Proximal Policy Optimization (PPO)







Unit 8, of the Deep Reinforcement Learning Class with Hugging Face 🤗
⚠️ A new updated version of this article is available here 👉 https://huggingface.co/deep-rl-course/unit1/introduction
This article is part of the Deep Reinforcement Learning Class. A free course from beginner to expert. Check the syllabus here.

⚠️ A new updated version of this article is available here 👉 https://huggingface.co/deep-rl-course/unit1/introduction
This article is part of the Deep Reinforcement Learning Class. A free course from beginner to expert. Check the syllabus here.
In the last Unit, we learned about Advantage Actor Critic (A2C), a hybrid architecture combining value-based and policy-based methods that help to stabilize the training by reducing the variance with:
- An Actor that controls how our agent behaves (policy-based method).
- A Critic that measures how good the action taken is (value-based method).
Today we'll learn about Proximal Policy Optimization (PPO), an architecture that improves our agent's training stability by avoiding too large policy updates. To do that, we use a ratio that will indicates the difference between our current and old policy and clip this ratio from a specific range .
Doing this will ensure that our policy update will not be too large and that the training is more stable.
And then, after the theory, we'll code a PPO architecture from scratch using PyTorch and bulletproof our implementation with CartPole-v1 and LunarLander-v2.
Sounds exciting? Let's get started!
- The intuition behind PPO
- Introducing the Clipped Surrogate Objective
- Visualize the Clipped Surrogate Objective
- Let's code our PPO Agent
The intuition behind PPO
The idea with Proximal Policy Optimization (PPO) is that we want to improve the training stability of the policy by limiting the change you make to the policy at each training epoch: we want to avoid having too large policy updates.
For two reasons:
- We know empirically that smaller policy updates during training are more likely to converge to an optimal solution.
- A too big step in a policy update can result in falling “off the cliff” (getting a bad policy) and having a long time or even no possibility to recover.

So with PPO, we update the policy conservatively. To do so, we need to measure how much the current policy changed compared to the former one using a ratio calculation between the current and former policy. And we clip this ratio in a range , meaning that we remove the incentive for the current policy to go too far from the old one (hence the proximal policy term).
Introducing the Clipped Surrogate Objective
Recap: The Policy Objective Function
Let’s remember what is the objective to optimize in Reinforce:

The idea was that by taking a gradient ascent step on this function (equivalent to taking gradient descent of the negative of this function), we would push our agent to take actions that lead to higher rewards and avoid harmful actions.
However, the problem comes from the step size:
- Too small, the training process was too slow
- Too high, there was too much variability in the training
Here with PPO, the idea is to constrain our policy update with a new objective function called the Clipped surrogate objective function that will constrain the policy change in a small range using a clip.
This new function is designed to avoid destructive large weights updates :

Let’s study each part to understand how it works.
The Ratio Function

This ratio is calculated this way:

It’s the probability of taking action at state in the current policy divided by the previous one.
As we can see, denotes the probability ratio between the current and old policy:
- If , the action at state is more likely in the current policy than the old policy.
- If is between 0 and 1, the action is less likely for the current policy than for the old one.
So this probability ratio is an easy way to estimate the divergence between old and current policy.
The unclipped part of the Clipped Surrogate Objective function

This ratio can replace the log probability we use in the policy objective function. This gives us the left part of the new objective function: multiplying the ratio by the advantage.

However, without a constraint, if the action taken is much more probable in our current policy than in our former, this would lead to a significant policy gradient step and, therefore, an excessive policy update.
The clipped Part of the Clipped Surrogate Objective function

Consequently, we need to constrain this objective function by penalizing changes that lead to a ratio away from 1 (in the paper, the ratio can only vary from 0.8 to 1.2).
By clipping the ratio, we ensure that we do not have a too large policy update because the current policy can't be too different from the older one.
To do that, we have two solutions:
- TRPO (Trust Region Policy Optimization) uses KL divergence constraints outside the objective function to constrain the policy update. But this method is complicated to implement and takes more computation time.
- PPO clip probability ratio directly in the objective function with its Clipped surrogate objective function.
This clipped part is a version where rt(theta) is clipped between .
With the Clipped Surrogate Objective function, we have two probability ratios, one non-clipped and one clipped in a range (between , epsilon is a hyperparameter that helps us to define this clip range (in the paper .).
Then, we take the minimum of the clipped and non-clipped objective, so the final objective is a lower bound (pessimistic bound) of the unclipped objective.
Taking the minimum of the clipped and non-clipped objective means we'll select either the clipped or the non-clipped objective based on the ratio and advantage situation.
Visualize the Clipped Surrogate Objective
Don't worry. It's normal if this seems complex to handle right now. But we're going to see what this Clipped Surrogate Objective Function looks like, and this will help you to visualize better what's going on.
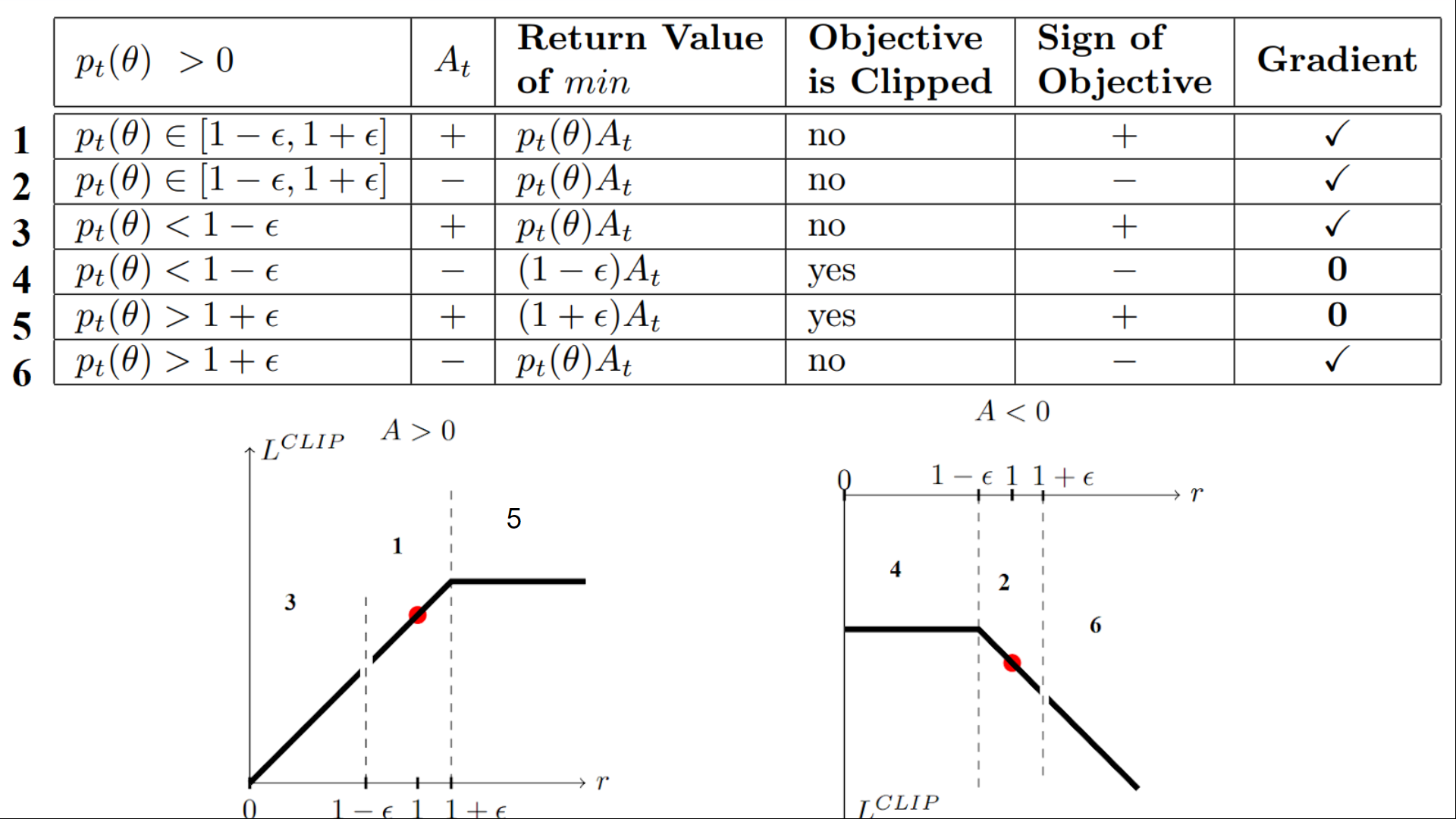
We have six different situations. Remember first that we take the minimum between the clipped and unclipped objectives.
Case 1 and 2: the ratio is between the range
In situations 1 and 2, the clipping does not apply since the ratio is between the range
In situation 1, we have a positive advantage: the action is better than the average of all the actions in that state. Therefore, we should encourage our current policy to increase the probability of taking that action in that state.
Since the ratio is between intervals, we can increase our policy's probability of taking that action at that state.
In situation 2, we have a negative advantage: the action is worse than the average of all actions at that state. Therefore, we should discourage our current policy from taking that action in that state.
Since the ratio is between intervals, we can decrease the probability that our policy takes that action at that state.
Case 3 and 4: the ratio is below the range
If the probability ratio is lower than , the probability of taking that action at that state is much lower than with the old policy.
If, like in situation 3, the advantage estimate is positive (A>0), then you want to increase the probability of taking that action at that state.
But if, like situation 4, the advantage estimate is negative, we don't want to decrease further the probability of taking that action at that state. Therefore, the gradient is = 0 (since we're on a flat line), so we don't update our weights.
Case 5 and 6: the ratio is above the range
If the probability ratio is higher than , the probability of taking that action at that state in the current policy is much higher than in the former policy.
If, like in situation 5, the advantage is positive, we don't want to get too greedy. We already have a higher probability of taking that action at that state than the former policy. Therefore, the gradient is = 0 (since we're on a flat line), so we don't update our weights.
If, like in situation 6, the advantage is negative, we want to decrease the probability of taking that action at that state.
So if we recap, we only update the policy with the unclipped objective part. When the minimum is the clipped objective part, we don't update our policy weights since the gradient will equal 0.
So we update our policy only if:
- Our ratio is in the range
- Our ratio is outside the range, but the advantage leads to getting closer to the range
- Being below the ratio but the advantage is > 0
- Being above the ratio but the advantage is < 0
You might wonder why, when the minimum is the clipped ratio, the gradient is 0. When the ratio is clipped, the derivative in this case will not be the derivative of the but the derivative of either or the derivative of which both = 0.
To summarize, thanks to this clipped surrogate objective, we restrict the range that the current policy can vary from the old one. Because we remove the incentive for the probability ratio to move outside of the interval since, the clip have the effect to gradient. If the ratio is > or < the gradient will be equal to 0.
The final Clipped Surrogate Objective Loss for PPO Actor-Critic style looks like this, it's a combination of Clipped Surrogate Objective function, Value Loss Function and Entropy bonus:
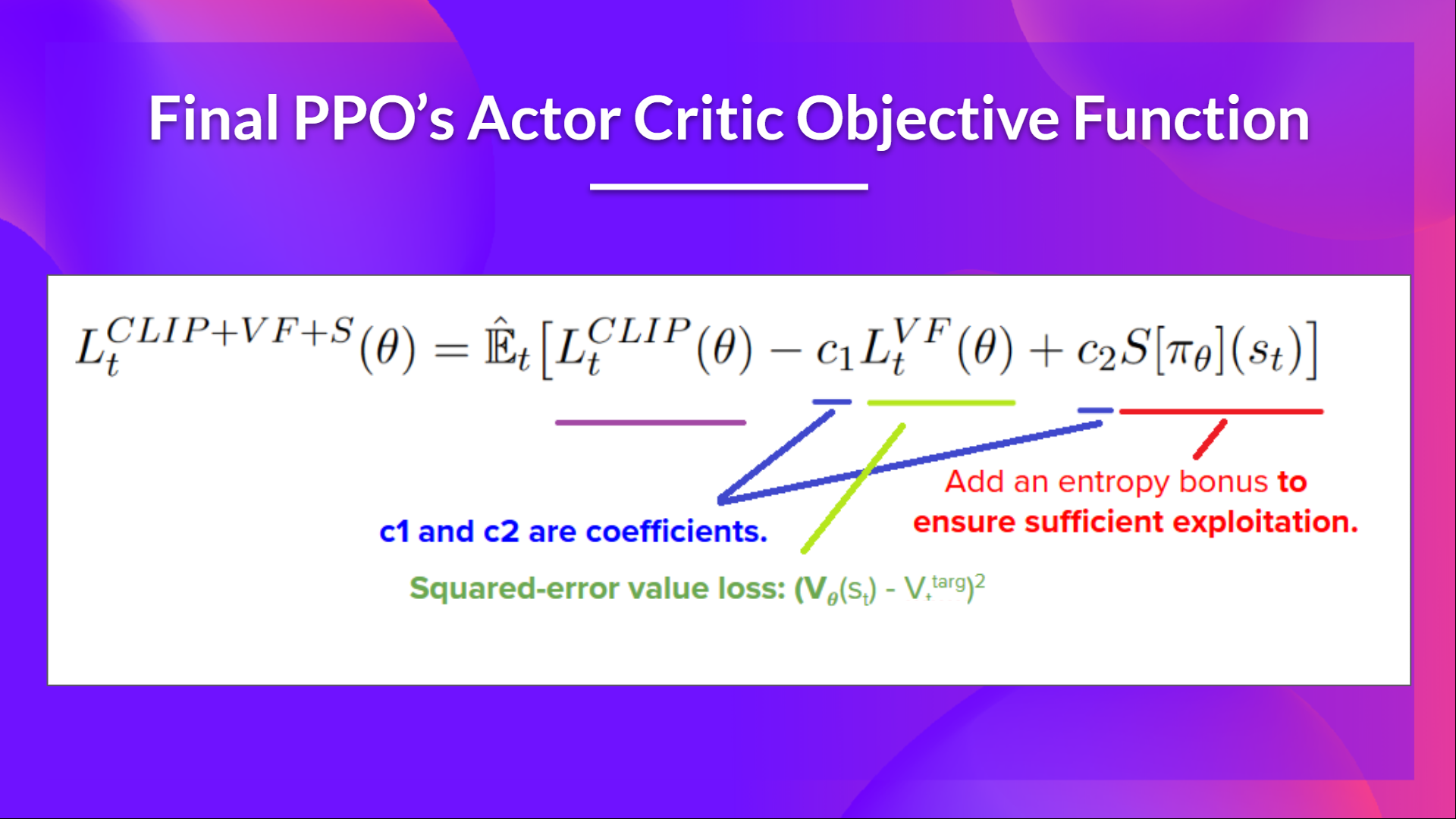
That was quite complex. Take time to understand these situations by looking at the table and the graph. You must understand why this makes sense. If you want to go deeper, the best resource is the article Towards Delivering a Coherent Self-Contained Explanation of Proximal Policy Optimization" by Daniel Bick, especially part 3.4.
Let's code our PPO Agent
Now that we studied the theory behind PPO, the best way to understand how it works is to implement it from scratch.
Implementing an architecture from scratch is the best way to understand it, and it's a good habit. We have already done it for a value-based method with Q-Learning and a Policy-based method with Reinforce.
So, to be able to code it, we're going to use two resources:
- A tutorial made by Costa Huang. Costa is behind CleanRL, a Deep Reinforcement Learning library that provides high-quality single-file implementation with research-friendly features.
- In addition to the tutorial, to go deeper, you can read the 13 core implementation details: https://iclr-blog-track.github.io/2022/03/25/ppo-implementation-details/
Then, to test its robustness, we're going to train it in 2 different classical environments:
And finally, we will be push the trained model to the Hub to evaluate and visualize your agent playing.
LunarLander-v2 is the first environment you used when you started this course. At that time, you didn't know how it worked, and now, you can code it from scratch and train it. How incredible is that 🤩.
Start the tutorial here 👉 https://github.com/huggingface/deep-rl-class/blob/main/unit8/unit8.ipynb
Congrats on finishing this chapter! There was a lot of information. And congrats on finishing the tutorial. 🥳, this was one of the hardest of the course.
Don't hesitate to train your agent in other environments. The best way to learn is to try things on your own!
I want you to think about your progress since the first Unit. With these eight units, you've built a strong background in Deep Reinforcement Learning. Congratulations!
But this is not the end, even if the foundations part of the course is finished, this is not the end of the journey. We're working on new elements:
- Adding new environments and tutorials.
- A section about multi-agents (self-play, collaboration, competition).
- Another one about offline RL and Decision Transformers.
- Paper explained articles.
- And more to come.
The best way to keep in touch is to sign up for the course so that we keep you updated 👉 http://eepurl.com/h1pElX
And don't forget to share with your friends who want to learn 🤗!
Finally, with your feedback, we want to improve and update the course iteratively. If you have some, please fill this form 👉 https://forms.gle/3HgA7bEHwAmmLfwh9
See you next time!







