Datasets documentation
Share a dataset to the Hub
Share a dataset to the Hub
The Hub is home to an extensive collection of community-curated and popular research datasets. We encourage you to share your dataset to the Hub to help grow the ML community and accelerate progress for everyone. All contributions are welcome; adding a dataset is just a drag and drop away!
Start by creating a Hugging Face Hub account if you don’t have one yet.
Upload with the Hub UI
The Hub’s web-based interface allows users without any developer experience to upload a dataset.
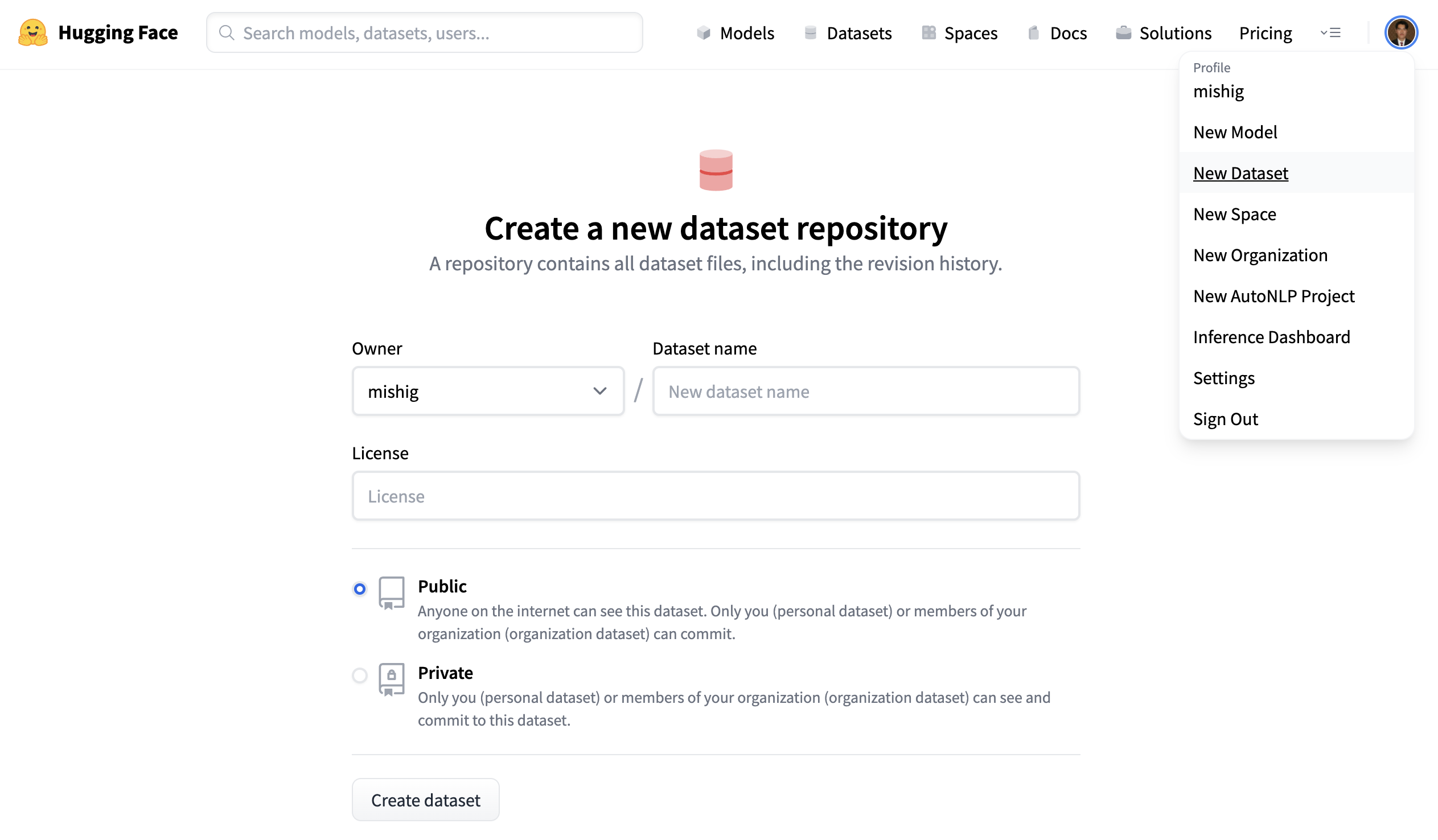
Create a repository
A repository hosts all your dataset files, including the revision history, making storing more than one dataset version possible.
- Click on your profile and select New Dataset to create a new dataset repository.
- Pick a name for your dataset, and choose whether it is a public or private dataset. A public dataset is visible to anyone, whereas a private dataset can only be viewed by you or members of your organization.
Upload dataset
Once you’ve created a repository, navigate to the Files and versions tab to add a file. Select Add file to upload your dataset files. We support many text, audio, and image data extensions such as
.csv,.mp3, and.jpgamong many others. For text data extensions like.csv,.json,.jsonl, and.txt, we recommend compressing them before uploading to the Hub (to.zipor.gzfile extension for example).Text file extensions are not tracked by Git LFS by default, and if they’re greater than 10MB, they will not be committed and uploaded. Take a look at the
.gitattributesfile in your repository for a complete list of tracked file extensions. For this tutorial, you can use the following sample.csvfiles since they’re small: train.csv, test.csv.
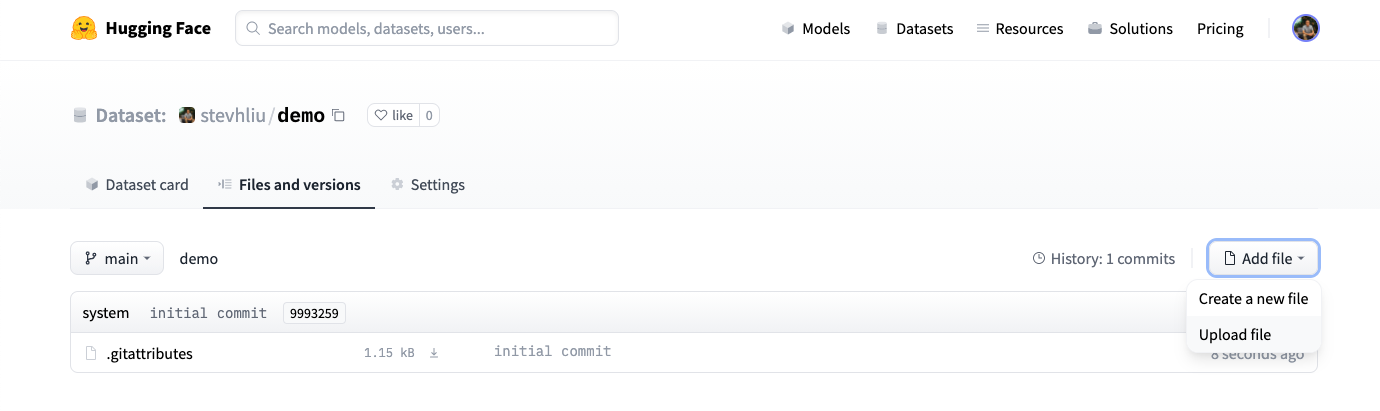
- Drag and drop your dataset files and add a brief descriptive commit message.
- After uploading your dataset files, they are stored in your dataset repository.
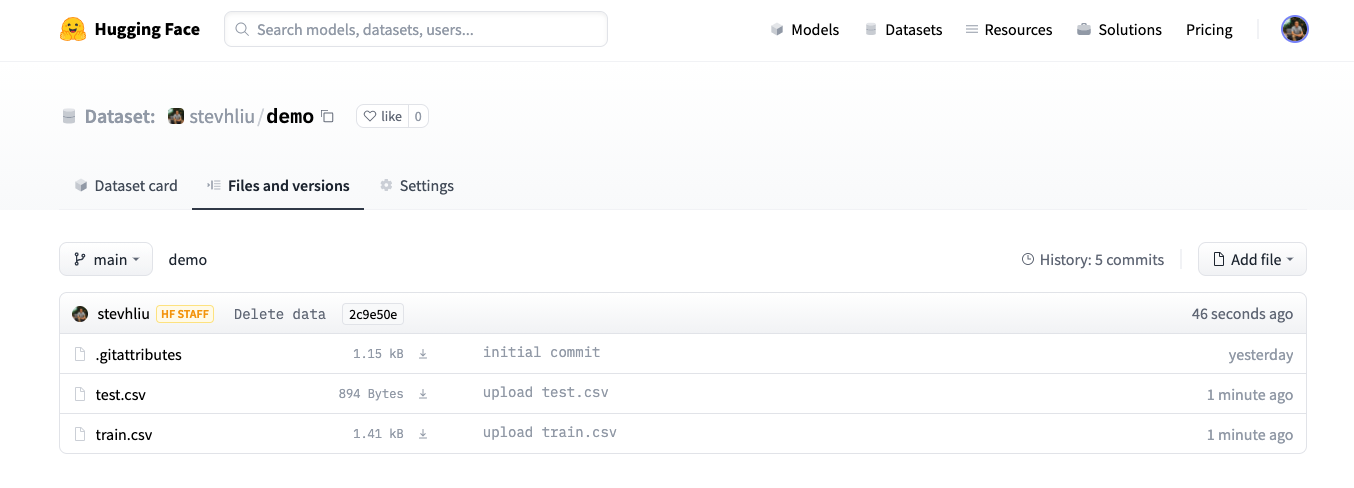
Create a Dataset card
Adding a Dataset card is super valuable for helping users find your dataset and understand how to use it responsibly.
- Click on Create Dataset Card to create a Dataset card. This button creates a
README.mdfile in your repository.
At the top, you’ll see the Metadata UI with several fields to select from like license, language, and task categories. These are the most important tags for helping users discover your dataset on the Hub. When you select an option from each field, they’ll be automatically added to the top of the dataset card.
You can also look at the Dataset Card specifications, which has a complete set of (but not required) tag options like
annotations_creators, to help you choose the appropriate tags.
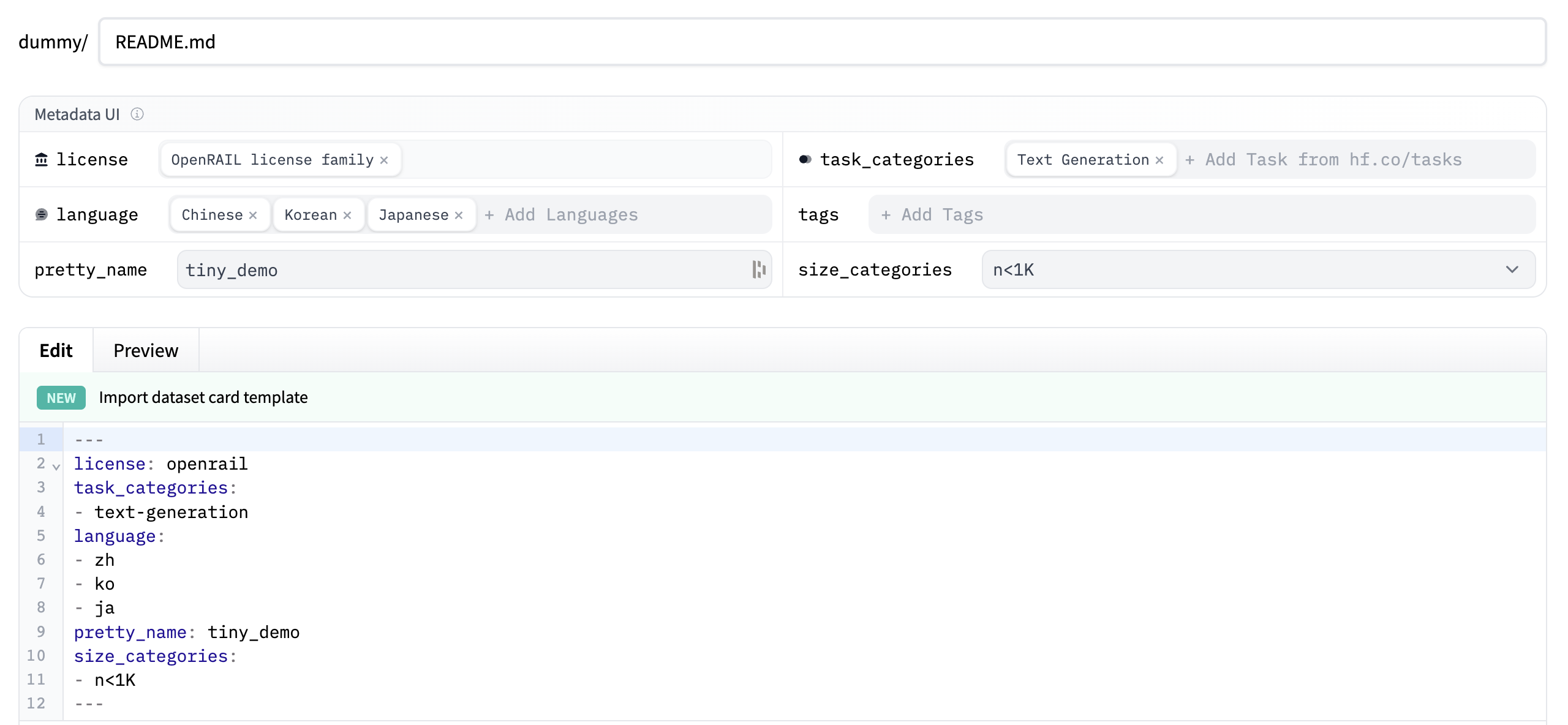
- Click on the Import dataset card template link at the top of the editor to automatically create a dataset card template. Filling out the template is a great way to introduce your dataset to the community and help users understand how to use it. For a detailed example of what a good Dataset card should look like, take a look at the CNN DailyMail Dataset card.
Load dataset
Once your dataset is stored on the Hub, anyone can load it with the load_dataset() function:
>>> from datasets import load_dataset
>>> dataset = load_dataset("stevhliu/demo")Upload with Python
Users who prefer to upload a dataset programmatically can use the huggingface_hub library. This library allows users to interact with the Hub from Python.
- Begin by installing the library:
pip install huggingface_hub
- To upload a dataset on the Hub in Python, you need to log in to your Hugging Face account:
huggingface-cli login
- Use the
push_to_hub()function to help you add, commit, and push a file to your repository:
>>> from datasets import load_dataset
>>> dataset = load_dataset("stevhliu/demo")
# dataset = dataset.map(...) # do all your processing here
>>> dataset.push_to_hub("stevhliu/processed_demo")To set your dataset as private, set the private parameter to True. This parameter will only work if you are creating a repository for the first time.
>>> dataset.push_to_hub("stevhliu/private_processed_demo", private=True)To add a new configuration (or subset) to a dataset or to add a new split (train/validation/test), please refer to the Dataset.push_to_hub() documentation.
Privacy
A private dataset is only accessible by you. Similarly, if you share a dataset within your organization, then members of the organization can also access the dataset.
Load a private dataset by providing your authentication token to the token parameter:
>>> from datasets import load_dataset
# Load a private individual dataset
>>> dataset = load_dataset("stevhliu/demo", token=True)
# Load a private organization dataset
>>> dataset = load_dataset("organization/dataset_name", token=True)What’s next?
Congratulations, you’ve completed the tutorials! 🥳
From here, you can go on to:
- Learn more about how to use 🤗 Datasets other functions to process your dataset.
- Stream large datasets without downloading it locally.
- Define your dataset splits and configurations and share your dataset with the community.
If you have any questions about 🤗 Datasets, feel free to join and ask the community on our forum.
Update on GitHub