Transformers documentation
DiT
This model was released on 2022-03-04 and added to Hugging Face Transformers on 2022-03-10.
DiT
DiT is an image transformer pretrained on large-scale unlabeled document images. It learns to predict the missing visual tokens from a corrupted input image. The pretrained DiT model can be used as a backbone in other models for visual document tasks like document image classification and table detection.
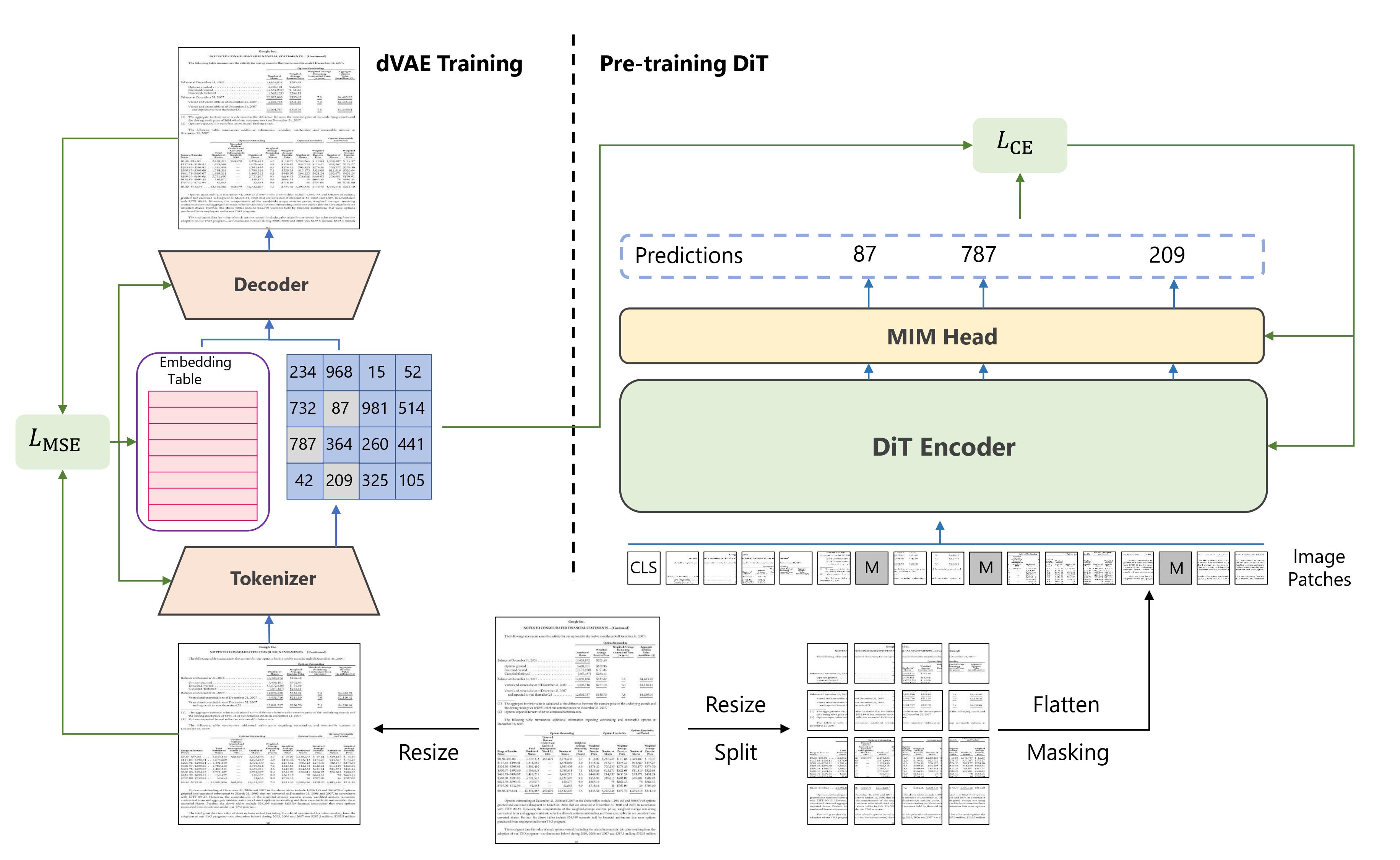
You can find all the original DiT checkpoints under the Microsoft organization.
Refer to the BEiT docs for more examples of how to apply DiT to different vision tasks.
The example below demonstrates how to classify an image with Pipeline or the AutoModel class.
import torch
from transformers import pipeline
pipeline = pipeline(
task="image-classification",
model="microsoft/dit-base-finetuned-rvlcdip",
dtype=torch.float16,
device=0
)
pipeline("https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/model_doc/dit-example.jpg")Notes
The pretrained DiT weights can be loaded in a [BEiT] model with a modeling head to predict visual tokens.
from transformers import BeitForMaskedImageModeling model = BeitForMaskedImageModeling.from_pretraining("microsoft/dit-base")
Resources
- Refer to this notebook for a document image classification inference example.