Inference Endpoints (dedicated) documentation
Build and deploy your own chat application
Build and deploy your own chat application
This tutorial will guide you from end to end on how to deploy your own chat application using Hugging Face Inference Endpoints. We will use Gradio to create a chat interface and an OpenAI client to connect to the Inference Endpoint.
This Tutorial uses Python, but your client can be any language that can make HTTP requests. The model and engine you deploy on Inference Endpoints uses the OpenAI Chat Completions format, so you can use any OpenAI client to connect to them, in languages like JavaScript, Java, and Go.
Create your Inference Endpoint
First, we need to create an Inference Endpoint for a model that can chat.
Start by navigating to the Inference Endpoints UI, and once you have logged in you should see a button for creating a new Inference Endpoint. Click the “New” button.
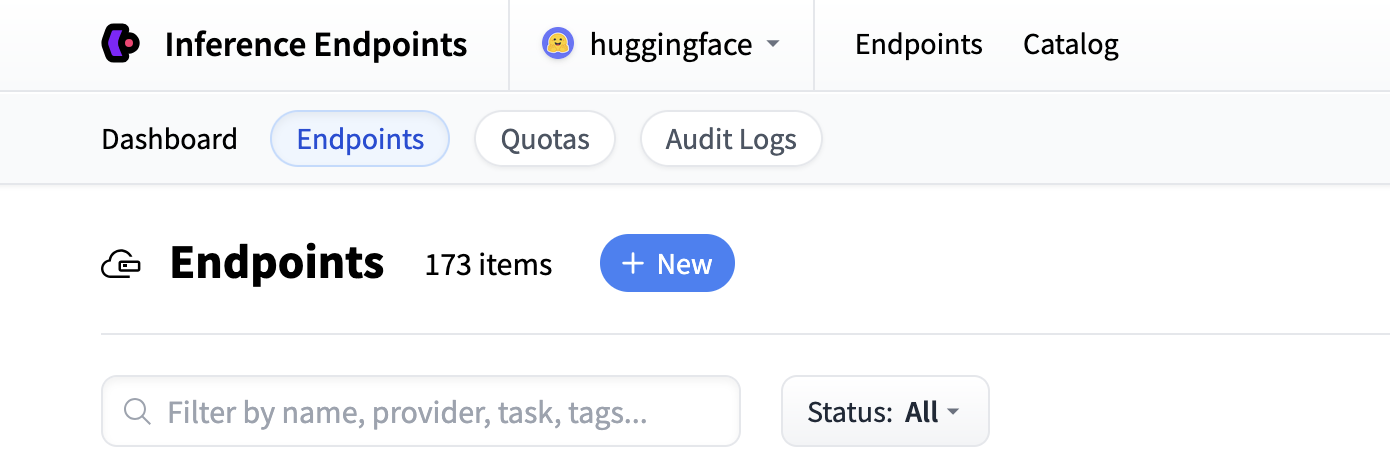
From there you’ll be directed to the catalog. The Model Catalog consists of popular models which have tuned configurations to work just as one-click deploys. You can filter by name, task, price of the hardware and much more.
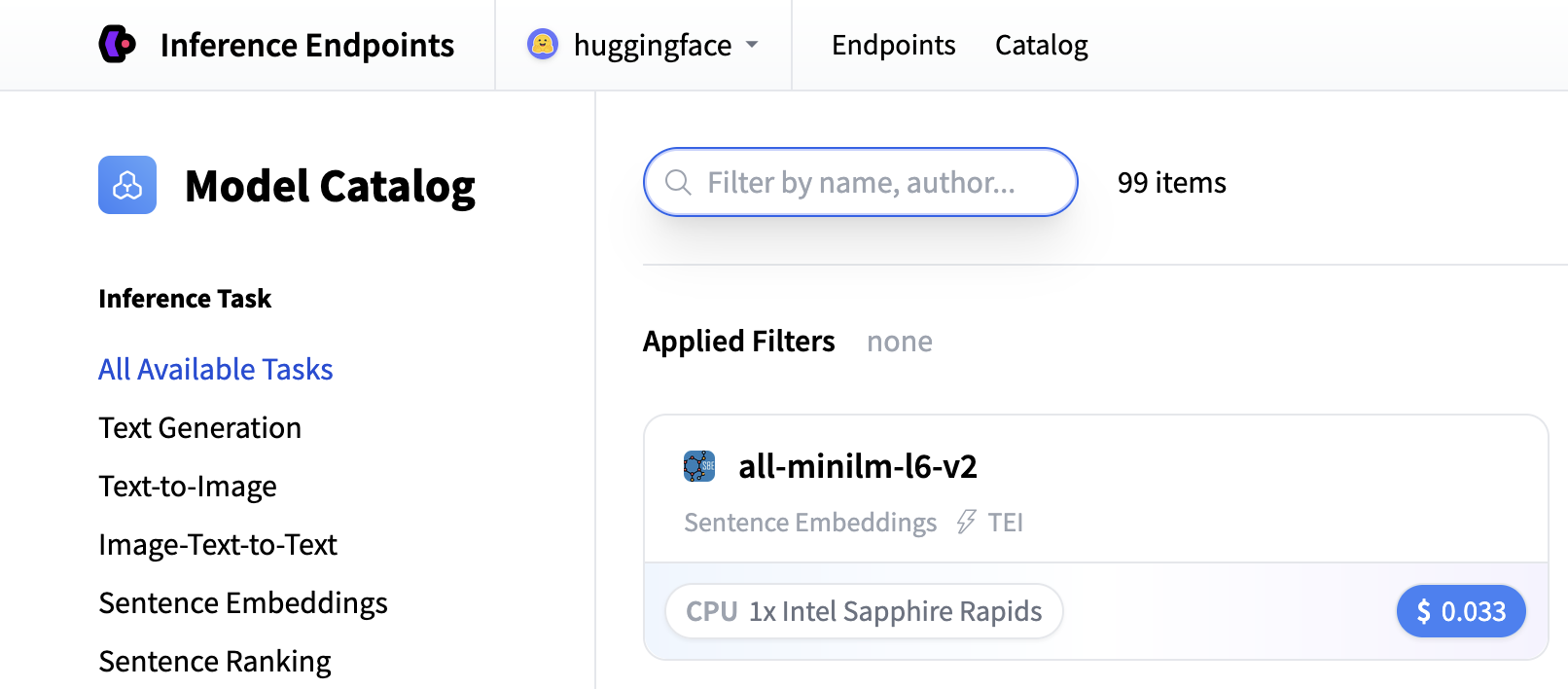
In this example let’s deploy the Qwen/Qwen3-1.7B model. You can find
it by searching for qwen3 1.7b in the search field and deploy it by clicking the card.
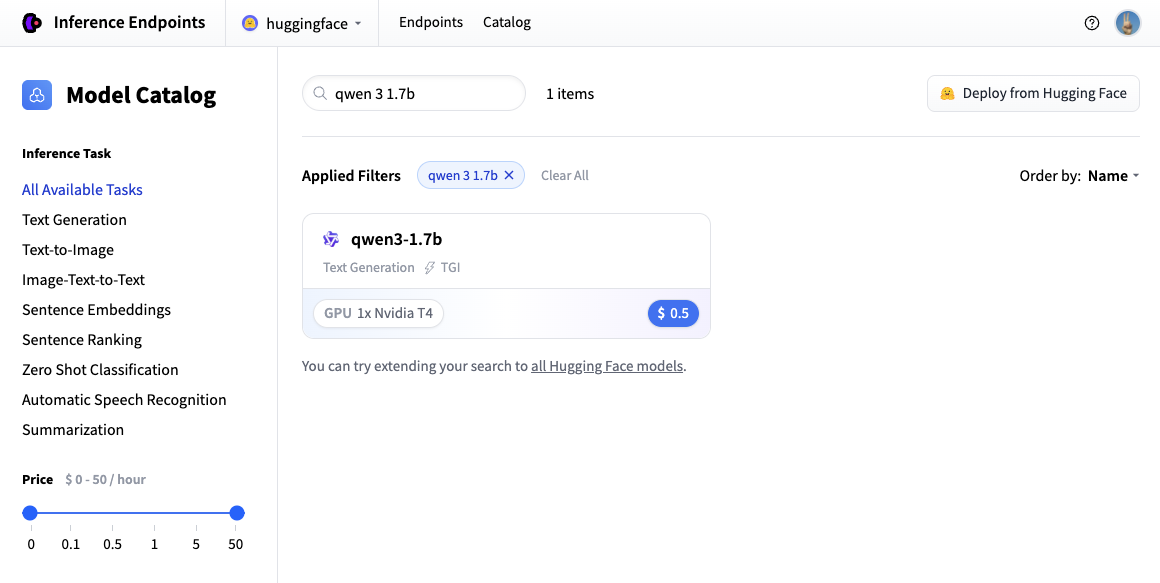
Next we’ll choose which hardware and deployment settings we’ll go for. Since this is a catalog model, all of the pre-selected options are very good defaults. So in this case we don’t need to change anything. In case you want a deeper dive on what the different settings mean you can check out the configuration guide.
For this model the Nvidia L4 is the recommended choice. It will be perfect for our testing. Performant but still reasonably priced. Also note that by default the endpoint will scale down to zero, meaning it will become idle after 1h of inactivity.
Now all you need to do is click click “Create Endpoint” 🚀
Now our Inference Endpoint is initializing, which usually takes about 3-5 minutes. If you want to can allow browser notifications which will give you a ping once the endpoint reaches a running state.
Test your Inference Endpoint in the browser
Now that we’ve created our Inference Endpoint, we can test it in the playground section.
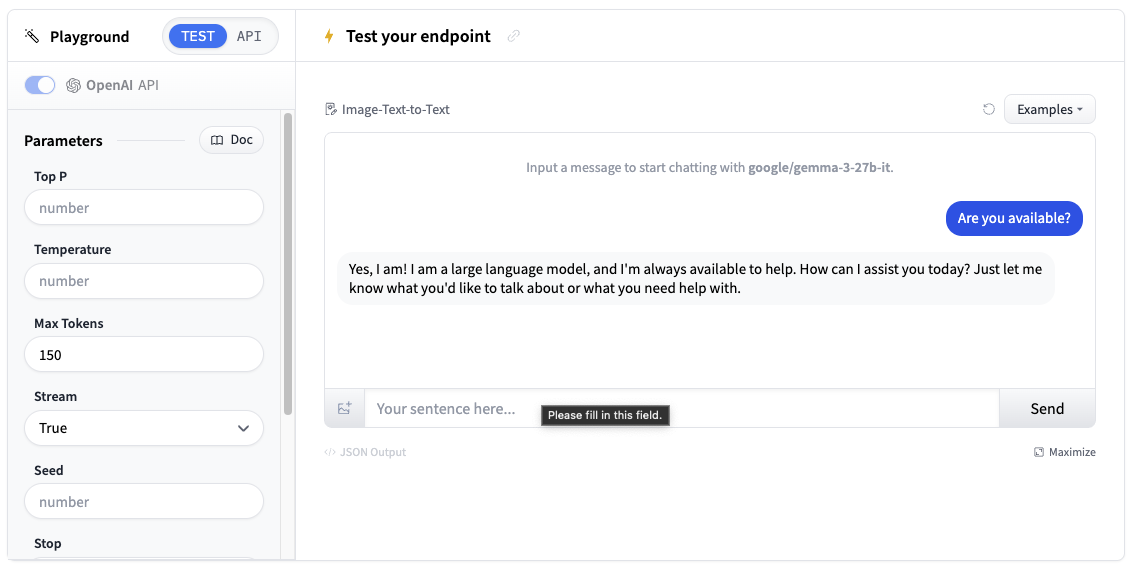
You can use the model through a chat interface or copy code snippets to use it in your own application.
Get your Inference Endpoint details
We need to grab details of our Inference Endpoint, which we can find in the Endpoint’s Overview. We will need the following details:
- The base URL of the endpoint plus the version of the OpenAI API (e.g.
https://<id>.<region>.<cloud>.endpoints.huggingface.cloud/v1/) - The name of the endpoint to use (e.g.
qwen3-1-7b-xll) - The token to use for authentication (e.g.
hf_<token>)
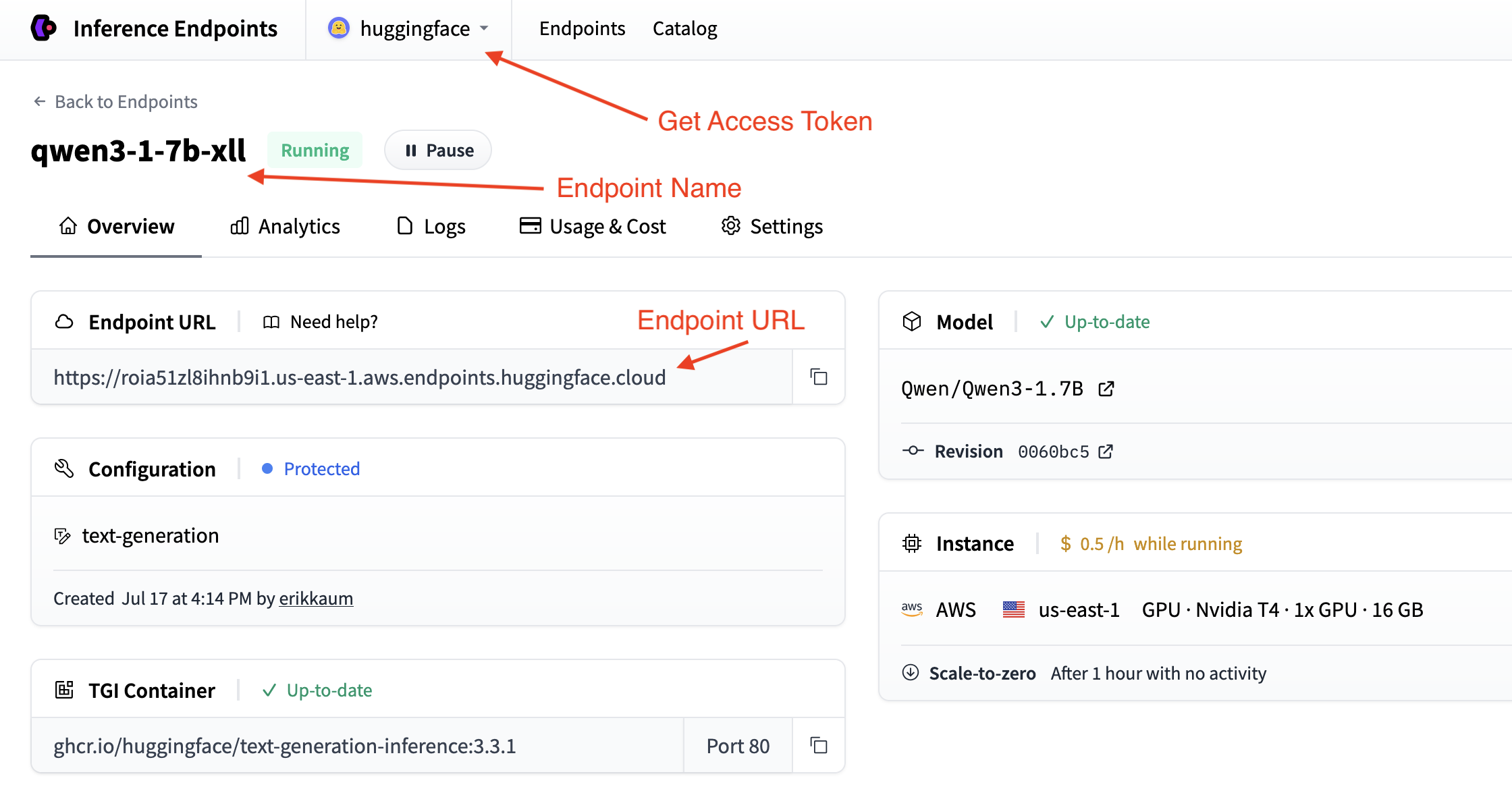
We can find the token in your account settings which is accessible from the top dropdown and clicking on your account name.
Deploy in a few lines of code
The easiest way to deploy a chat application with Gradio is to use the convenient load_chat method. This abstracts everything away and you can have a working chat application quickly.
import os
import gradio as gr
gr.load_chat(
base_url="<endpoint-url>/v1/", # Replace with your endpoint URL + version
model="endpoint-name", # Replace with your endpoint name
token=os.getenv("HF_TOKEN"), # Replace with your token
).launch()The load_chat method won’t cater for your production needs, but it’s a great way to get started and test your application.
Build your own custom chat application
If you want more control over your chat application, you can build your own custom chat interface with Gradio. This gives you more flexibility to customize the behavior, add features, and handle errors.
Choose your preferred method for connecting to Inference Endpoints:
Using Hugging Face InferenceClient
First, install the required dependencies:
pip install gradio huggingface-hub
The Hugging Face InferenceClient provides a clean interface that’s compatible with the OpenAI API format:
import os
import gradio as gr
from huggingface_hub import InferenceClient
# Initialize the Hugging Face InferenceClient
client = InferenceClient(
base_url="<endpoint-url>/v1/", # Replace with your endpoint URL
token=os.getenv("HF_TOKEN") # Use environment variable for security
)
def chat_with_hf_client(message, history):
# Convert Gradio history to messages format
messages = [{"role": msg["role"], "content": msg["content"]} for msg in history]
# Add the current message
messages.append({"role": "user", "content": message})
# Create chat completion
chat_completion = client.chat.completions.create(
model="endpoint-name", # Use the name of your endpoint (i.e. qwen3-1.7b-instruct-xxxx)
messages=messages,
max_tokens=150,
temperature=0.7,
)
# Return the response
return chat_completion.choices[0].message.content
# Create the Gradio interface
demo = gr.ChatInterface(
fn=chat_with_hf_client,
type="messages",
title="Custom Chat with Inference Endpoints",
examples=["What is deep learning?", "Explain neural networks", "How does AI work?"]
)
if __name__ == "__main__":
demo.launch()Adding Streaming Support
For a better user experience, you can implement streaming responses. This will require us to handle the messages and yield them to the client.
Here’s how to add streaming to each client:
Hugging Face InferenceClient Streaming
The Hugging Face InferenceClient supports streaming similar to the OpenAI client:
import os
import gradio as gr
from huggingface_hub import InferenceClient
client = InferenceClient(
base_url="<endpoint-url>/v1/",
token=os.getenv("HF_TOKEN")
)
def chat_with_hf_streaming(message, history):
# Convert history to messages format
messages = [{"role": msg["role"], "content": msg["content"]} for msg in history]
messages.append({"role": "user", "content": message})
# Create streaming chat completion
chat_completion = client.chat.completions.create(
model="endpoint-name",
messages=messages,
max_tokens=150,
temperature=0.7,
stream=True # Enable streaming
)
response = ""
for chunk in chat_completion:
if chunk.choices[0].delta.content:
response += chunk.choices[0].delta.content
yield response # Yield partial response for streaming
# Create streaming interface
demo = gr.ChatInterface(
fn=chat_with_hf_streaming,
type="messages",
title="Streaming Chat with Inference Endpoints"
)
demo.launch()Deploy your chat application
Our app will run on port 7860 and look like this:
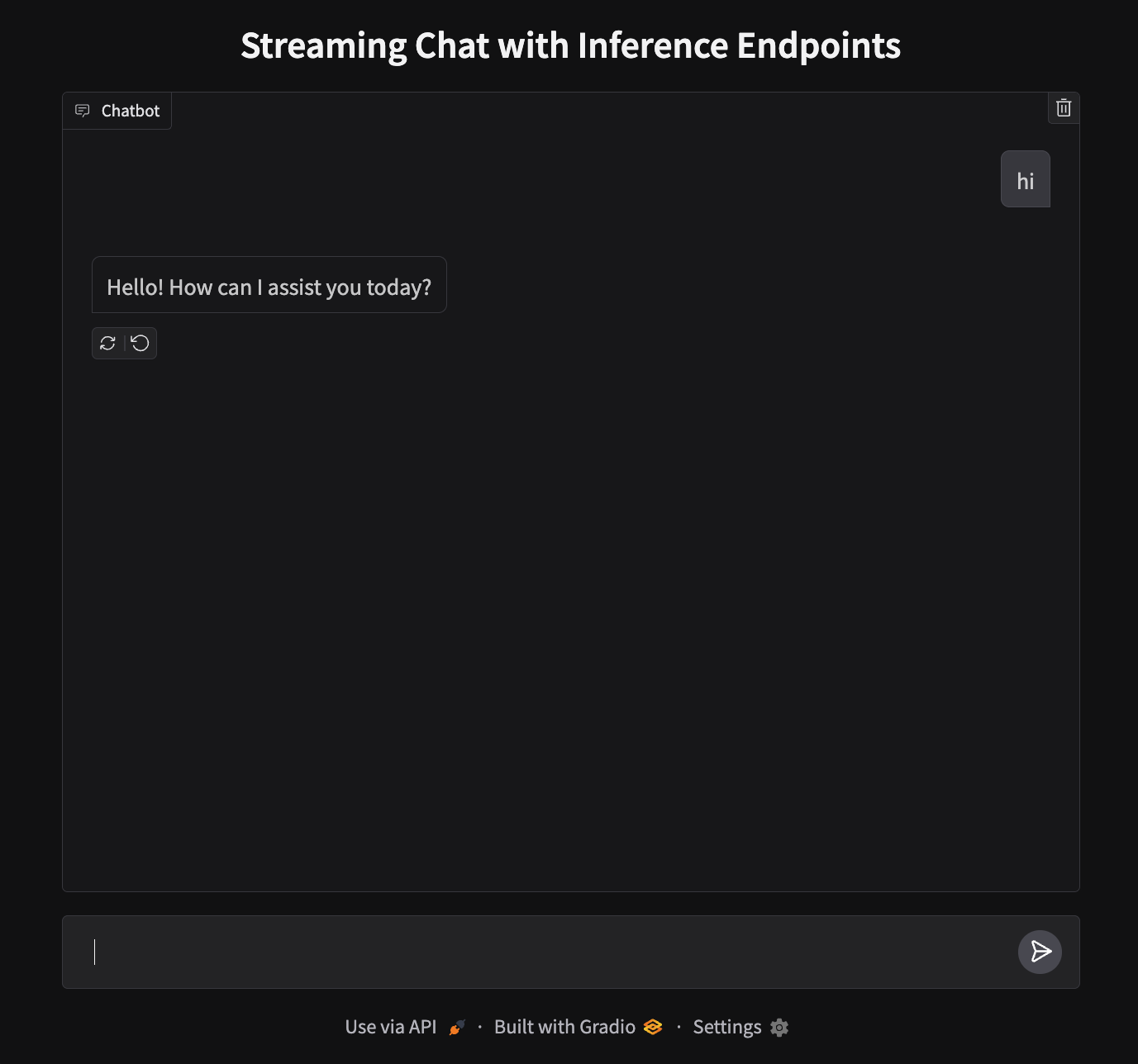
To deploy, we’ll need to create a new Space and upload our files.
- Create a new Space: Go to huggingface.co/new-space
- Choose Gradio SDK and make it public
- Upload your files: Upload
app.py - Add your token: In Space settings, add
HF_TOKENas a secret (get it from your settings) - Launch: Your app will be live at
https://huggingface.co/spaces/your-username/your-space-name
Note: While we used CLI authentication locally, Spaces requires the token as a secret for the deployment environment.
Next steps
That’s it! You now have a chat application running on Hugging Face Spaces powered by Inference Endpoints.
Why not level up and try out the next guide to build a Text-to-Speech application?
Update on GitHub