Diffusers documentation
Multi-instrument Music Synthesis with Spectrogram Diffusion
Multi-instrument Music Synthesis with Spectrogram Diffusion
Overview
Spectrogram Diffusion by Curtis Hawthorne, Ian Simon, Adam Roberts, Neil Zeghidour, Josh Gardner, Ethan Manilow, and Jesse Engel.
An ideal music synthesizer should be both interactive and expressive, generating high-fidelity audio in realtime for arbitrary combinations of instruments and notes. Recent neural synthesizers have exhibited a tradeoff between domain-specific models that offer detailed control of only specific instruments, or raw waveform models that can train on any music but with minimal control and slow generation. In this work, we focus on a middle ground of neural synthesizers that can generate audio from MIDI sequences with arbitrary combinations of instruments in realtime. This enables training on a wide range of transcription datasets with a single model, which in turn offers note-level control of composition and instrumentation across a wide range of instruments. We use a simple two-stage process: MIDI to spectrograms with an encoder-decoder Transformer, then spectrograms to audio with a generative adversarial network (GAN) spectrogram inverter. We compare training the decoder as an autoregressive model and as a Denoising Diffusion Probabilistic Model (DDPM) and find that the DDPM approach is superior both qualitatively and as measured by audio reconstruction and Fréchet distance metrics. Given the interactivity and generality of this approach, we find this to be a promising first step towards interactive and expressive neural synthesis for arbitrary combinations of instruments and notes.
The original codebase of this implementation can be found at magenta/music-spectrogram-diffusion.
Model
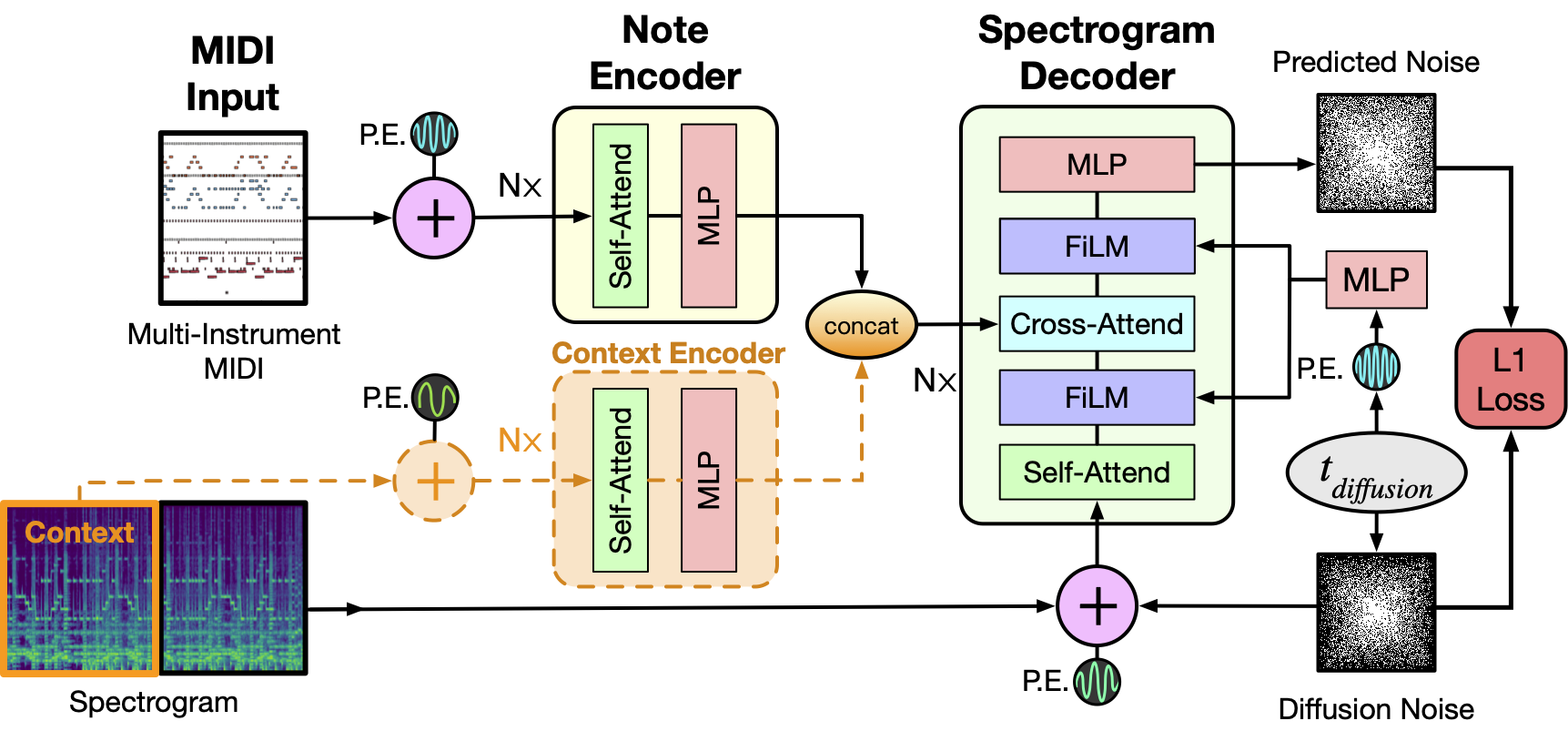
As depicted above the model takes as input a MIDI file and tokenizes it into a sequence of 5 second intervals. Each tokenized interval then together with positional encodings is passed through the Note Encoder and its representation is concatenated with the previous window’s generated spectrogram representation obtained via the Context Encoder. For the initial 5 second window this is set to zero. The resulting context is then used as conditioning to sample the denoised Spectrogram from the MIDI window and we concatenate this spectrogram to the final output as well as use it for the context of the next MIDI window. The process repeats till we have gone over all the MIDI inputs. Finally a MelGAN decoder converts the potentially long spectrogram to audio which is the final result of this pipeline.
Available Pipelines:
| Pipeline | Tasks | Colab |
|---|---|---|
| pipeline_spectrogram_diffusion.py | Unconditional Audio Generation | - |
Example usage
from diffusers import SpectrogramDiffusionPipeline, MidiProcessor
pipe = SpectrogramDiffusionPipeline.from_pretrained("google/music-spectrogram-diffusion")
pipe = pipe.to("cuda")
processor = MidiProcessor()
# Download MIDI from: wget http://www.piano-midi.de/midis/beethoven/beethoven_hammerklavier_2.mid
output = pipe(processor("beethoven_hammerklavier_2.mid"))
audio = output.audios[0]SpectrogramDiffusionPipeline
class diffusers.SpectrogramDiffusionPipeline
< source >( notes_encoder: SpectrogramNotesEncoder continuous_encoder: SpectrogramContEncoder decoder: T5FilmDecoder scheduler: DDPMScheduler melgan: typing.Any )
__call__
< source >( input_tokens: typing.List[typing.List[int]] generator: typing.Optional[torch._C.Generator] = None num_inference_steps: int = 100 return_dict: bool = True output_type: str = 'numpy' callback: typing.Union[typing.Callable[[int, int, torch.FloatTensor], NoneType], NoneType] = None callback_steps: int = 1 )
Linearly scale features to network outputs range.
Invert by linearly scaling network outputs to features range.