Open-source LLMs as LangChain Agents









TL;DR
Open-source LLMs have now reached a performance level that makes them suitable reasoning engines for powering agent workflows: Mixtral even surpasses GPT-3.5 on our benchmark, and its performance could easily be further enhanced with fine-tuning.
We've released the simplest agentic library out there: smolagents! Go checkout the
smolagentsintroduction blog here.
Introduction
Large Language Models (LLMs) trained for causal language modeling can tackle a wide range of tasks, but they often struggle with basic tasks like logic, calculation, and search. The worst scenario is when they perform poorly in a domain, such as math, yet still attempt to handle all the calculations themselves.
To overcome this weakness, amongst other approaches, one can integrate the LLM into a system where it can call tools: such a system is called an LLM agent.
In this post, we explain the inner workings of ReAct agents, then show how to build them using the ChatHuggingFace class recently integrated in LangChain. Finally, we benchmark several open-source LLMs against GPT-3.5 and GPT-4.
Table of Contents
- What are agents?
- Running agents with LangChain
- Agents Showdown: how do different LLMs perform as general purpose reasoning agents?
What are agents?
The definition of LLM agents is quite broad: LLM agents are all systems that use LLMs as their engine and can perform actions on their environment based on observations. They can use several iterations of the Perception ⇒ Reflexion ⇒ Action cycle to achieve their task and are often augmented with planning or knowledge management systems to enhance their performance. You can find a good review of the Agents landscape in Xi et al., 2023.
Today, we are focusing on ReAct agents. ReAct is an approach to building agents based on the concatenation of two words, "Reasoning" and "Acting." In the prompt, we describe the model, which tools it can use, and ask it to think “step by step” (also called Chain-of-Thought behavior) to plan and execute its next actions to reach the final answer.

Toy example of a ReAct agent's inner working
The graph above seems very high-level, but under the hood it’s quite simple.
Take a look at this notebook: we implement a barebones tool call example with the Transformers library.
The LLM is called in a loop with a prompt containing in essence:
Here is a question: "{question}"
You have access to these tools: {tools_descriptions}.
You should first reflect with ‘Thought: {your_thoughts}’, then you either:
- call a tool with the proper JSON formatting,
- or your print your final answer starting with the prefix ‘Final Answer:’
Then you parse the LLM’s output:
- if it contains the string
‘Final Answer:’, the loop ends and you print the answer, - else, the LLM should have output a tool call: you can parse this output to get the tool name and arguments, then call said tool with said arguments. Then the output of this tool call is appended to the prompt, and you call the LLM again with this extended information, until it has enough information to finally provide a final answer to the question.
For instance, the LLM's output can look like this, when answering the question: How many seconds are in 1:23:45?
Thought: I need to convert the time string into seconds.
Action:
{
"action": "convert_time",
"action_input": {
"time": "1:23:45"
}
}
Since this output does not contain the string ‘Final Answer:’, it is calling a tool: so we parse this output and get the tool call parameters: call tool convert_time with arguments {"time": "1:23:45"}.
Running this tool call returns {'seconds': '5025'}.
So we append this whole blob to the prompt.
The new prompt is now (a slightly more elaborate version of):
Here is a question: "How many seconds are in 1:23:45?"
You have access to these tools:
- convert_time: converts a time given in hours:minutes:seconds into seconds.
You should first reflect with ‘Thought: {your_thoughts}’, then you either:
- call a tool with the proper JSON formatting,
- or your print your final answer starting with the prefix ‘Final Answer:’
Thought: I need to convert the time string into seconds.
Action:
{
"action": "convert_time",
"action_input": {
"time": "1:23:45"
}
}
Observation: {'seconds': '5025'}
➡️ We call the LLM again, with this new prompt. Given that it has access to the tool call's result in Observation, the LLM is now most likely to output:
Thought: I now have the information needed to answer the question.
Final Answer: There are 5025 seconds in 1:23:45.
And the task is solved!
Challenges of agent systems
Generally, the difficult parts of running an agent system for the LLM engine are:
- From supplied tools, choose the one that will help advance to a desired goal: e.g. when asked
"What is the smallest prime number greater than 30,000?", the agent could call theSearchtool with"What is the height of K2"but it won't help. - Call tools with a rigorous argument formatting: for instance when trying to calculate the speed of a car that went 3 km in 10 minutes, you have to call tool
Calculatorto dividedistancebytime: even if your Calculator tool accepts calls in the JSON format:{”tool”: “Calculator”, “args”: “3km/10min”}, there are many pitfalls, for instance:- Misspelling the tool name:
“calculator”or“Compute”wouldn’t work - Giving the name of the arguments instead of their values:
“args”: “distance/time” - Non-standardized formatting:
“args": "3km in 10minutes”
- Misspelling the tool name:
- Efficiently ingesting and using the information gathered in the past observations, be it the initial context or the observations returned after using tool uses.
So, how would a complete Agent setup look like?
Running agents with LangChain
We have just integrated a ChatHuggingFace wrapper that lets you create agents based on open-source models in 🦜🔗LangChain.
The code to create the ChatModel and give it tools is really simple, you can check it all in the Langchain doc.
from langchain_community.llms import HuggingFaceEndpoint
from langchain_community.chat_models.huggingface import ChatHuggingFace
llm = HuggingFaceEndpoint(repo_id="HuggingFaceH4/zephyr-7b-beta")
chat_model = ChatHuggingFace(llm=llm)
You can make the chat_model into an agent by giving it a ReAct style prompt and tools:
from langchain import hub
from langchain.agents import AgentExecutor, load_tools
from langchain.agents.format_scratchpad import format_log_to_str
from langchain.agents.output_parsers import (
ReActJsonSingleInputOutputParser,
)
from langchain.tools.render import render_text_description
from langchain_community.utilities import SerpAPIWrapper
# setup tools
tools = load_tools(["serpapi", "llm-math"], llm=llm)
# setup ReAct style prompt
prompt = hub.pull("hwchase17/react-json")
prompt = prompt.partial(
tools=render_text_description(tools),
tool_names=", ".join([t.name for t in tools]),
)
# define the agent
chat_model_with_stop = chat_model.bind(stop=["\nObservation"])
agent = (
{
"input": lambda x: x["input"],
"agent_scratchpad": lambda x: format_log_to_str(x["intermediate_steps"]),
}
| prompt
| chat_model_with_stop
| ReActJsonSingleInputOutputParser()
)
# instantiate AgentExecutor
agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True)
agent_executor.invoke(
{
"input": "Who is the current holder of the speed skating world record on 500 meters? What is her current age raised to the 0.43 power?"
}
)
And the agent will process the input:
Thought: To answer this question, I need to find age of the current speedskating world record holder. I will use the search tool to find this information.
Action:
{
"action": "search",
"action_input": "speed skating world record holder 500m age"
}
Observation: ...
Agents Showdown: how do open-source LLMs perform as general purpose reasoning agents?
You can find the code for this benchmark here.
Evaluation
We want to measure how open-source LLMs perform as general purpose reasoning agents. Thus we select questions requiring using logic and the use of basic tools: a calculator and access to internet search. The final dataset is a combination of samples from 3 other datasets:
- For testing Internet search capability: we have selected questions from HotpotQA: this is originally a retrieval dataset, but it can be used for general question answering, with access to the internet. Some questions originally need to combine information from various sources: in our setting, this means performing several steps of internet search to combine the results.
- For calculator usage, we added questions from GSM8K: this dataset tests grade-school math ability, and is entirely solvable by correctly leveraging the 4 operators (add, subtract, multiply, divide).
- We also picked questions from GAIA, a very difficult benchmark for General AI Assistants. The questions in the original dataset can require many other different tools, such as a code interpreter or pdf reader: we hand-picked questions that do not require other tools than search and calculator.
Evaluation was performed with GPT-4-as-a-judge using a prompt based on the Prometheus prompt format, giving results on a 5-point Likert Scale: see the exact prompt here.
Models
We evaluate a few strong open-source models:
- Llama2-70b-chat
- Mixtral-8x7B-Instruct-v0.1
- OpenHermes-2.5-Mistral-7B
- Zephyr-7b-beta
- SOLAR-10.7B-Instruct-v1.0
These models are evaluated in LangChain's ReAct implementation This means we prompt them to output their function calls in this format:
{
"action": $TOOL_NAME,
"action_input": $INPUT
}
For comparison, we have also evaluated GPT-3.5 and GPT-4 on the same examples using LangChain's OpenAI-specific agent. Since this uses their own function-calling template, on which they were fine-tuned, this means the OpenAI models should be at their top performance.
Results
Since the open-source models were not specifically fine-tuned for calling functions in the given output format, they are at a slight disadvantage compared to the OpenAI agents.
Despite this, some models perform really well! 💪
Here’s an example of Mixtral-8x7B answering the question: “Which city has a larger population, Guiyang or Tacheng?”
Thought: To answer this question, I need to find the current populations of both Guiyang and Tacheng. I will use the search tool to find this information.
Action:
{
"action": "search",
"action_input": "current population of Guiyang"
}
4.697 million (2016)
Thought: I have obtained the population of Guiyang, which is 4.697 million (as of 2016). Now, I will use the search tool again to find the population of Tacheng.
Action:
{
"action": "search",
"action_input": "current population of Tacheng"
}
Population: Xinjiang: Tacheng data was reported at 1,110.000 Persons in 2021. This records a decrease from the previous number of 1,138.638 Persons for 2020.
Population: Xinjiang: Tacheng data is updated yearly, averaging 1,023.000 Persons from Dec 2005 to 2021, with 17 observations.
I have obtained the population of Tacheng, which is approximately 1.11 million (as of 2021). Comparing the two populations, Guiyang has a larger population than Tacheng.
Thought: I now know the final answer
Final Answer: Guiyang has a larger population, which is approximately 4.697 million (as of 2016), compared to Tacheng's population of approximately 1.11 million (as of 2021).
Here is a benchmark of the models on our evaluation dataset (the average scores originally on a scale of 1-5 have been converted to a scale of 0-100% for readability):
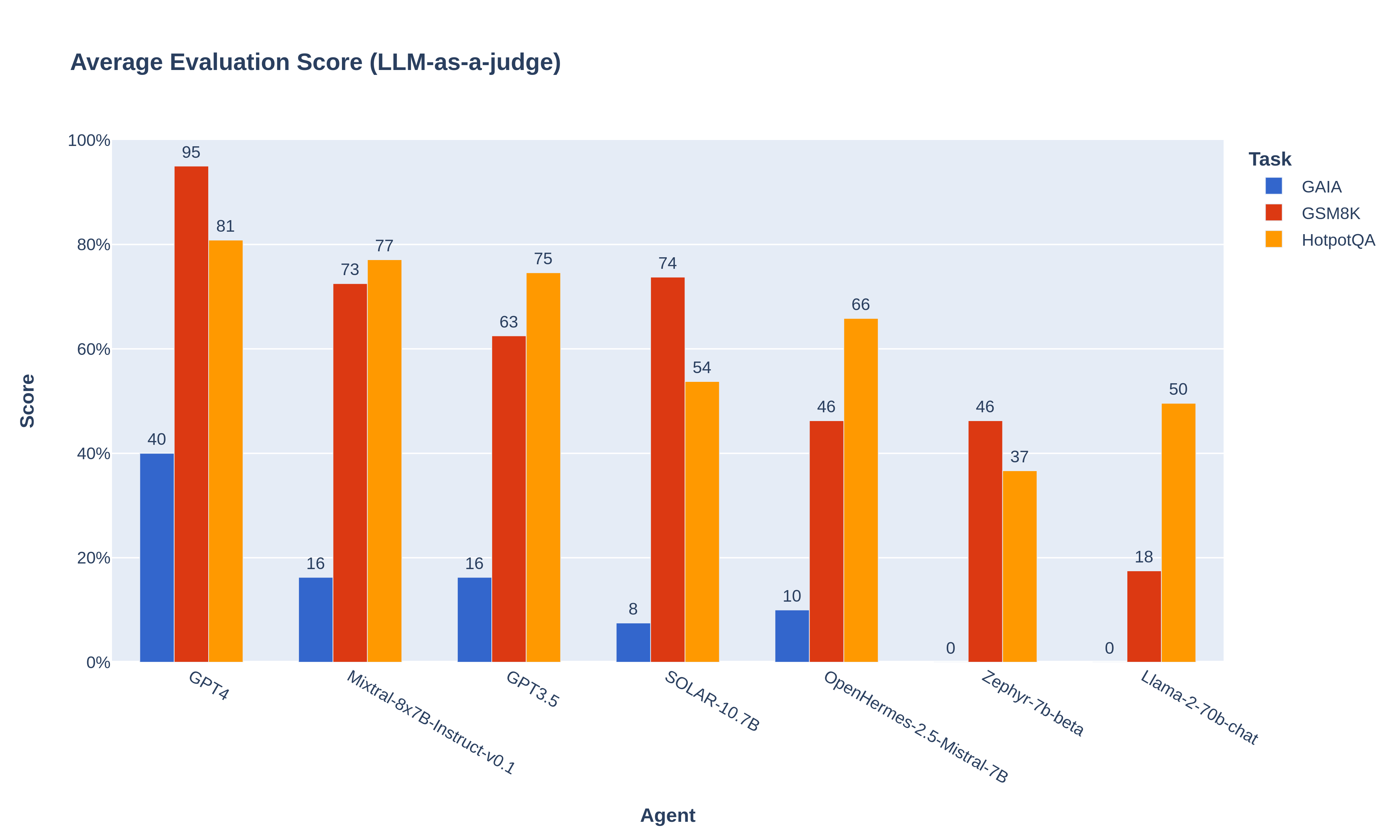
As you can see, some open-source models do not perform well in powering agent workflows: while this was expected for the small Zephyr-7b, Llama2-70b performs surprisingly poorly.
👉 But Mixtral-8x7B performs really well: it even beats GPT-3.5! 🏆
And this is out-of-the-box performance: contrary to GPT-3.5, Mixtral was not finetuned for agent workflows (to our knowledge), which somewhat hinders its performance. For instance, on GAIA, 10% of questions fail because Mixtral tries to call a tool with incorrectly formatted arguments. With proper fine-tuning for the function calling and task planning skills, Mixtral’s score would likely be even higher.
➡️ We strongly recommend open-source builders to start fine-tuning Mixtral for agents, to surpass the next challenger: GPT-4! 🚀
Closing remarks:
- The GAIA benchmark, although it is tried here on a small subsample of questions and a few tools, seems like a very robust indicator of overall model performance for agent workflows, since it generally involves several reasoning steps and rigorous logic.
- The agent workflows allow LLMs to increase performance: for instance, on GSM8K, GPT-4’s technical report reports 92% for 5-shot CoT prompting: giving it a calculator allows us to reach 95% in zero-shot . For Mixtral-8x7B, the LLM Leaderboard reports 57.6% with 5-shot, we get 73% in zero-shot. (Keep in mind that we tested only 20 questions of GSM8K)












