
Chronos Models & Datasets
Collection
Collection of artifacts related to Chronos pretrained models for time series forecasting.
•
12 items
•
Updated
•
40
🚀 Update Feb 14, 2025: Chronos-Bolt & original Chronos models are now available on Amazon SageMaker JumpStart! Check out the tutorial notebook to learn how to deploy Chronos endpoints for production use in a few lines of code.
🚀 Update Nov 27, 2024: We have released Chronos-Bolt⚡️ models that are more accurate (5% lower error), up to 250 times faster and 20 times more memory-efficient than the original Chronos models of the same size. Check out the new models here.
Chronos is a family of pretrained time series forecasting models based on language model architectures. A time series is transformed into a sequence of tokens via scaling and quantization, and a language model is trained on these tokens using the cross-entropy loss. Once trained, probabilistic forecasts are obtained by sampling multiple future trajectories given the historical context. Chronos models have been trained on a large corpus of publicly available time series data, as well as synthetic data generated using Gaussian processes.
For details on Chronos models, training data and procedures, and experimental results, please refer to the paper Chronos: Learning the Language of Time Series.
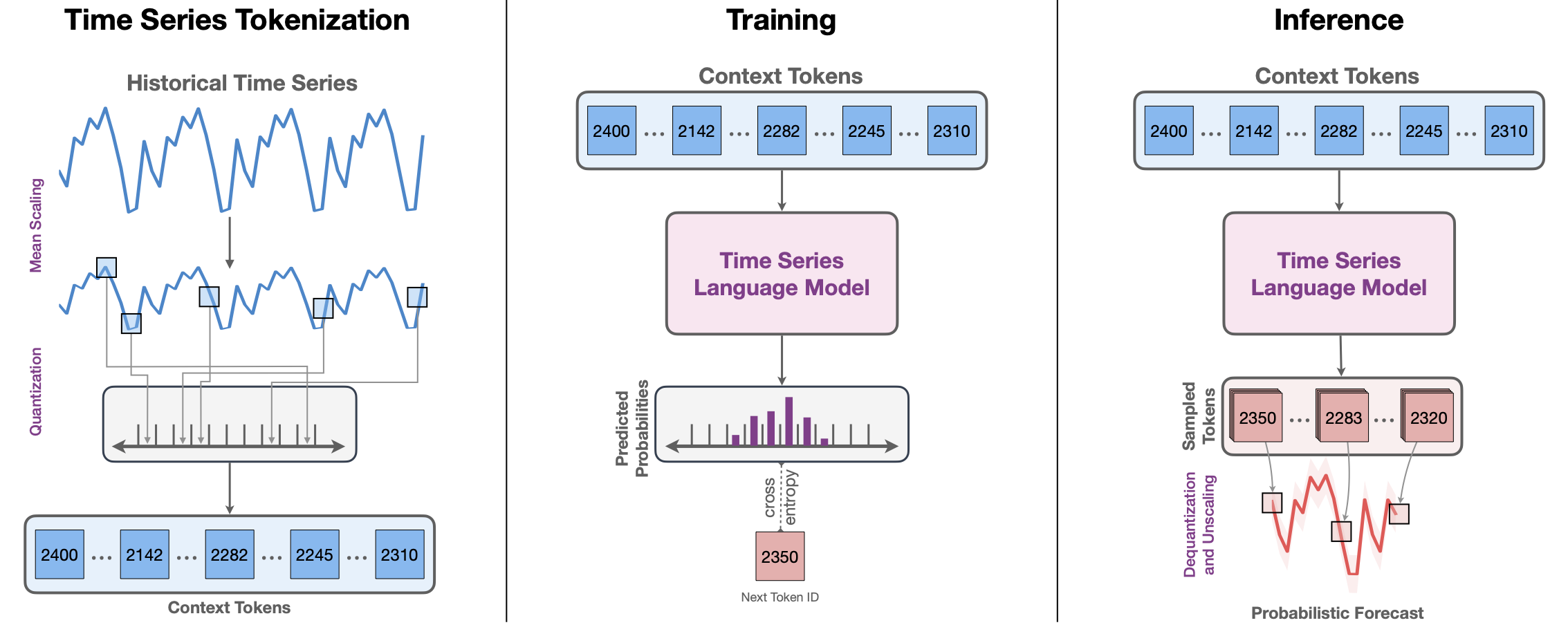
Fig. 1: High-level depiction of Chronos. (Left) The input time series is scaled and quantized to obtain a sequence of tokens. (Center) The tokens are fed into a language model which may either be an encoder-decoder or a decoder-only model. The model is trained using the cross-entropy loss. (Right) During inference, we autoregressively sample tokens from the model and map them back to numerical values. Multiple trajectories are sampled to obtain a predictive distribution.
The models in this repository are based on the T5 architecture. The only difference is in the vocabulary size: Chronos-T5 models use 4096 different tokens, compared to 32128 of the original T5 models, resulting in fewer parameters.
| Model | Parameters | Based on |
|---|---|---|
| chronos-t5-tiny | 8M | t5-efficient-tiny |
| chronos-t5-mini | 20M | t5-efficient-mini |
| chronos-t5-small | 46M | t5-efficient-small |
| chronos-t5-base | 200M | t5-efficient-base |
| chronos-t5-large | 710M | t5-efficient-large |
To perform inference with Chronos models, install the package in the GitHub companion repo by running:
pip install git+https://github.com/amazon-science/chronos-forecasting.git
A minimal example showing how to perform inference using Chronos models:
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import torch
from chronos import ChronosPipeline
pipeline = ChronosPipeline.from_pretrained(
"amazon/chronos-t5-large",
device_map="cuda",
torch_dtype=torch.bfloat16,
)
df = pd.read_csv("https://raw.githubusercontent.com/AileenNielsen/TimeSeriesAnalysisWithPython/master/data/AirPassengers.csv")
# context must be either a 1D tensor, a list of 1D tensors,
# or a left-padded 2D tensor with batch as the first dimension
context = torch.tensor(df["#Passengers"])
prediction_length = 12
forecast = pipeline.predict(context, prediction_length) # shape [num_series, num_samples, prediction_length]
# visualize the forecast
forecast_index = range(len(df), len(df) + prediction_length)
low, median, high = np.quantile(forecast[0].numpy(), [0.1, 0.5, 0.9], axis=0)
plt.figure(figsize=(8, 4))
plt.plot(df["#Passengers"], color="royalblue", label="historical data")
plt.plot(forecast_index, median, color="tomato", label="median forecast")
plt.fill_between(forecast_index, low, high, color="tomato", alpha=0.3, label="80% prediction interval")
plt.legend()
plt.grid()
plt.show()
If you find Chronos models useful for your research, please consider citing the associated paper:
@article{ansari2024chronos,
title={Chronos: Learning the Language of Time Series},
author={Ansari, Abdul Fatir and Stella, Lorenzo and Turkmen, Caner and Zhang, Xiyuan, and Mercado, Pedro and Shen, Huibin and Shchur, Oleksandr and Rangapuram, Syama Syndar and Pineda Arango, Sebastian and Kapoor, Shubham and Zschiegner, Jasper and Maddix, Danielle C. and Mahoney, Michael W. and Torkkola, Kari and Gordon Wilson, Andrew and Bohlke-Schneider, Michael and Wang, Yuyang},
journal={Transactions on Machine Learning Research},
issn={2835-8856},
year={2024},
url={https://openreview.net/forum?id=gerNCVqqtR}
}
See CONTRIBUTING for more information.
This project is licensed under the Apache-2.0 License.