Introducing IDEFICS: An Open Reproduction of State-of-the-Art Visual Language Model

















We are excited to release IDEFICS (Image-aware Decoder Enhanced à la Flamingo with Interleaved Cross-attentionS), an open-access visual language model. IDEFICS is based on Flamingo, a state-of-the-art visual language model initially developed by DeepMind, which has not been released publicly. Similarly to GPT-4, the model accepts arbitrary sequences of image and text inputs and produces text outputs. IDEFICS is built solely on publicly available data and models (LLaMA v1 and OpenCLIP) and comes in two variants—the base version and the instructed version. Each variant is available at the 9 billion and 80 billion parameter sizes.
The development of state-of-the-art AI models should be more transparent. Our goal with IDEFICS is to reproduce and provide the AI community with systems that match the capabilities of large proprietary models like Flamingo. As such, we took important steps contributing to bringing transparency to these AI systems: we used only publicly available data, we provided tooling to explore training datasets, we shared technical lessons and mistakes of building such artifacts and assessed the model’s harmfulness by adversarially prompting it before releasing it. We are hopeful that IDEFICS will serve as a solid foundation for more open research in multimodal AI systems, alongside models like OpenFlamingo-another open reproduction of Flamingo at the 9 billion parameter scale.
Try out the demo and the models on the Hub!
What is IDEFICS?
IDEFICS is an 80 billion parameters multimodal model that accepts sequences of images and texts as input and generates coherent text as output. It can answer questions about images, describe visual content, create stories grounded in multiple images, etc.
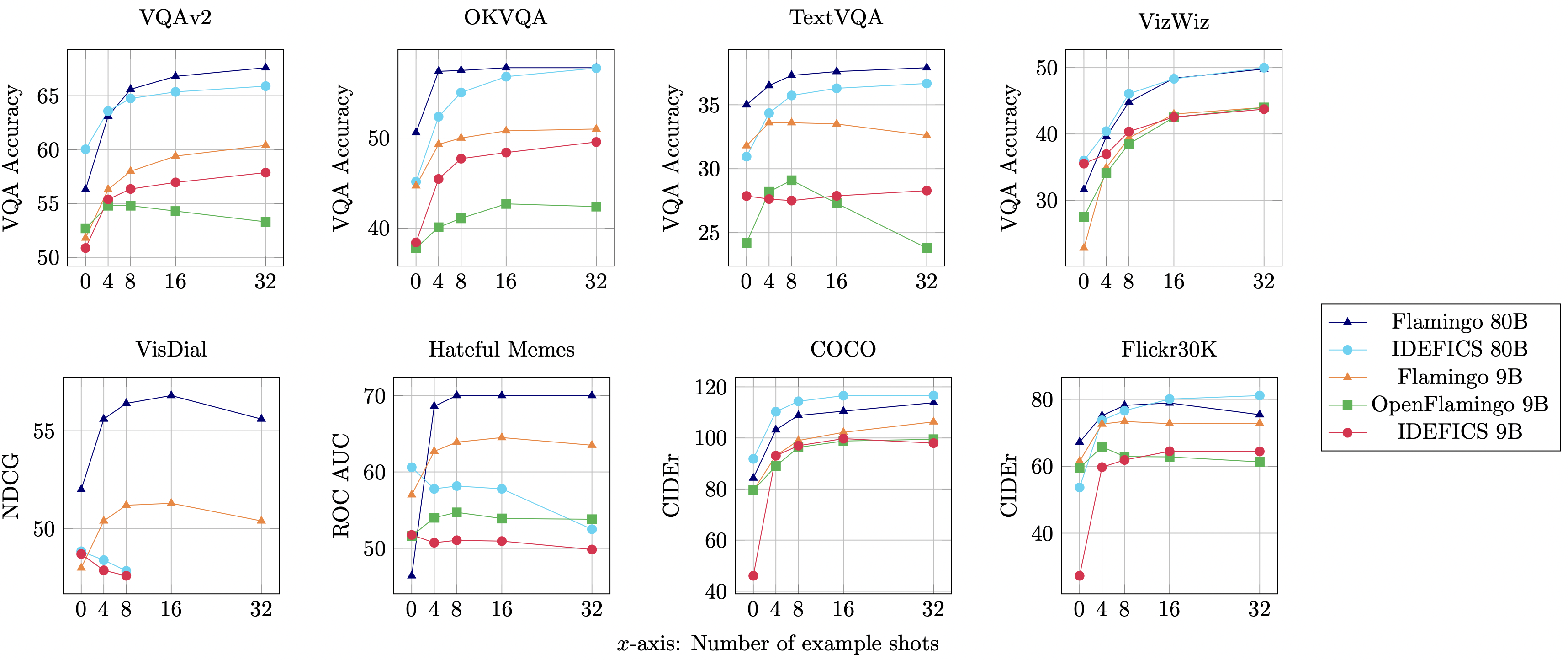
IDEFICS is an open-access reproduction of Flamingo and is comparable in performance with the original closed-source model across various image-text understanding benchmarks. It comes in two variants - 80 billion parameters and 9 billion parameters.
We also provide fine-tuned versions idefics-80B-instruct and idefics-9B-instruct adapted for conversational use cases.
Training Data
IDEFICS was trained on a mixture of openly available datasets: Wikipedia, Public Multimodal Dataset, and LAION, as well as a new 115B token dataset called OBELICS that we created. OBELICS consists of 141 million interleaved image-text documents scraped from the web and contains 353 million images.
We provide an interactive visualization of OBELICS that allows exploring the content of the dataset with Nomic AI.

The details of IDEFICS' architecture, training methodology, and evaluations, as well as information about the dataset, are available in the model card and our research paper. Additionally, we have documented technical insights and learnings from the model's training, offering valuable perspective on IDEFICS' development.
Ethical evaluation
At the outset of this project, through a set of discussions, we developed an ethical charter that would help steer decisions made during the project. This charter sets out values, including being self-critical, transparent, and fair which we have sought to pursue in how we approached the project and the release of the models.
As part of the release process, we internally evaluated the model for potential biases by adversarially prompting the model with images and text that might elicit responses we do not want from the model (a process known as red teaming).
Please try out IDEFICS with the demo, check out the corresponding model cards and dataset card and let us know your feedback using the community tab! We are committed to improving these models and making large multimodal AI models accessible to the machine learning community.
License
The model is built on top of two pre-trained models: laion/CLIP-ViT-H-14-laion2B-s32B-b79K and huggyllama/llama-65b. The first was released under an MIT license, while the second was released under a specific non-commercial license focused on research purposes. As such, users should comply with that license by applying directly to Meta's form.
The two pre-trained models are connected to each other with newly initialized parameters that we train. These are not based on any of the two base frozen models forming the composite model. We release the additional weights we trained under an MIT license.
Getting Started with IDEFICS
IDEFICS models are available on the Hugging Face Hub and supported in the last transformers version. Here is a code sample to try it out:
import torch
from transformers import IdeficsForVisionText2Text, AutoProcessor
device = "cuda" if torch.cuda.is_available() else "cpu"
checkpoint = "HuggingFaceM4/idefics-9b-instruct"
model = IdeficsForVisionText2Text.from_pretrained(checkpoint, torch_dtype=torch.bfloat16).to(device)
processor = AutoProcessor.from_pretrained(checkpoint)
# We feed to the model an arbitrary sequence of text strings and images. Images can be either URLs or PIL Images.
prompts = [
[
"User: What is in this image?",
"https://upload.wikimedia.org/wikipedia/commons/8/86/Id%C3%A9fix.JPG",
"<end_of_utterance>",
"\nAssistant: This picture depicts Idefix, the dog of Obelix in Asterix and Obelix. Idefix is running on the ground.<end_of_utterance>",
"\nUser:",
"https://static.wikia.nocookie.net/asterix/images/2/25/R22b.gif/revision/latest?cb=20110815073052",
"And who is that?<end_of_utterance>",
"\nAssistant:",
],
]
# --batched mode
inputs = processor(prompts, add_end_of_utterance_token=False, return_tensors="pt").to(device)
# --single sample mode
# inputs = processor(prompts[0], return_tensors="pt").to(device)
# Generation args
exit_condition = processor.tokenizer("<end_of_utterance>", add_special_tokens=False).input_ids
bad_words_ids = processor.tokenizer(["<image>", "<fake_token_around_image>"], add_special_tokens=False).input_ids
generated_ids = model.generate(**inputs, eos_token_id=exit_condition, bad_words_ids=bad_words_ids, max_length=100)
generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)
for i, t in enumerate(generated_text):
print(f"{i}:\n{t}\n")







