Inference Endpoints (dedicated) documentation
Pricing
Pricing
Easily deploy machine learning models on dedicated infrastructure with 🤗 Inference Endpoints. When you create an Endpoint, you can select the instance type to deploy and scale your model according to an hourly rate. 🤗 Inference Endpoints is accessible to Hugging Face accounts with an active subscription and credit card on file. At the end of the subscription period, the user or organization account will be charged for the compute resources used while successfully deployed Endpoints (ready to serve) are initializing and in a running state.
You can find the hourly pricing for all available instances for 🤗 Inference Endpoints, and examples of how costs are calculated below. While the prices are shown by the hour, the actual cost is calculated by the minute.
CPU Instances
The table below shows currently available CPU instances and their hourly pricing. If the instance type cannot be selected in the application, you need to request a quota to use it.
| Provider | Instance Type | Instance Size | Hourly rate | vCPUs | Memory | Architecture |
|---|---|---|---|---|---|---|
| aws | intel-spr | x1 | $0.033 | 1 | 2 GB | Intel Sapphire Rapids |
| aws | intel-spr | x2 | $0.067 | 2 | 4 GB | Intel Sapphire Rapids |
| aws | intel-spr | x4 | $0.134 | 4 | 8 GB | Intel Sapphire Rapids |
| aws | intel-spr | x8 | $0.268 | 8 | 16 GB | Intel Sapphire Rapids |
| aws | intel-spr | x16 | $0.536 | 16 | 32 GB | Intel Sapphire Rapids |
| azure | intel-xeon | x1 | $0.060 | 1 | 2 GB | Intel Xeon |
| azure | intel-xeon | x2 | $0.120 | 2 | 4 GB | Intel Xeon |
| azure | intel-xeon | x4 | $0.240 | 4 | 8 GB | Intel Xeon |
| azure | intel-xeon | x8 | $0.480 | 8 | 16 GB | Intel Xeon |
| gcp | intel-spr | x1 | $0.050 | 1 | 2 GB | Intel Sapphire Rapids |
| gcp | intel-spr | x2 | $0.100 | 2 | 4 GB | Intel Sapphire Rapids |
| gcp | intel-spr | x4 | $0.200 | 4 | 8 GB | Intel Sapphire Rapids |
| gcp | intel-spr | x8 | $0.400 | 8 | 16 GB | Intel Sapphire Rapids |
| aws | intel-icl | x1 | $0.032 | 1 | 2 GB | Intel Ice Lake - Deprecated from July 2025 |
| aws | intel-icl | x2 | $0.064 | 2 | 4 GB | Intel Ice Lake - Deprecated from July 2025 |
| aws | intel-icl | x4 | $0.128 | 4 | 8 GB | Intel Ice Lake - Deprecated from July 2025 |
| aws | intel-icl | x8 | $0.256 | 8 | 16 GB | Intel Ice Lake - Deprecated from July 2025 |
GPU Instances
The table below shows currently available GPU instances and their hourly pricing. If the instance type cannot be selected in the application, you need to request a quota to use it.
| Provider | Instance Type | Instance Size | Hourly rate | GPUs | Memory | Architecture |
|---|---|---|---|---|---|---|
| aws | nvidia-t4 | x1 | $0.5 | 1 | 14 GB | NVIDIA T4 |
| aws | nvidia-t4 | x4 | $3 | 4 | 56 GB | NVIDIA T4 |
| aws | nvidia-l4 | x1 | $0.8 | 1 | 24 GB | NVIDIA L4 |
| aws | nvidia-l4 | x4 | $3.8 | 4 | 96 GB | NVIDIA L4 |
| aws | nvidia-a10g | x1 | $1 | 1 | 24 GB | NVIDIA A10G |
| aws | nvidia-a10g | x4 | $5 | 4 | 96 GB | NVIDIA A10G |
| aws | nvidia-l40s | x1 | $1.8 | 1 | 48 GB | NVIDIA L40S |
| aws | nvidia-l40s | x4 | $8.3 | 4 | 192 GB | NVIDIA L40S |
| aws | nvidia-l40s | x8 | $23.5 | 8 | 384 GB | NVIDIA L40S |
| aws | nvidia-a100 | x1 | $2.5 | 1 | 80 GB | NVIDIA A100 |
| aws | nvidia-a100 | x2 | $5 | 2 | 160 GB | NVIDIA A100 |
| aws | nvidia-a100 | x4 | $10 | 4 | 320 GB | NVIDIA A100 |
| aws | nvidia-a100 | x8 | $20 | 8 | 640 GB | NVIDIA A100 |
| aws | nvidia-h200 | x1 | $5 | 1 | 141 GB | NVIDIA H200 |
| aws | nvidia-h200 | x2 | $10 | 2 | 282 GB | NVIDIA H200 |
| aws | nvidia-h200 | x4 | $20 | 4 | 564 GB | NVIDIA H200 |
| aws | nvidia-h200 | x8 | $40 | 8 | 1128 GB | NVIDIA H200 |
| gcp | nvidia-t4 | x1 | $0.5 | 1 | 16 GB | NVIDIA T4 |
| gcp | nvidia-l4 | x1 | $0.7 | 1 | 24 GB | NVIDIA L4 |
| gcp | nvidia-l4 | x4 | $3.8 | 4 | 96 GB | NVIDIA L4 |
| gcp | nvidia-a100 | x1 | $3.6 | 1 | 80 GB | NVIDIA A100 |
| gcp | nvidia-a100 | x2 | $7.2 | 2 | 160 GB | NVIDIA A100 |
| gcp | nvidia-a100 | x4 | $14.4 | 4 | 320 GB | NVIDIA A100 |
| gcp | nvidia-a100 | x8 | $28.8 | 8 | 640 GB | NVIDIA A100 |
| gcp | nvidia-h100 | x1 | $10 | 1 | 80 GB | NVIDIA H100 |
| gcp | nvidia-h100 | x2 | $20 | 2 | 160 GB | NVIDIA H100 |
| gcp | nvidia-h100 | x4 | $40 | 4 | 320 GB | NVIDIA H100 |
| gcp | nvidia-h100 | x8 | $80 | 8 | 640 GB | NVIDIA H100 |
Accelerator Instances
The table below shows currently available custom Accelerators instances and their hourly pricing. If the instance type cannot be selected in the application, you need to request a quota to use it.
| Provider | Instance Type | Instance Size | Hourly rate | Accelerators | Accelerator Memory | RAM | Architecture |
|---|---|---|---|---|---|---|---|
| aws | inf2 | x1 | $0.75 | 1 | 32 GB | 14.5 GB | AWS Inferentia2 |
| aws | inf2 | x12 | $12 | 12 | 384 GB | 760 GB | AWS Inferentia2 |
| gcp | tpu | 1x1 | $1.2 | 1 | 16 GB | 44 GB | Google TPU v5e |
| gcp | tpu | 2x2 | $4.75 | 4 | 64 GB | 186 GB | Google TPU v5e |
| gcp | tpu | 2x4 | $9.5 | 8 | 128 GB | 380 GB | Google TPU v5e |
Pricing examples
The following example pricing scenarios demonstrate how costs are calculated. You can find the hourly rate for all instance types and sizes in the tables above. Use the following formula to calculate the costs:
instance hourly rate * ((hours * # min replica) + (scale-up hrs * # additional replicas))Basic Endpoint
- AWS CPU intel-spr x2 (2x vCPUs 4GB RAM)
- Autoscaling (minimum 1 replica, maximum 1 replica)
hourly cost
instance hourly rate * (hours * # min replica) = hourly cost
$0.067/hr * (1hr * 1 replica) = $0.067/hrmonthly cost
instance hourly rate * (hours * # min replica) = monthly cost
$0.064/hr * (730hr * 1 replica) = $46.72/month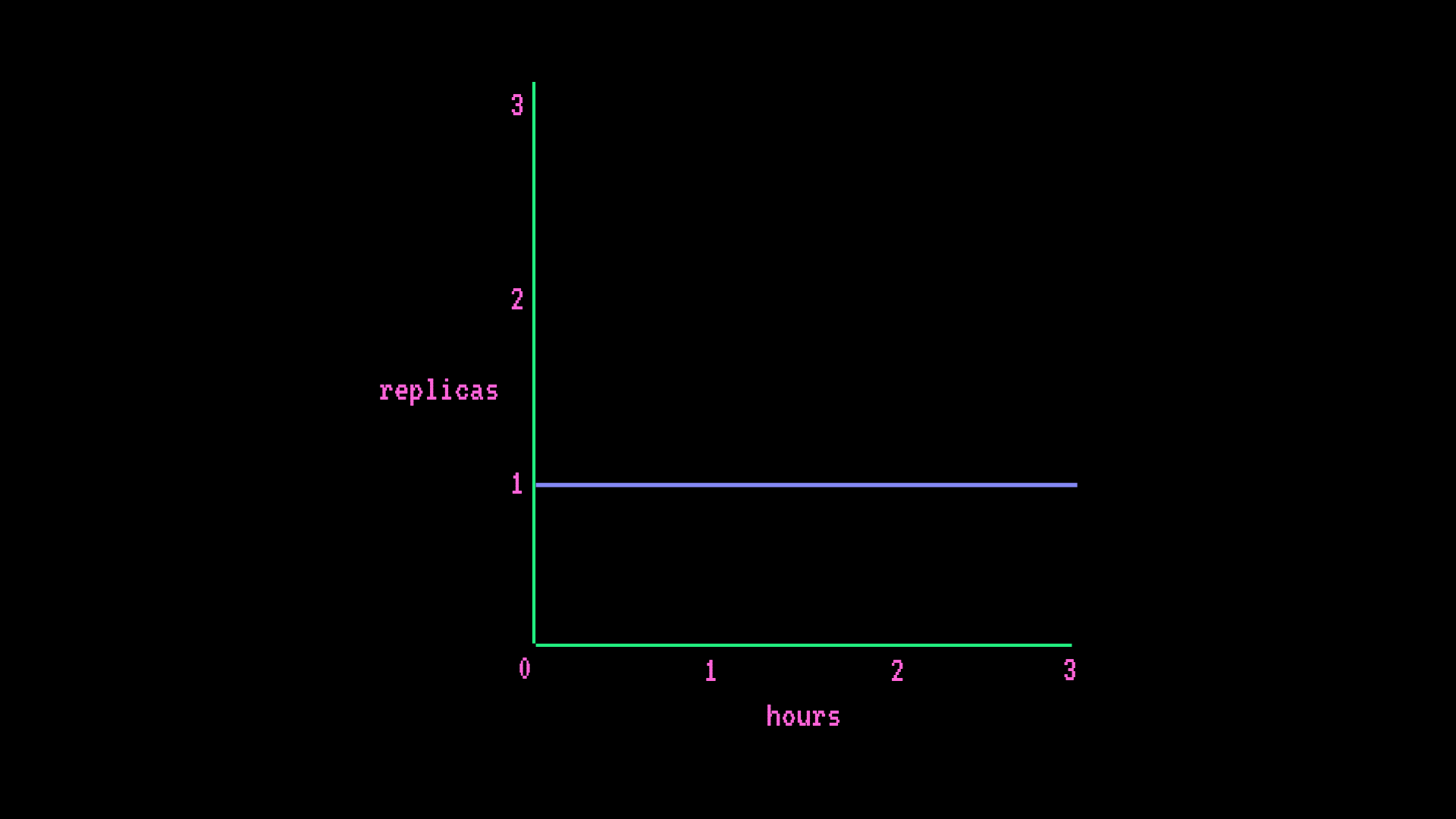
Advanced Endpoint
- AWS GPU small (1x GPU 14GB RAM)
- Autoscaling (minimum 1 replica, maximum 3 replica), every hour a spike in traffic scales the Endpoint from 1 to 3 replicas for 15 minutes
hourly cost
instance hourly rate * ((hours * # min replica) + (scale-up hrs * # additional replicas)) = hourly cost
$0.5/hr * ((1hr * 1 replica) + (0.25hr * 2 replicas)) = $0.75/hrmonthly cost
instance hourly rate * ((hours * # min replica) + (scale-up hrs * # additional replicas)) = monthly cost
$0.5/hr * ((730hr * 1 replica) + (182.5hr * 2 replicas)) = $547.5/month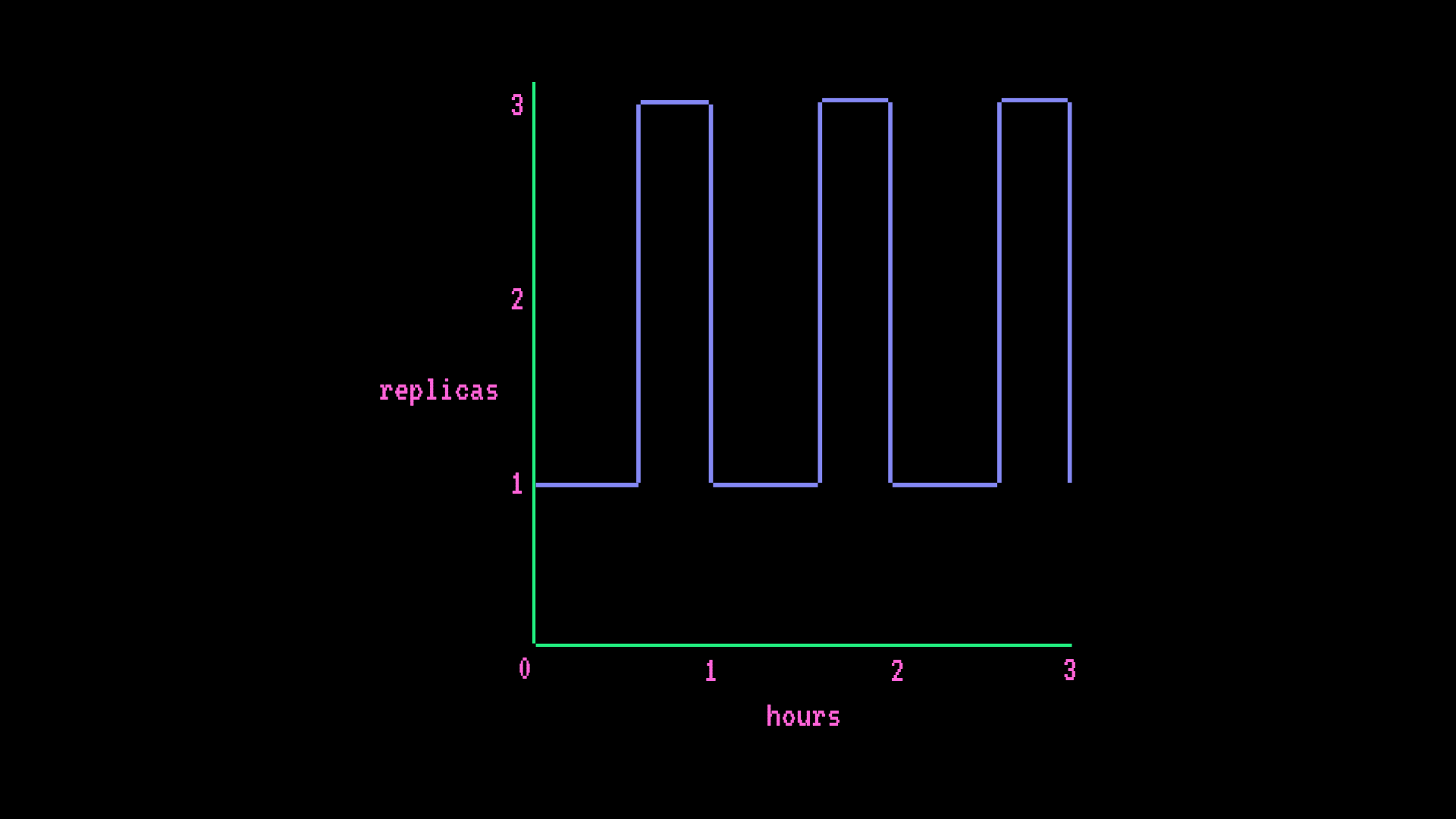
Quotas
Listed available quota can now be seen in the Inference dashboard at https://ui.endpoints.huggingface.co under “Quotas Used”.
The number displayed will reference the number of instances used / available instance quota. Paused endpoints will not count against “used” quota. Scaled to Zero endpoints will be counted as “used” quota - simply pause the scaled-to-zero endpoint should you like to unlock this quota.
Please contact us if you’d like to increase quota allocations. PRO users and Enterprise Hub organizations will have access to higher quota amounts when requested.
< > Update on GitHub