Datasets:


language:
- fa
license:
- mit
multilinguality:
- monolingual
size_categories:
- 100M<n<1B
task_categories:
- fill-mask
- text-generation
task_ids:
- language-modeling
- masked-language-modeling
pretty_name: naab (A ready-to-use plug-and-play corpus in Farsi)
naab: A ready-to-use plug-and-play corpus in Farsi
[If you want to join our community to keep up with news, models and datasets from naab, click on this link.]
Table of Contents
- Dataset Card Creation Guide
Dataset Description
- Homepage: Sharif Speech and Language Processing Lab
- Paper: naab: A ready-to-use plug-and-play corpus for Farsi
- Point of Contact: Sadra Sabouri
Dataset Summary
naab is the biggest cleaned and ready-to-use open-source textual corpus in Farsi. It contains about 130GB of data, 250 million paragraphs, and 15 billion words. The project name is derived from the Farsi word ناب which means pure and high-grade. We also provide the raw version of the corpus called naab-raw and an easy-to-use pre-processor that can be employed by those who wanted to make a customized corpus.
You can use this corpus by the commands below:
from datasets import load_dataset
dataset = load_dataset("SLPL/naab")
You may need to download parts/splits of this corpus too, if so use the command below (You can find more ways to use it here):
from datasets import load_dataset
dataset = load_dataset("SLPL/naab", split="train[:10%]")
Note: be sure that your machine has at least 130 GB free space, also it may take a while to download. If you are facing disk or internet shortage, you can use below code snippet helping you download your costume sections of the naab:
from datasets import load_dataset
# ==========================================================
# You should just change this part in order to download your
# parts of corpus.
indices = {
"train": [5, 1, 2],
"test": [0, 2]
}
# ==========================================================
N_FILES = {
"train": 126,
"test": 3
}
_BASE_URL = "https://huggingface.co/datasets/SLPL/naab/resolve/main/data/"
data_url = {
"train": [_BASE_URL + "train-{:05d}-of-{:05d}.txt".format(x, N_FILES["train"]) for x in range(N_FILES["train"])],
"test": [_BASE_URL + "test-{:05d}-of-{:05d}.txt".format(x, N_FILES["test"]) for x in range(N_FILES["test"])],
}
for index in indices['train']:
assert index < N_FILES['train']
for index in indices['test']:
assert index < N_FILES['test']
data_files = {
"train": [data_url['train'][i] for i in indices['train']],
"test": [data_url['test'][i] for i in indices['test']]
}
print(data_files)
dataset = load_dataset('text', data_files=data_files, use_auth_token=True)
Supported Tasks and Leaderboards
This corpus can be used for training all language models which can be trained by Masked Language Modeling (MLM) or any other self-supervised objective.
language-modelingmasked-language-modeling
Dataset Structure
Each row of the dataset will look like something like the below:
{
'text': "این یک تست برای نمایش یک پاراگراف در پیکره متنی ناب است.",
}
text: the textual paragraph.
Data Splits
This dataset includes two splits (train and test). We split these two by dividing the randomly permuted version of the corpus into (95%, 5%) division respected to (train, test). Since validation is usually occurring during training with the train dataset we avoid proposing another split for it.
| train | test | |
|---|---|---|
| Input Sentences | 225892925 | 11083849 |
| Average Sentence Length | 61 | 25 |
Below you can see the log-based histogram of word/paragraph over the two splits of the dataset.
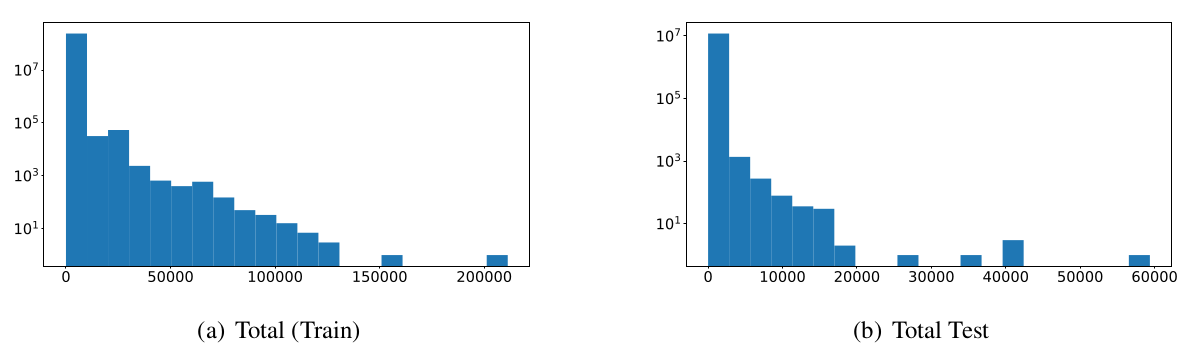
Dataset Creation
Curation Rationale
Due to the lack of a huge amount of text data in lower resource languages - like Farsi - researchers working on these languages were always finding it hard to start to fine-tune such models. This phenomenon can lead to a situation in which the golden opportunity for fine-tuning models is just in hands of a few companies or countries which contributes to the weakening the open science.
The last biggest cleaned merged textual corpus in Farsi is a 70GB cleaned text corpus from a compilation of 8 big data sets that have been cleaned and can be downloaded directly. Our solution to the discussed issues is called naab. It provides 126GB (including more than 224 million sequences and nearly 15 billion words) as the training corpus and 2.3GB (including nearly 11 million sequences and nearly 300 million words) as the test corpus.
Source Data
The textual corpora that we used as our source data are illustrated in the figure below. It contains 5 corpora which are linked in the coming sections.
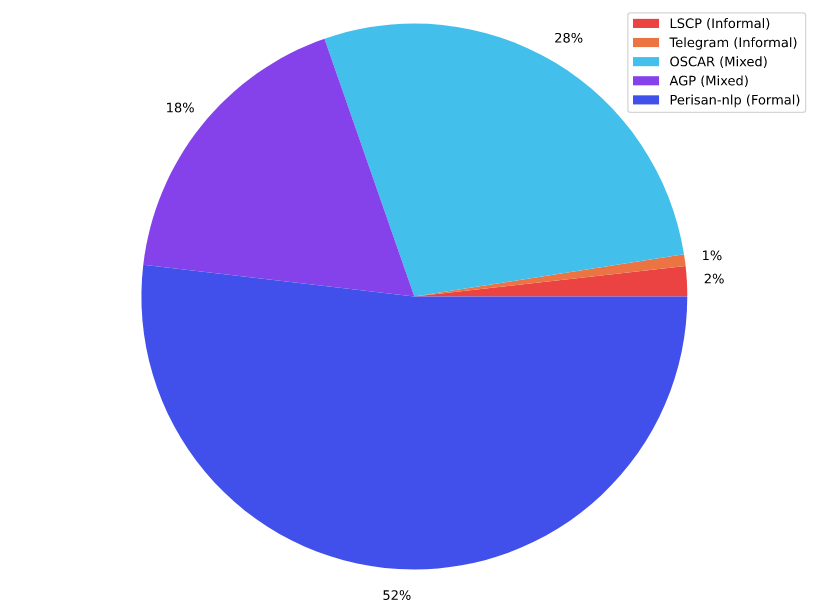
Persian NLP
This corpus includes eight corpora that are sorted based on their volume as below:
- Common Crawl: 65GB (link)
- MirasText: 12G
- W2C – Web to Corpus: 1GB (link)
- Persian Wikipedia (March 2020 dump): 787MB (link)
- Leipzig Corpora: 424M (link)
- VOA corpus: 66MB (link)
- Persian poems corpus: 61MB (link)
- TEP: Tehran English-Persian parallel corpus: 33MB (link)
AGP
This corpus was a formerly private corpus for ASR Gooyesh Pardaz which is now published for all users by this project. This corpus contains more than 140 million paragraphs summed up in 23GB (after cleaning). This corpus is a mixture of both formal and informal paragraphs that are crawled from different websites and/or social media.
OSCAR-fa
OSCAR or Open Super-large Crawled ALMAnaCH coRpus is a huge multilingual corpus obtained by language classification and filtering of the Common Crawl corpus using the go classy architecture. Data is distributed by language in both original and deduplicated form. We used the unshuffled-deduplicated-fa from this corpus, after cleaning there were about 36GB remaining.
Telegram
Telegram, a cloud-based instant messaging service, is a widely used application in Iran. Following this hypothesis, we prepared a list of Telegram channels in Farsi covering various topics including sports, daily news, jokes, movies and entertainment, etc. The text data extracted from mentioned channels mainly contains informal data.
LSCP
The Large Scale Colloquial Persian Language Understanding dataset has 120M sentences from 27M casual Persian sentences with its derivation tree, part-of-speech tags, sentiment polarity, and translations in English, German, Czech, Italian, and Hindi. However, we just used the Farsi part of it and after cleaning we had 2.3GB of it remaining. Since the dataset is casual, it may help our corpus have more informal sentences although its proportion to formal paragraphs is not comparable.
Initial Data Collection and Normalization
The data collection process was separated into two parts. In the first part, we searched for existing corpora. After downloading these corpora we started to crawl data from some social networks. Then thanks to ASR Gooyesh Pardaz we were provided with enough textual data to start the naab journey.
We used a preprocessor based on some stream-based Linux kernel commands so that this process can be less time/memory-consuming. The code is provided here.
Personal and Sensitive Information
Since this corpus is briefly a compilation of some former corpora we take no responsibility for personal information included in this corpus. If you detect any of these violations please let us know, we try our best to remove them from the corpus ASAP.
We tried our best to provide anonymity while keeping the crucial information. We shuffled some parts of the corpus so the information passing through possible conversations wouldn't be harmful.
Additional Information
Dataset Curators
- Sadra Sabouri (Sharif University of Technology)
- Elnaz Rahmati (Sharif University of Technology)
Licensing Information
mit?
Citation Information
@article{sabouri2022naab,
title={naab: A ready-to-use plug-and-play corpus for Farsi},
author={Sabouri, Sadra and Rahmati, Elnaz and Gooran, Soroush and Sameti, Hossein},
journal={arXiv preprint arXiv:2208.13486},
year={2022}
}
DOI: https://doi.org/10.48550/arXiv.2208.13486
Contributions
Thanks to @sadrasabouri and @elnazrahmati for adding this dataset.
Keywords
- Farsi
- Persian
- raw text
- پیکره فارسی
- پیکره متنی
- آموزش مدل زبانی