Mid-way Recap
Before diving into Q-Learning, let’s summarize what we’ve just learned.
We have two types of value-based functions:
- State-value function: outputs the expected return if the agent starts at a given state and acts according to the policy forever after.
- Action-value function: outputs the expected return if the agent starts in a given state, takes a given action at that state and then acts accordingly to the policy forever after.
- In value-based methods, rather than learning the policy, we define the policy by hand and we learn a value function. If we have an optimal value function, we will have an optimal policy.
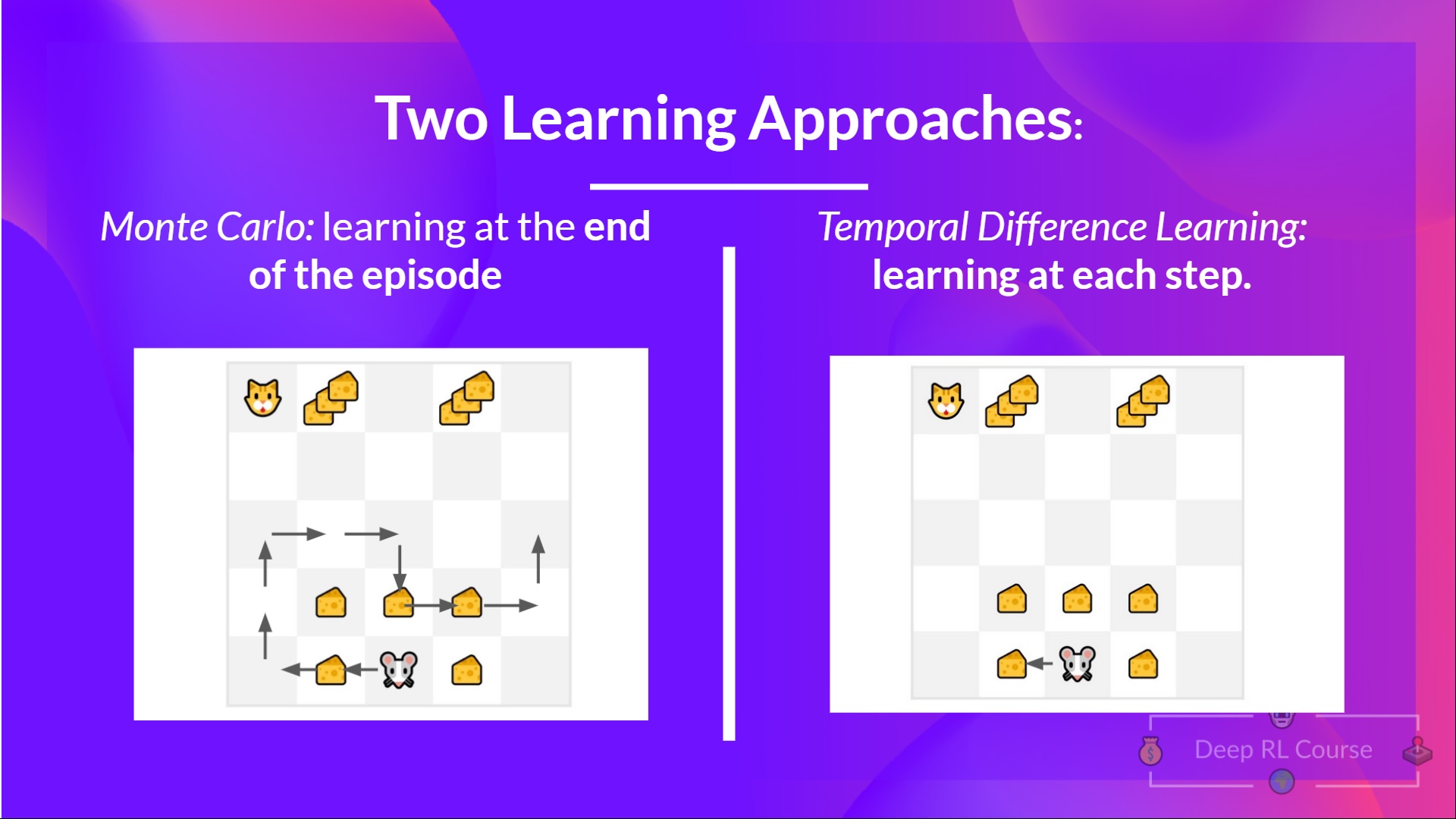
There are two types of methods to update the value function:
- With the Monte Carlo method, we update the value function from a complete episode, and so we use the actual discounted return of this episode.
- With the TD Learning method, we update the value function from a step, replacing the unknown with an estimated return called the TD target.