Accelerate StarCoder with 🤗 Optimum Intel on Xeon: Q8/Q4 and Speculative Decoding
















Introduction
Recently, code generation models have become very popular, especially with the release of state-of-the-art open-source models such as BigCode’s StarCoder and Meta AI’s Code Llama. A growing number of works focuses on making Large Language Models (LLMs) more optimized and accessible. In this blog, we are happy to share the latest results of LLM optimization on Intel Xeon focusing on the popular code generation LLM, StarCoder.
The StarCoder Model is a cutting-edge LLM specifically designed for assisting the user with various coding tasks such as code completion, bug fixing, code summarization, and even generating code snippets from natural language descriptions. The StarCoder model is a member of the StarCoder family which includes the StarCoderBase variant as well. These Large Language Models for Code (Code LLMs) are trained on permissively licensed data from GitHub, including over 80 programming languages, Git commits, GitHub issues, and Jupyter notebooks. In this work we show more than 7x inference acceleration of StarCoder-15B model on Intel 4th generation Xeon by integrating 8bit and 4bit quantization with assisted generation.
Try out our demo on Hugging Face Spaces that is being run on a 4th Generation Intel Xeon Scalable processor.
Step 1: Baseline and Evaluation
We establish our baseline using StarCoder (15B) coupled with PyTorch and Intel Extension for PyTorch (IPEX). There are several datasets designed to evaluate the quality of automated code completion. In this work, we use the popular HumanEval dataset to evaluate the model’s quality and performance. HumanEval consists of 164 programming problems, in the form of a function signature with a docstring and the model completes the function’s code. The average length of the prompt is 139. We measure the quality using Bigcode Evaluation Harness and report the pass@1 metric. We measure model performance by measuring the Time To First Token (TTFT) and Time Per Output Token (TPOT) on the HumanEval test set and report the average TTFT and TPOT. The 4th generation Intel Xeon processors feature AI infused acceleration known as Intel® Advanced Matrix Extensions (Intel® AMX). Specifically, it has built-in BFloat16 (BF16) and Int8 GEMM accelerators in every core to accelerate deep learning training and inference workloads. AMX accelerated inference is introduced through PyTorch 2.0 and Intel Extension for PyTorch (IPEX) in addition to other optimizations for various common operators used in LLM inference (e.g. layer normalization, SoftMax, scaled dot product). As the starting point we use out-of-the-box optimizations in PyTorch and IPEX to perform inference using a BF16 model. Figure 1 shows the latency of the baseline model and Tables 1 and 2 show its latency as well as its accuracy.
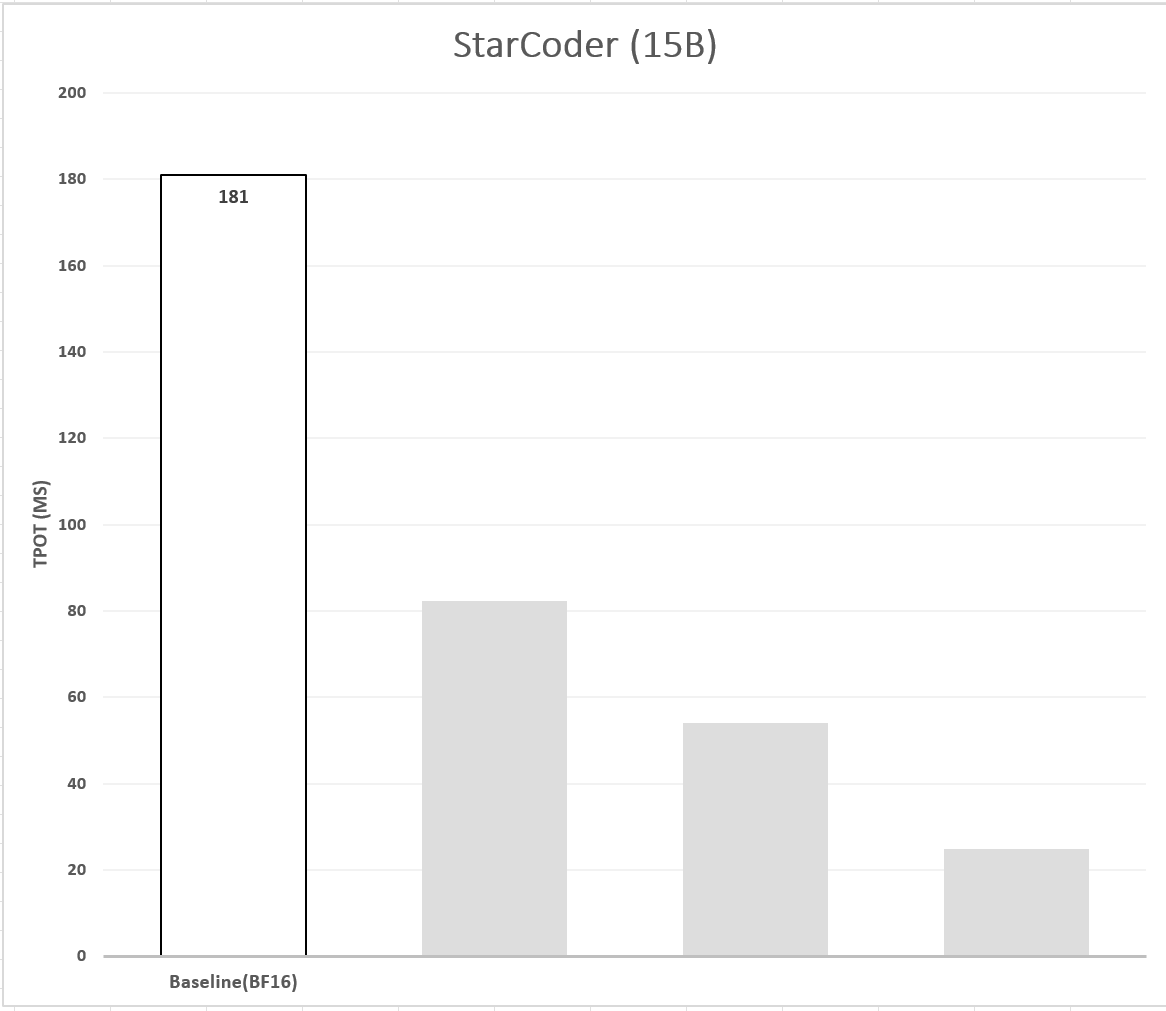
Figure 1. Latency of the baseline model.
LLM Quantization
Text generation in LLMs is performed in an auto-regressive manner thus requiring the entire model to be loaded from memory to the CPU for each new token generation. We find that the bandwidth between the off-chip memory (DRAM) and the CPU poses the biggest bottleneck in the token generation process. Quantization is a popular approach for mitigating this issue. It reduces model size and hence decreases model weights loading time.
In this work we focus on two types of quantization:
- Weight Only Quantization (WOQ) - the weights of the model being quantized but not the activations while computation is performed in higher precision (e.g. BF16) which requires dequantization.
- Static Quantization (SQ) - both the weights and the activations are quantized. This quantization process includes pre-calculating the quantization parameters through a calibration step which enables the computation to be executed in lower precision (e.g. INT8). Figure 2 shows the INT8 static quantization computation process.
Step 2: 8bit Quantization (INT8)
SmoothQuant is a post training quantization algorithm that is used to quantize LLMs for INT8 with minimal accuracy loss. Static quantization methods were shown to be underperforming on LLMs due to large magnitude outliers found in specific channels of the activations. Since activations are quantized token-wise, static quantization results in either truncated outliers or underflowed low-magnitude activations. SmoothQuant algorithm solves this problem by introducing a pre-quantization phase where additional smoothing scaling factors are applied to both activations and weights which smooths the outliers in the activations and ensures better utilization of the quantization levels.
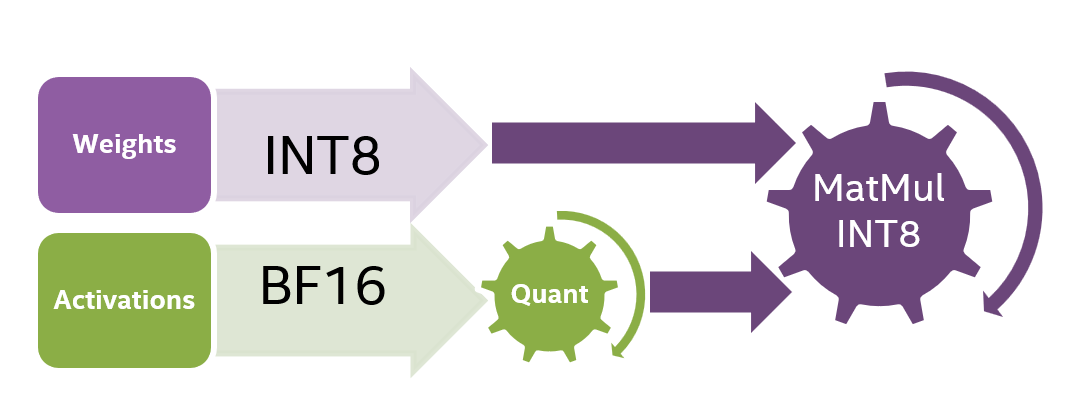
Figure 2. Computation diagram for INT8 static quantization.
Using IPEX, we apply SmoothQuant to the StarCoder model. We used the test split of the MBPP dataset as our calibration dataset and introduced Q8-StarCoder. Our evaluation shows that Q8-StarCoder holds no accuracy loss over the baseline (if fact, there is even a slight improvement). In terms of performance, Q8-StarCoder achieves ~2.19x speedup in TTFT and ~2.20x speedup in TPOT. Figure 3 shows the latency (TPOT) of Q8-StarCoder compared to the BF16 baseline model.
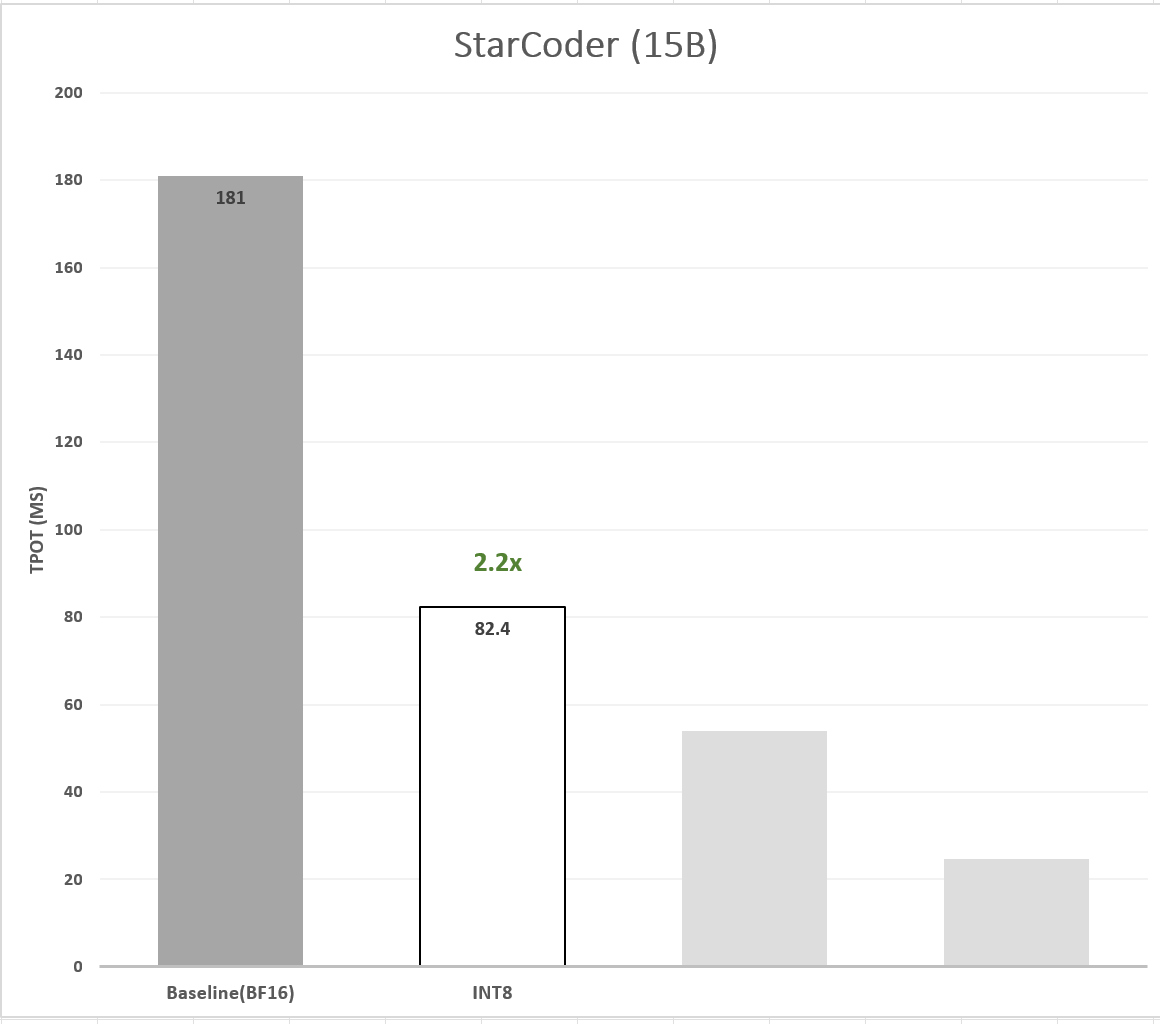
Figure 3. Latency speedup of 8-bit quantized model.
Step 3: 4bit Quantization (INT4)
Although INT8 decreases the model size by 2x compared to BF16 (8 bits per weight compared to 16 bits), the memory bandwidth is still the largest bottleneck. To further decrease the model’s loading time from the memory, we quantized the model’s weights to 4 bits using WOQ. Note that 4bit WOQ requires dequantization to 16bit before the computation (Figure 4) which means that there is a compute overhead.
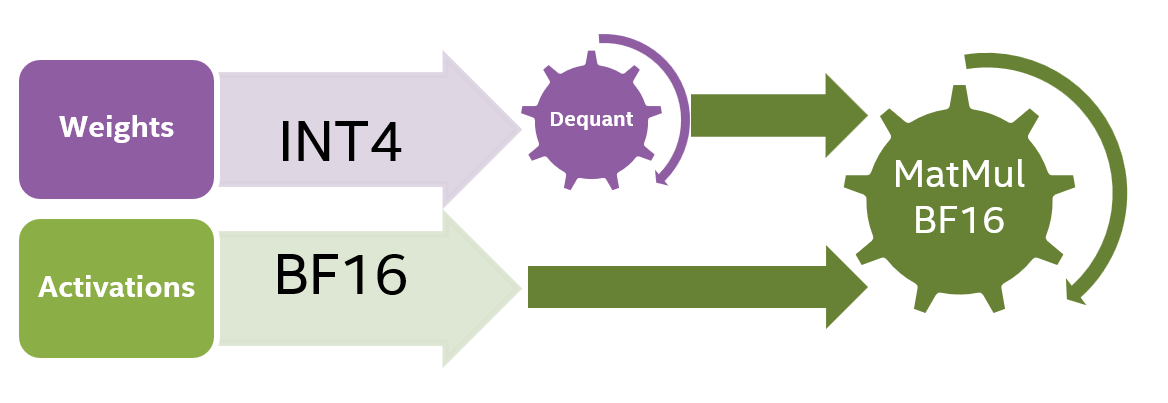
Figure 4. Computation diagram for model quantized to INT4.
Tensor-wise asymmetric Round To Nearest (RTN) quantization, a basic WOQ technique, poses challenges and often results in accuracy reduction, however it was shown in the literature (Zhewei Yao, 2022) that groupwise quantization of the model’s weights helps in retaining accuracy. To avoid accuracy degradation, we perform 4-bit quantization in groups (e.g. 128) of consequent values along the input channel, with scaling factors calculated per group. We found that groupwise 4bit RTN is sufficient to retain StarCoder’s accuracy on the HumanEval dataset. The 4bit model achieves 3.35x speedup in TPOT compared to the BF16 baseline (figure 5), however it suffers from expected slowdown of 0.84x in TTFT (Table 1) due to the overhead of dequantizing the 4bit to 16bit before computation.
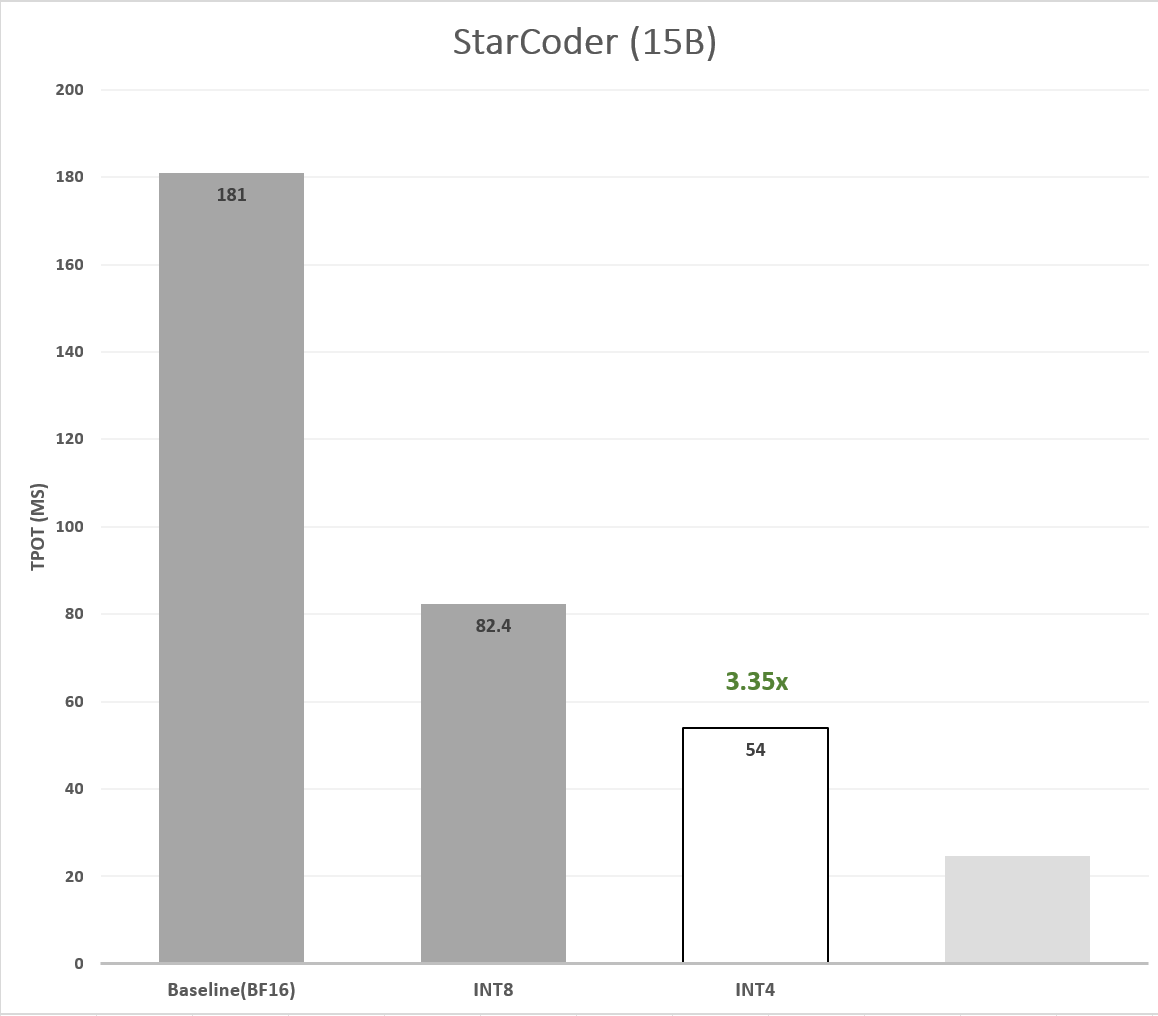
Figure 5. Latency speedup of 4-bit quantized model.
Different Bottlenecks between Generating the First Token and Subsequent Tokens
The initial step of generating the first token, which involves parallel processing of the entire input prompt, demands significant computational resources when the prompt length is high. Computation, therefore, becomes the bottleneck in this stage. Hence, switching from BF16 to INT8 precision for this process improves the performance compared to the baseline (and to 4bit WOQ which involves compute overhead in the form of dequantization). However, starting from the second step, when the system generates the rest of the tokens one by one in an autoregressive manner, the model is loaded from the memory again and again for each new generated token. As a result, the bottleneck becomes memory bandwidth, rather than the number of calculations (FLOPS) performed and therefore INT4 outperforms INT8 and BF16.
Step 4: Assisted Generation (AG)
Another method to mitigate the high inference latency and alleviate the memory bandwidth bottleneck issue is Assisted generation (AG) which is a practical implementation of speculative decoding. AG mitigates this issue by better balancing memory and computational operations. It relies on the premise that a smaller and faster assistant draft model often generates the same tokens as a larger target model.
AG uses a small, fast draft model to greedily generate K candidate tokens. These output tokens are generated much faster, but some of them may not resemble the output tokens of the original target model. Hence, in the next step, the target model checks the validity of all K candidate tokens in parallel in a single forward pass. This process speeds up the decoding since the latency of parallel decoding of K tokens is smaller than generating K tokens autoregressively.
For accelerating StarCoder, we use bigcode/tiny_starcoder_py as the draft model. This model shares a similar architecture with StarCoder but includes only 164M parameters - ~95x smaller than StarCoder, and thus much faster. To achieve an even greater speedup, in addition to quantizing the target model, we apply quantization to the draft model as well. We consider both 8bit SmoothQuant and 4bit WOQ quantization for the draft and target models. When evaluating both quantization options for the draft and target models, we found that 8bit SmoothQuant for both models yielded the best results: ~7.30x speedup in TPOT (Figure 6).
These quantization choices are backed up by the following observations:
- Draft model quantization: when using 8bit quantized StarCoder with 164M parameters as draft model, the model mostly fits in the CPU cache. As a result, the memory bandwidth bottleneck is alleviated, as token generation occurs without repeatedly reading the target model from off-chip memory for each token. In this case, there is no memory bottleneck, and we see better speedup with StarCoder-164M quantized to 8bit in comparison to StarCoder-164M quantized to 4bit WOQ. We note that 4bit WOQ holds an advantage where memory bandwidth is the bottleneck because of its smaller memory footprint, however 4bit comes with a compute overhead due to the requirement to perform 4bit to 16bit dequantization before the computation.
- Target model quantization: in assisted generation, the target model processes a sequence of K tokens that were generated by the draft model. Forwarding K tokens at once (in parallel) through the target model instead of applying the “standard” sequential autoregressive processing, shifts the balance from memory bandwidth to compute bottleneck. Therefore, we observed that using an 8bit quantized target model yields higher speedups than using a 4bit model because of the additional compute overhead that stems from dequantization of every single value from 4bit to 16bit.
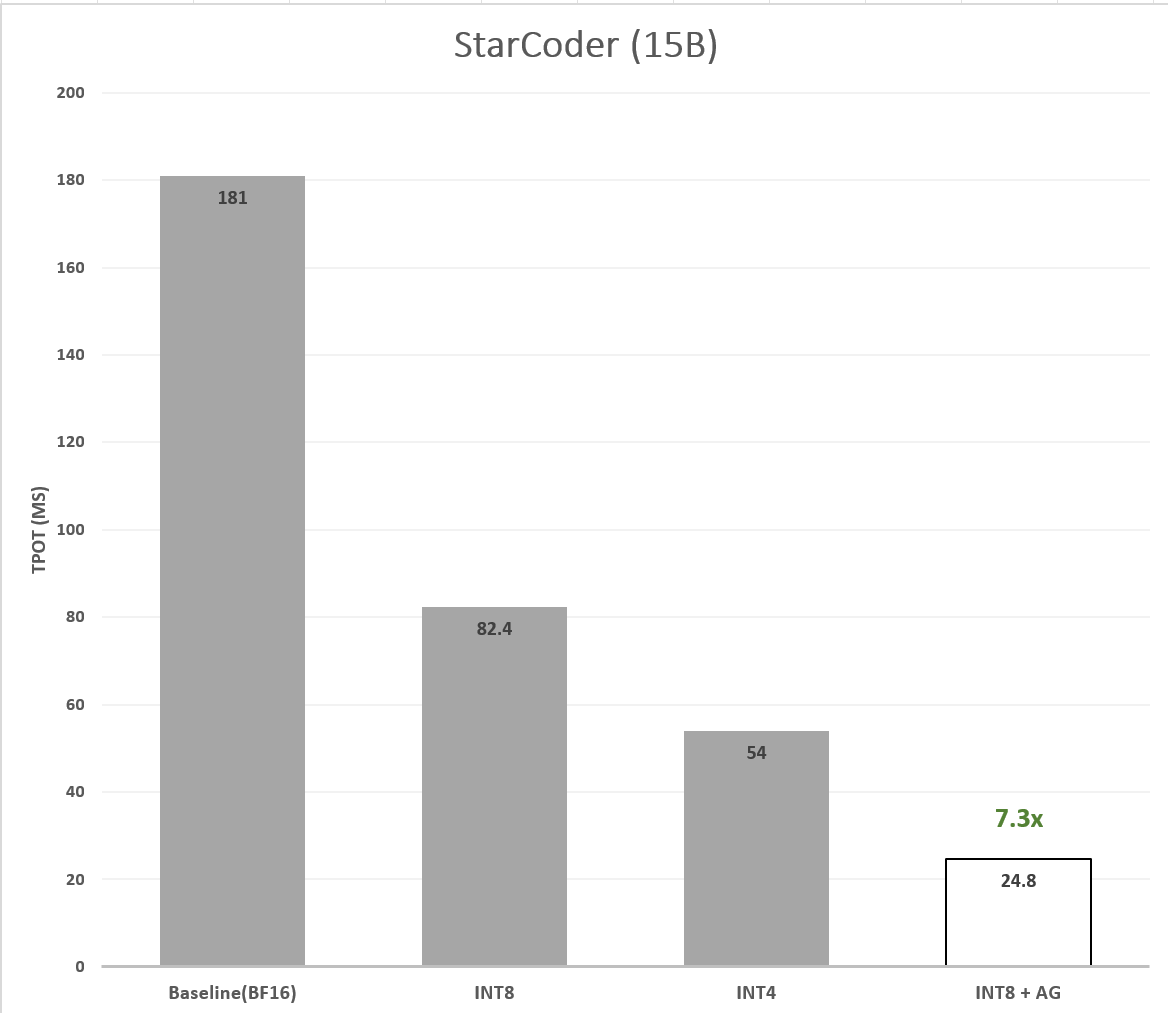
Figure 6. Latency speedup of optimized model.
| StarCoder | Quantization | Precision | HumanEval (pass@1) | TTFT (ms) | TTFT Speedup | TPOT (ms) | TPOT Speedup |
|---|---|---|---|---|---|---|---|
| Baseline | None | A16W16 | 33.54 | 357.9 | 1.00x | 181.0 | 1.00x |
| INT8 | SmoothQuant | A8W8 | 33.96 | 163.4 | 2.19x | 82.4 | 2.20x |
| INT4 | RTN (g128) | A16W4 | 32.80 | 425.1 | 0.84x | 54.0 | 3.35x |
| INT8 + AG | SmoothQuant | A8W8 | 33.96 | 183.6 | 1.95x | 24.8 | 7.30x |
Table 1: Accuracy and latency measurements of the StarCoder model on Intel 4th Gen Xeon
To load the resulting models and run inference, you can just replace your AutoModelForXxx class with the corresponding IPEXModelForXxx class from optimum-intel.
Before you begin, make sure you have all the necessary libraries installed :
pip install --upgrade-strategy eager optimum[ipex]
- from transformers import AutoModelForCausalLM
+ from optimum.intel import IPEXModelForCausalLM
from transformers import AutoTokenizer, pipeline
- model = AutoModelForCausalLM.from_pretrained(model_id)
+ model = IPEXModelForCausalLM.from_pretrained(model_id)
tokenizer = AutoTokenizer.from_pretrained(model_id)
pipe = pipeline("text-generation", model=model, tokenizer=tokenizer)
results = pipe("He's a dreadful magician and")



