
Chuxin-1.6B-1M
介绍 (Introduction)
Chuxin-1.6B-Base是16亿参数规模的模型。Chuxin-1.6B完全基于开源数据构建,在经过超大规模数据训练后,Chuxin-1.6B在各类下游任务上具有非常的竞争力。
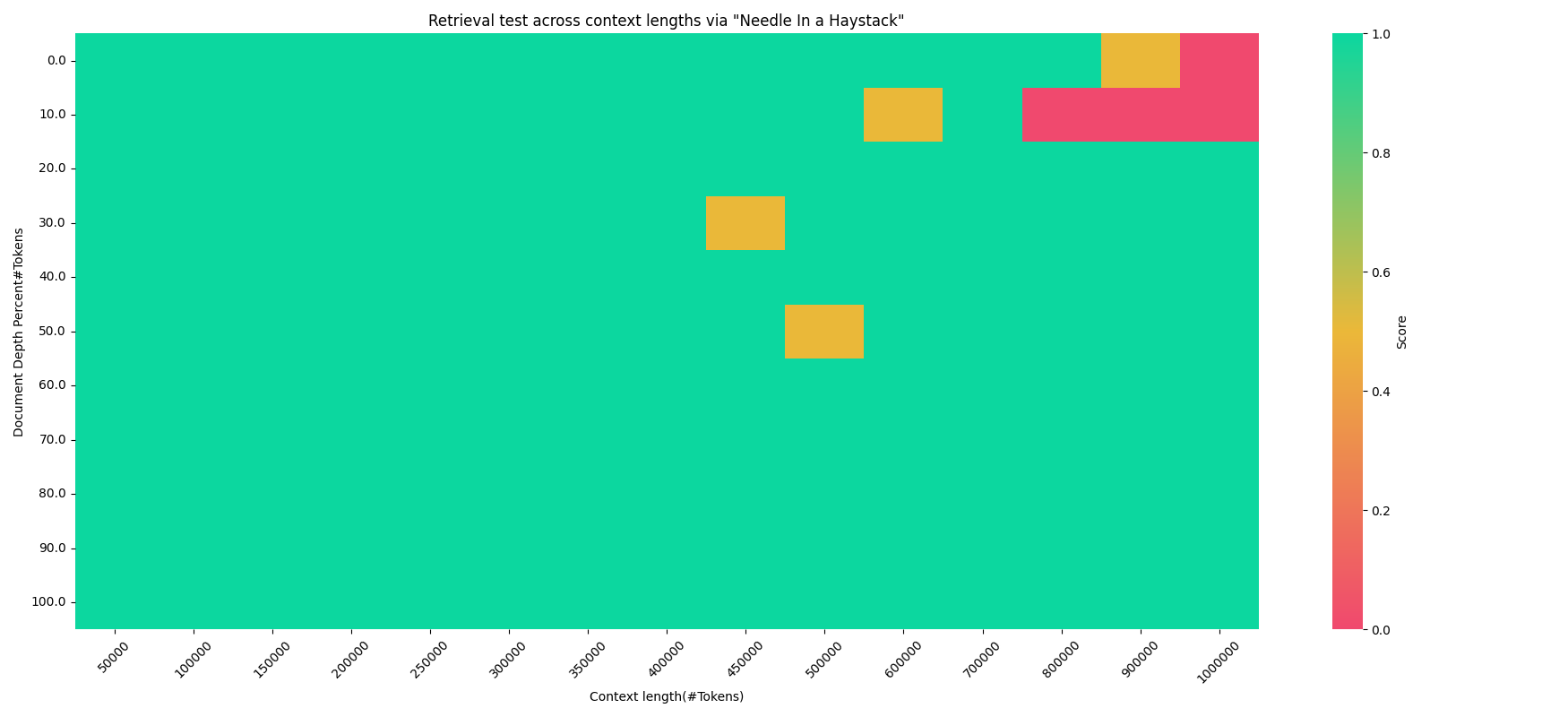
Chuxin-1.6B-1M是基于Chuxin-1.6B模型在1M窗口下训练后的结果,大海捞针实验显示其具有非常强的上下文检索能力。
如果您想了解更多关于Chuxin-1.6B开源模型的细节,我们建议您参阅我们的技术报告
Chuxin-1.6B-Base is a model with 1.6 billion parameters. Chuxin-1.6B is built entirely on open-source data. After being trained with large-scale data, Chuxin has very competitive capabilities in various downstream tasks.
Chuxin-1.6B-1M is the result of training the Chuxin-1.6B model with a 1M windows. Experiments such as searching for a needle in a haystack demonstrate its strong contextual retrieval abilities.
If you would like to learn more about the Chuxin-1.6B open-source model, we suggest you refer to our technical report.
快速使用(Quickstart)
您可以通过以下代码轻松调用:
You can easily call the model with the following code:
from transformers import AutoModelForCausalLM, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("chuxin-llm/Chuxin-1.6B-1M", trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained("chuxin-llm/Chuxin-1.6B-1M", device_map="auto", trust_remote_code=True, bf16=True).eval()
inputs = tokenizer('蒙古国的首都是乌兰巴托(Ulaanbaatar)\n冰岛的首都是雷克雅未克(Reykjavik)\n埃塞俄比亚的首都是', return_tensors='pt')
inputs = inputs.to(model.device)
pred = model.generate(**inputs, max_new_tokens=15, do_sample=False)
print(tokenizer.decode(pred.cpu()[0], skip_special_tokens=True))
# 蒙古国的首都是乌兰巴托(Ulaanbaatar)\n冰岛的首都是雷克雅未克(Reykjavik)\n埃塞俄比亚的首都是亚的斯亚贝巴(Addis Ababa)...
评测效果(Evaluation)
常识推理和阅读理解 (Common Sense Reasoning and Reading Comprehension tasks)
| Model | size | ARC-c | ARC-e | Boolq | Copa | Hellaswag | OpenbookQA | Piqa | Sciq | Winogrande | Avg |
|---|---|---|---|---|---|---|---|---|---|---|---|
| chuxin-1.6B-base | 1.6B | 39.68 | 71.38 | 71.25 | 83 | 66.09 | 35.00 | 77.09 | 95 | 63.54 | 66.89 |
| chuxin-1.6B-32k | 1.6B | 39.16 | 70.66 | 67.71 | 81 | 65.69 | 35.8 | 76.88 | 94.2 | 62.51 | 65.96 |
| chuxin-1.6B-64k | 1.6B | 38.48 | 70.24 | 67.52 | 82 | 65.6 | 35.2 | 76.61 | 94.3 | 63.3 | 65.92 |
| chuxin-1.6B-128k | 1.6B | 39.08 | 69.4 | 67.71 | 80 | 65.74 | 35.4 | 76.39 | 94.1 | 63.3 | 65.68 |
| chuxin-1.6B-256k | 1.6B | 40.19 | 70.75 | 69.3 | 78 | 65.85 | 35.8 | 76.88 | 93.5 | 63.85 | 66.01 |
| chuxin-1.6B-512k | 1.6B | 40.61 | 71.21 | 67.77 | 78 | 64.82 | 34.8 | 76.88 | 93.6 | 61.88 | 65.51 |
| chuxin-1.6B-1M | 1.6B | 41.13 | 72.26 | 62.08 | 75 | 64.59 | 34.8 | 76.71 | 93.33 | 62.43 | 64.7 |
Open LLM LeaderBoard
| Model | size | ARC-c | HellaSwag | MMLU | TruthfulQA | Winogrande | GSM-8k | Avg | Avg wo GSM |
|---|---|---|---|---|---|---|---|---|---|
| chuxin-1.6B-base | 1.6B | 39.68 | 66.09 | 41.07 | 37.65 | 63.54 | 12.66 | 43.45 | 49.61 |
| chuxin-1.6B-32k | 1.6B | 39.16 | 65.69 | 38.63 | 35.66 | 62.51 | 11.6 | 42.21 | 48.33 |
| chuxin-1.6B-64k | 1.6B | 38.48 | 65.6 | 38.43 | 35.07 | 63.3 | 11.9 | 42.13 | 48.18 |
| chuxin-1.6B-128k | 1.6B | 39.08 | 65.74 | 37.65 | 34.89 | 63.3 | 11.07 | 41.96 | 48.13 |
| chuxin-1.6B-256k | 1.6B | 40.19 | 65.85 | 37.16 | 35.2 | 63.85 | 10.16 | 42.07 | 48.45 |
| chuxin-1.6B-512k | 1.6B | 40.61 | 64.82 | 36.66 | 33.66 | 61.88 | 8.11 | 40.96 | 47.53 |
| Chuxin-1.6B-1M | 1.6B | 41.13 | 64.59 | 35.76 | 34.67 | 62.43 | 6.82 | 40.9 | 47.72 |
大海捞针 (needle in a haystack)
引用 (Citation)
如果你觉得我们的工作对你有帮助,欢迎引用!
If you find our work helpful, feel free to give us a cite.
@article{chuxin,
title={CHUXIN: 1.6B TECHNICAL REPORT},
author={Xiaomin Zhuang, Yufan Jiang, Qiaozhi He, Zhihua Wu},
journal={arXiv preprint arXiv:2405.04828},
year={2024}
}
- Downloads last month
- 5