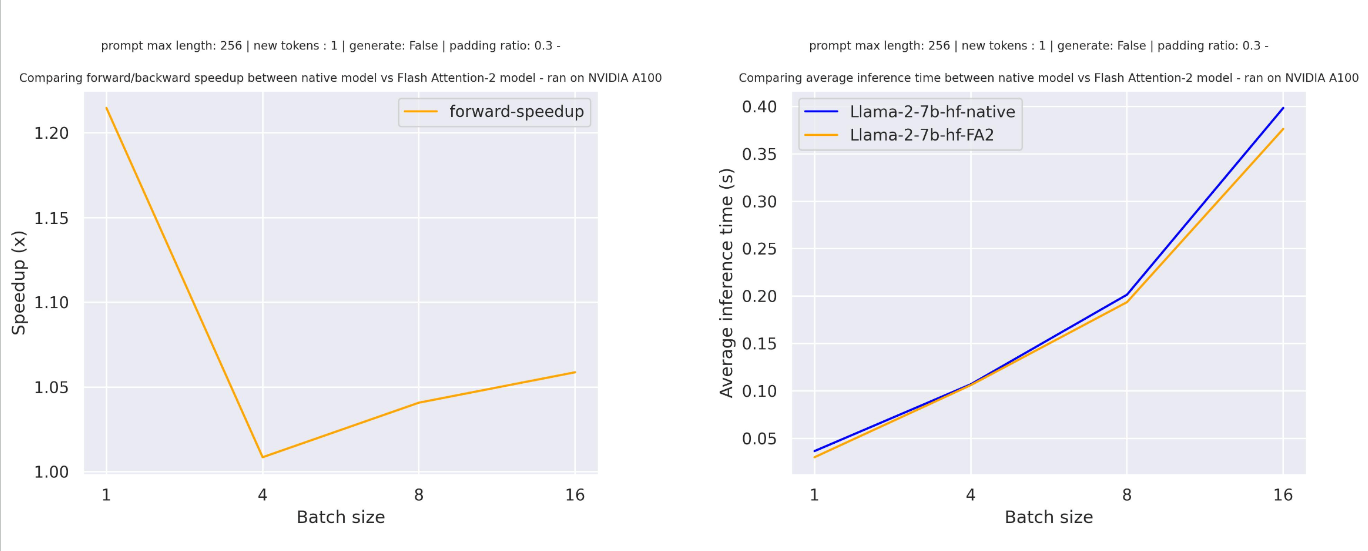
For sequences with padding tokens (generating with padding tokens), you need to unpad/pad the input sequences to correctly compute the attention scores. With a relatively small sequence length, a single forward pass creates overhead leading to a small speedup (in the example below, 30% of the input is filled with padding tokens):
But for larger sequence lengths, you can expect even more speedup benefits:
FlashAttention is more memory efficient, meaning you can train on much larger sequence lengths without running into out-of-memory issues. You can potentially reduce memory usage up to 20x for larger sequence lengths. Take a look at the flash-attention repository for more details.

PyTorch scaled dot product attention
PyTorch’s torch.nn.functional.scaled_dot_product_attention (SDPA) can also call FlashAttention and memory-efficient attention kernels under the hood. SDPA support is currently being added natively in Transformers and is used by default for torch>=2.1.1 when an implementation is available. You may also set attn_implementation="sdpa" in from_pretrained() to explicitly request SDPA to be used.
For now, Transformers supports SDPA inference and training for the following architectures:
- Audio Spectrogram Transformer
- Bart
- Bert
- Chameleon
- CLIP
- Cohere
- Dbrx
- DeiT
- Dpr
- Falcon
- Gemma
- Gemma2
- GPT2
- GPTBigCode
- GPTNeoX
- JetMoe
- Jamba
- Llama
- OLMo
- PaliGemma
- Phi
- Idefics
- Whisper
- Mistral
- Mixtral
- StableLm
- Starcoder2
- Qwen2
- Qwen2MoE
- Musicgen
- MusicGen Melody
- Nemotron
- ViT
- ViTHybrid
- ViTMAE
- ViTMSN
- VideoMAE
- wav2vec2
- Hubert
- data2vec_audio
- SigLIP
- Sew
- UniSpeech
- unispeech_sat
- YOLOS
FlashAttention can only be used for models with the fp16 or bf16 torch type, so make sure to cast your model to the appropriate type first. The memory-efficient attention backend is able to handle fp32 models.
SDPA does not support certain sets of attention parameters, such as head_mask and output_attentions=True.
In that case, you should see a warning message and we will fall back to the (slower) eager implementation.
By default, SDPA selects the most performant kernel available but you can check whether a backend is available in a given setting (hardware, problem size) with torch.backends.cuda.sdp_kernel as a context manager:
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("facebook/opt-350m")
model = AutoModelForCausalLM.from_pretrained("facebook/opt-350m", torch_dtype=torch.float16).to("cuda")
input_text = "Hello my dog is cute and"
inputs = tokenizer(input_text, return_tensors="pt").to("cuda")
+ with torch.backends.cuda.sdp_kernel(enable_flash=True, enable_math=False, enable_mem_efficient=False):
outputs = model.generate(**inputs)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))If you see a bug with the traceback below, try using the nightly version of PyTorch which may have broader coverage for FlashAttention:
RuntimeError: No available kernel. Aborting execution.
# install PyTorch nightly
pip3 install -U --pre torch torchvision torchaudio --index-url https://download.pytorch.org/whl/nightly/cu118BetterTransformer
Some BetterTransformer features are being upstreamed to Transformers with default support for native torch.nn.scaled_dot_product_attention. BetterTransformer still has a wider coverage than the Transformers SDPA integration, but you can expect more and more architectures to natively support SDPA in Transformers.
Check out our benchmarks with BetterTransformer and scaled dot product attention in the Out of the box acceleration and memory savings of 🤗 decoder models with PyTorch 2.0 and learn more about the fastpath execution in the BetterTransformer blog post.
BetterTransformer accelerates inference with its fastpath (native PyTorch specialized implementation of Transformer functions) execution. The two optimizations in the fastpath execution are:
- fusion, which combines multiple sequential operations into a single “kernel” to reduce the number of computation steps
- skipping the inherent sparsity of padding tokens to avoid unnecessary computation with nested tensors
BetterTransformer also converts all attention operations to use the more memory-efficient scaled dot product attention (SDPA), and it calls optimized kernels like FlashAttention under the hood.
Before you start, make sure you have 🤗 Optimum installed.
Then you can enable BetterTransformer with the PreTrainedModel.to_bettertransformer() method:
model = model.to_bettertransformer()
You can return the original Transformers model with the reverse_bettertransformer() method. You should use this before saving your model to use the canonical Transformers modeling:
model = model.reverse_bettertransformer()
model.save_pretrained("saved_model")bitsandbytes
bitsandbytes is a quantization library that includes support for 4-bit and 8-bit quantization. Quantization reduces your model size compared to its native full precision version, making it easier to fit large models onto GPUs with limited memory.
Make sure you have bitsandbytes and 🤗 Accelerate installed:
# these versions support 8-bit and 4-bit
pip install bitsandbytes>=0.39.0 accelerate>=0.20.0
# install Transformers
pip install transformers4-bit
To load a model in 4-bit for inference, use the load_in_4bit parameter. The device_map parameter is optional, but we recommend setting it to "auto" to allow 🤗 Accelerate to automatically and efficiently allocate the model given the available resources in the environment.
from transformers import AutoModelForCausalLM
model_name = "bigscience/bloom-2b5"
model_4bit = AutoModelForCausalLM.from_pretrained(model_name, device_map="auto", load_in_4bit=True)To load a model in 4-bit for inference with multiple GPUs, you can control how much GPU RAM you want to allocate to each GPU. For example, to distribute 600MB of memory to the first GPU and 1GB of memory to the second GPU:
max_memory_mapping = {0: "600MB", 1: "1GB"}
model_name = "bigscience/bloom-3b"
model_4bit = AutoModelForCausalLM.from_pretrained(
model_name, device_map="auto", load_in_4bit=True, max_memory=max_memory_mapping
)8-bit
If you’re curious and interested in learning more about the concepts underlying 8-bit quantization, read the Gentle Introduction to 8-bit Matrix Multiplication for transformers at scale using Hugging Face Transformers, Accelerate and bitsandbytes blog post.
To load a model in 8-bit for inference, use the load_in_8bit parameter. The device_map parameter is optional, but we recommend setting it to "auto" to allow 🤗 Accelerate to automatically and efficiently allocate the model given the available resources in the environment:
from transformers import AutoModelForCausalLM, BitsAndBytesConfig
model_name = "bigscience/bloom-2b5"
model_8bit = AutoModelForCausalLM.from_pretrained(model_name, quantization_config=BitsAndBytesConfig(load_in_8bit=True))If you’re loading a model in 8-bit for text generation, you should use the generate() method instead of the Pipeline function which is not optimized for 8-bit models and will be slower. Some sampling strategies, like nucleus sampling, are also not supported by the Pipeline for 8-bit models. You should also place all inputs on the same device as the model:
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
model_name = "bigscience/bloom-2b5"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model_8bit = AutoModelForCausalLM.from_pretrained(model_name, quantization_config=BitsAndBytesConfig(load_in_8bit=True))
prompt = "Hello, my llama is cute"
inputs = tokenizer(prompt, return_tensors="pt").to("cuda")
generated_ids = model.generate(**inputs)
outputs = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)To load a model in 4-bit for inference with multiple GPUs, you can control how much GPU RAM you want to allocate to each GPU. For example, to distribute 1GB of memory to the first GPU and 2GB of memory to the second GPU:
max_memory_mapping = {0: "1GB", 1: "2GB"}
model_name = "bigscience/bloom-3b"
model_8bit = AutoModelForCausalLM.from_pretrained(
model_name, device_map="auto", load_in_8bit=True, max_memory=max_memory_mapping
)Feel free to try running a 11 billion parameter T5 model or the 3 billion parameter BLOOM model for inference on Google Colab’s free tier GPUs!
🤗 Optimum
Learn more details about using ORT with 🤗 Optimum in the Accelerated inference on NVIDIA GPUs and Accelerated inference on AMD GPUs guides. This section only provides a brief and simple example.
ONNX Runtime (ORT) is a model accelerator that supports accelerated inference on Nvidia GPUs, and AMD GPUs that use ROCm stack. ORT uses optimization techniques like fusing common operations into a single node and constant folding to reduce the number of computations performed and speedup inference. ORT also places the most computationally intensive operations on the GPU and the rest on the CPU to intelligently distribute the workload between the two devices.
ORT is supported by 🤗 Optimum which can be used in 🤗 Transformers. You’ll need to use an ORTModel for the task you’re solving, and specify the provider parameter which can be set to either CUDAExecutionProvider, ROCMExecutionProvider or TensorrtExecutionProvider. If you want to load a model that was not yet exported to ONNX, you can set export=True to convert your model on-the-fly to the ONNX format:
from optimum.onnxruntime import ORTModelForSequenceClassification
ort_model = ORTModelForSequenceClassification.from_pretrained(
"distilbert/distilbert-base-uncased-finetuned-sst-2-english",
export=True,
provider="CUDAExecutionProvider",
)Now you’re free to use the model for inference:
from optimum.pipelines import pipeline
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("distilbert/distilbert-base-uncased-finetuned-sst-2-english")
pipeline = pipeline(task="text-classification", model=ort_model, tokenizer=tokenizer, device="cuda:0")
result = pipeline("Both the music and visual were astounding, not to mention the actors performance.")Combine optimizations
It is often possible to combine several of the optimization techniques described above to get the best inference performance possible for your model. For example, you can load a model in 4-bit, and then enable BetterTransformer with FlashAttention:
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
# load model in 4-bit
quantization_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_compute_dtype=torch.float16
)
tokenizer = AutoTokenizer.from_pretrained("facebook/opt-350m")
model = AutoModelForCausalLM.from_pretrained("facebook/opt-350m", quantization_config=quantization_config)
# enable BetterTransformer
model = model.to_bettertransformer()
input_text = "Hello my dog is cute and"
inputs = tokenizer(input_text, return_tensors="pt").to("cuda")
# enable FlashAttention
with torch.backends.cuda.sdp_kernel(enable_flash=True, enable_math=False, enable_mem_efficient=False):
outputs = model.generate(**inputs)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))