Inference Endpoints (dedicated) documentation
Advanced Setup (Instance Types, Auto Scaling, Versioning)
Advanced Setup (Instance Types, Auto Scaling, Versioning)
We have seen how fast and easy it is to deploy an Endpoint in Create your first Endpoint, but that’s not all you can manage. During the creation process and after selecting your Cloud Provider and Region, click on the [Advanced configuration] button to reveal further configuration options for your Endpoint.
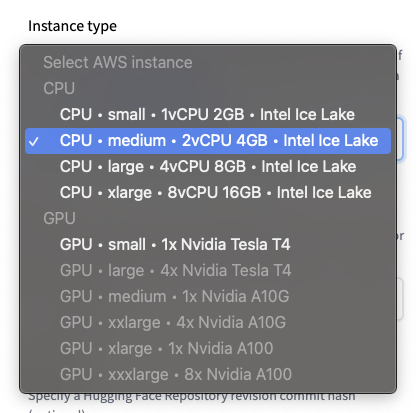
Instance type
🤗 Inference Endpoints offers a selection of curated CPU and GPU instances.
Note: Your Hugging Face account comes with a capacity quota for CPU and GPU instances. To increase your quota or request new instance types, please check with us.
Default: CPU-medium
Replica autoscaling
Set the range (minimum (>=1) and maximum ) of replicas you want your Endpoint to automatically scale within based on utilization.
Default: min 1; max 2
Task
Select a supported Machine Learning Task, or set to Custom. Custom can/should be used when you are not using a Transformers-based model or when you want to customize the inference pipeline, see Create your own Inference handler.
Default: derived from the model repository.
Framework
For Transformers models, if both PyTorch and TensorFlow weights are available, you can select which model weights to use. This will help reduce the image artifact size and accelerate startups/scaling of your endpoints.
Default: PyTorch if available.
Revision
Create your Endpoint targeting a specific revision commit for its source Hugging Face Model Repository. This allows you to version your endpoint and make sure you are always using the same weights even if you are updating the Model Repository.
Default: The most recent commit.
Image
Allows you to provide a custom container image you want to deploy into an Endpoint. Those can be public images, e.g tensorflow/serving:2.7.3, or private Images hosted on Docker hub, AWS ECR, Azure ACR, or Google GCR.
More on how to “Use your own custom container” below.
< > Update on GitHub