
French Whisper v0.1
Collection
French-optimized Whisper models for speech recognition.
•
6 items
•
Updated
•
4
Whisper-Large-V3-French-Distil represents a series of distilled versions of Whisper-Large-V3-French, achieved by reducing the number of decoder layers from 32 to 16, 8, 4, or 2 and distilling using a large-scale dataset, as outlined in this paper.
The distilled variants reduce memory usage and inference time while maintaining performance (based on the retained number of layers) and mitigating the risk of hallucinations, particularly in long-form transcriptions. Moreover, they can be seamlessly combined with the original Whisper-Large-V3-French model for speculative decoding, resulting in improved inference speed and consistent outputs compared to using the standalone model.
This model has been converted into various formats, facilitating its usage across different libraries, including transformers, openai-whisper, fasterwhisper, whisper.cpp, candle, mlx, etc.
We evaluated our model on both short and long-form transcriptions, and also tested it on both in-distribution and out-of-distribution datasets to conduct a comprehensive analysis assessing its accuracy, generalizability, and robustness.
Please note that the reported WER is the result after converting numbers to text, removing punctuation (except for apostrophes and hyphens), and converting all characters to lowercase.
All evaluation results on the public datasets can be found here.
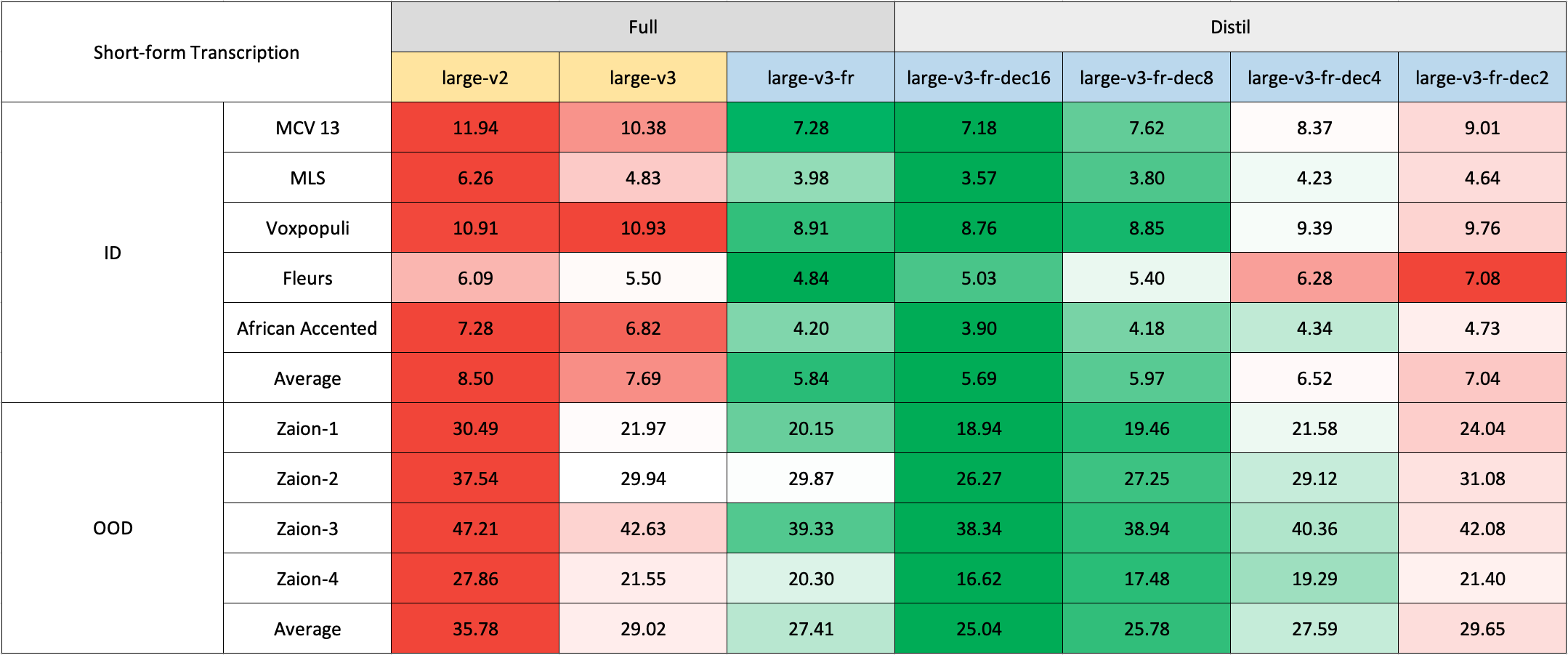
Due to the lack of readily available out-of-domain (OOD) and long-form test sets in French, we evaluated using internal test sets from Zaion Lab. These sets comprise human-annotated audio-transcription pairs from call center conversations, which are notable for their significant background noise and domain-specific terminology.
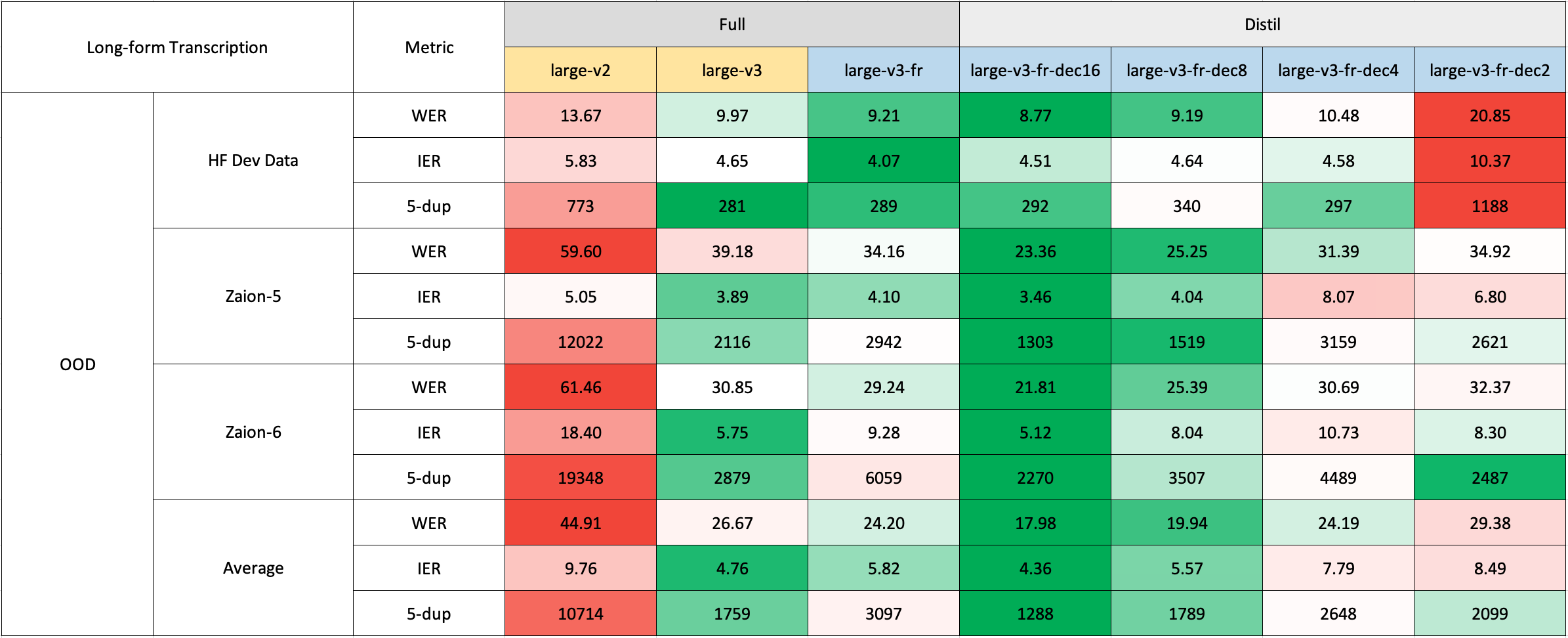
The long-form transcription was run using the 🤗 Hugging Face pipeline for quicker evaluation. Audio files were segmented into 30-second chunks and processed in parallel.
The model can easily used with the 🤗 Hugging Face pipeline class for audio transcription.
For long-form transcription (> 30 seconds), you can activate the process by passing the chunk_length_s argument. This approach segments the audio into smaller segments, processes them in parallel, and then joins them at the strides by finding the longest common sequence. While this chunked long-form approach may have a slight compromise in performance compared to OpenAI's sequential algorithm, it provides 9x faster inference speed.
import torch
from datasets import load_dataset
from transformers import AutoModelForSpeechSeq2Seq, AutoProcessor, pipeline
device = "cuda:0" if torch.cuda.is_available() else "cpu"
torch_dtype = torch.float16 if torch.cuda.is_available() else torch.float32
# Load model
model_name_or_path = "bofenghuang/whisper-large-v3-french-distil-dec16"
processor = AutoProcessor.from_pretrained(model_name_or_path)
model = AutoModelForSpeechSeq2Seq.from_pretrained(
model_name_or_path,
torch_dtype=torch_dtype,
low_cpu_mem_usage=True,
)
model.to(device)
# Init pipeline
pipe = pipeline(
"automatic-speech-recognition",
model=model,
feature_extractor=processor.feature_extractor,
tokenizer=processor.tokenizer,
torch_dtype=torch_dtype,
device=device,
# chunk_length_s=30, # for long-form transcription
max_new_tokens=128,
)
# Example audio
dataset = load_dataset("bofenghuang/asr-dummy", "fr", split="test")
sample = dataset[0]["audio"]
# Run pipeline
result = pipe(sample)
print(result["text"])
You can also use the 🤗 Hugging Face low-level APIs for transcription, offering greater control over the process, as demonstrated below:
import torch
from datasets import load_dataset
from transformers import AutoModelForSpeechSeq2Seq, AutoProcessor
device = "cuda:0" if torch.cuda.is_available() else "cpu"
torch_dtype = torch.float16 if torch.cuda.is_available() else torch.float32
# Load model
model_name_or_path = "bofenghuang/whisper-large-v3-french-distil-dec16"
processor = AutoProcessor.from_pretrained(model_name_or_path)
model = AutoModelForSpeechSeq2Seq.from_pretrained(
model_name_or_path,
torch_dtype=torch_dtype,
low_cpu_mem_usage=True,
)
model.to(device)
# Example audio
dataset = load_dataset("bofenghuang/asr-dummy", "fr", split="test")
sample = dataset[0]["audio"]
# Extract feautres
input_features = processor(
sample["array"], sampling_rate=sample["sampling_rate"], return_tensors="pt"
).input_features
# Generate tokens
predicted_ids = model.generate(
input_features.to(dtype=torch_dtype).to(device), max_new_tokens=128
)
# Detokenize to text
transcription = processor.batch_decode(predicted_ids, skip_special_tokens=True)[0]
print(transcription)
Speculative decoding can be achieved using a draft model, essentially a distilled version of Whisper. This approach guarantees identical outputs to using the main Whisper model alone, offers a 2x faster inference speed, and incurs only a slight increase in memory overhead.
Since the distilled Whisper has the same encoder as the original, only its decoder need to be loaded, and encoder outputs are shared between the main and draft models during inference.
Using speculative decoding with the Hugging Face pipeline is simple - just specify the assistant_model within the generation configurations.
import torch
from datasets import load_dataset
from transformers import (
AutoModelForCausalLM,
AutoModelForSpeechSeq2Seq,
AutoProcessor,
pipeline,
)
device = "cuda:0" if torch.cuda.is_available() else "cpu"
torch_dtype = torch.float16 if torch.cuda.is_available() else torch.float32
# Load model
model_name_or_path = "bofenghuang/whisper-large-v3-french"
processor = AutoProcessor.from_pretrained(model_name_or_path)
model = AutoModelForSpeechSeq2Seq.from_pretrained(
model_name_or_path,
torch_dtype=torch_dtype,
low_cpu_mem_usage=True,
)
model.to(device)
# Load draft model
assistant_model_name_or_path = "bofenghuang/whisper-large-v3-french-distil-dec2"
assistant_model = AutoModelForCausalLM.from_pretrained(
assistant_model_name_or_path,
torch_dtype=torch_dtype,
low_cpu_mem_usage=True,
)
assistant_model.to(device)
# Init pipeline
pipe = pipeline(
"automatic-speech-recognition",
model=model,
feature_extractor=processor.feature_extractor,
tokenizer=processor.tokenizer,
torch_dtype=torch_dtype,
device=device,
generate_kwargs={"assistant_model": assistant_model},
max_new_tokens=128,
)
# Example audio
dataset = load_dataset("bofenghuang/asr-dummy", "fr", split="test")
sample = dataset[0]["audio"]
# Run pipeline
result = pipe(sample)
print(result["text"])
You can also employ the sequential long-form decoding algorithm with a sliding window and temperature fallback, as outlined by OpenAI in their original paper.
First, install the openai-whisper package:
pip install -U openai-whisper
Then, download the converted model:
python -c "from huggingface_hub import hf_hub_download; hf_hub_download(repo_id='bofenghuang/whisper-large-v3-french-distil-dec16', filename='original_model.pt', local_dir='./models/whisper-large-v3-french-distil-dec16')"
Now, you can transcirbe audio files by following the usage instructions provided in the repository:
import whisper
from datasets import load_dataset
# Load model
model = whisper.load_model("./models/whisper-large-v3-french-distil-dec16/original_model.pt")
# Example audio
dataset = load_dataset("bofenghuang/asr-dummy", "fr", split="test")
sample = dataset[0]["audio"]["array"].astype("float32")
# Transcribe
result = model.transcribe(sample, language="fr")
print(result["text"])
Faster Whisper is a reimplementation of OpenAI's Whisper models and the sequential long-form decoding algorithm in the CTranslate2 format.
Compared to openai-whisper, it offers up to 4x faster inference speed, while consuming less memory. Additionally, the model can be quantized into int8, further enhancing its efficiency on both CPU and GPU.
First, install the faster-whisper package:
pip install faster-whisper
Then, download the model converted to the CTranslate2 format:
python -c "from huggingface_hub import snapshot_download; snapshot_download(repo_id='bofenghuang/whisper-large-v3-french-distil-dec16', local_dir='./models/whisper-large-v3-french-distil-dec16', allow_patterns='ctranslate2/*')"
Now, you can transcirbe audio files by following the usage instructions provided in the repository:
from datasets import load_dataset
from faster_whisper import WhisperModel
# Load model
model = WhisperModel("./models/whisper-large-v3-french-distil-dec16/ctranslate2", device="cuda", compute_type="float16") # Run on GPU with FP16
# Example audio
dataset = load_dataset("bofenghuang/asr-dummy", "fr", split="test")
sample = dataset[0]["audio"]["array"].astype("float32")
segments, info = model.transcribe(sample, beam_size=5, language="fr")
for segment in segments:
print("[%.2fs -> %.2fs] %s" % (segment.start, segment.end, segment.text))
Whisper.cpp is a reimplementation of OpenAI's Whisper models, crafted in plain C/C++ without any dependencies. It offers compatibility with various backends and platforms.
Additionally, the model can be quantized to either 4-bit or 5-bit integers, further enhancing its efficiency.
First, clone and build the whisper.cpp repository:
git clone https://github.com/ggerganov/whisper.cpp.git
cd whisper.cpp
# build the main example
make
Next, download the converted ggml weights from the Hugging Face Hub:
# Download model quantized with Q5_0 method
python -c "from huggingface_hub import hf_hub_download; hf_hub_download(repo_id='bofenghuang/whisper-large-v3-french-distil-dec16', filename='ggml-model-q5_0.bin', local_dir='./models/whisper-large-v3-french-distil-dec16')"
Now, you can transcribe an audio file using the following command:
./main -m ./models/whisper-large-v3-french-distil-dec16/ggml-model-q5_0.bin -l fr -f /path/to/audio/file --print-colors
Candle-whisper is a reimplementation of OpenAI's Whisper models in the candle format - a lightweight ML framework built in Rust.
First, clone the candle repository:
git clone https://github.com/huggingface/candle.git
cd candle/candle-examples/examples/whisper
Transcribe an audio file using the following command:
cargo run --example whisper --release -- --model large-v3 --model-id bofenghuang/whisper-large-v3-french-distil-dec16 --language fr --input /path/to/audio/file
In order to use CUDA add --features cuda to the example command line:
cargo run --example whisper --release --features cuda -- --model large-v3 --model-id bofenghuang/whisper-large-v3-french-distil-dec16 --language fr --input /path/to/audio/file
MLX-Whisper is a reimplementation of OpenAI's Whisper models in the MLX format - a ML framework on Apple silicon. It supports features like lazy computation, unified memory management, etc.
First, clone the MLX Examples repository:
git clone https://github.com/ml-explore/mlx-examples.git
cd mlx-examples/whisper
Next, install the dependencies:
pip install -r requirements.txt
Download the pytorch checkpoint in the original OpenAI format and convert it into MLX format (We haven't included the converted version here since the repository is already heavy and the conversion is very fast):
# Download
python -c "from huggingface_hub import hf_hub_download; hf_hub_download(repo_id='bofenghuang/whisper-large-v3-french-distil-dec16', filename='original_model.pt', local_dir='./models/whisper-large-v3-french-distil-dec16')"
# Convert into .npz
python convert.py --torch-name-or-path ./models/whisper-large-v3-french-distil-dec16/original_model.pt --mlx-path ./mlx_models/whisper-large-v3-french-distil-dec16
Now, you can transcribe audio with:
import whisper
result = whisper.transcribe("/path/to/audio/file", path_or_hf_repo="mlx_models/whisper-large-v3-french-distil-dec16", language="fr")
print(result["text"])
We've collected a composite dataset consisting of over 2,500 hours of French speech recognition data, which incldues datasets such as Common Voice 13.0, Multilingual LibriSpeech, Voxpopuli, Fleurs, Multilingual TEDx, MediaSpeech, African Accented French, etc.
Given that some datasets, like MLS, only offer text without case or punctuation, we employed a customized version of 🤗 Speechbox to restore case and punctuation from a limited set of symbols using the bofenghuang/whisper-large-v2-cv11-french model.
However, even within these datasets, we observed certain quality issues. These ranged from mismatches between audio and transcription in terms of language or content, poorly segmented utterances, to missing words in scripted speech, etc. We've built a pipeline to filter out many of these problematic utterances, aiming to enhance the dataset's quality. As a result, we excluded more than 10% of the data, and when we retrained the model, we noticed a significant reduction of hallucination.
For training, we employed the script available in the 🤗 Distil-Whisper repository. The model training took place on the Jean-Zay supercomputer at GENCI, and we extend our gratitude to the IDRIS team for their responsive support throughout the project.