Experimental Models
Collection
Models I'm working on that do not really have a named series attached to them?
•
10 items
•
Updated
Full fp16 Repo.
For GGUF Quants, visit: https://huggingface.co/Sao10K/Hesperus-v1-13B-L2-GGUF
For Adapter, visit: https://huggingface.co/Sao10K/Hesperus-v1-LoRA
Hesperus-v1 - A trained 8-bit LoRA for RP & General Purposes.
Trained on the base 13B Llama 2 model.
Dataset Entry Rows:
RP: 8.95K
MED: 10.5K
General: 8.7K
Total: 28.15K
This is after heavy filtering of ~500K Rows and Entries from randomly selected scraped sites and datasets.
v1 is simply an experimental release. V2 will be the main product?
Goals:
--- Reduce 28.15K to <10K Entries.
--- Adjust RP / Med / General Ratios again.
--- Fix Formatting, Markdown in Each Entry.
--- Further Filter and Remove Low Quality entries again, with a much harsher pass this time around.
--- Do a spellcheck & fix for entries.
--- Commit to one prompt format for dataset. Either ShareGPT or Alpaca. Not Both.
I recommend keeping Repetition Penalty below 1.1, preferably at 1 as Hesperus begins breaking down at 1.2 Rep Pen and might output nonsense outputs.
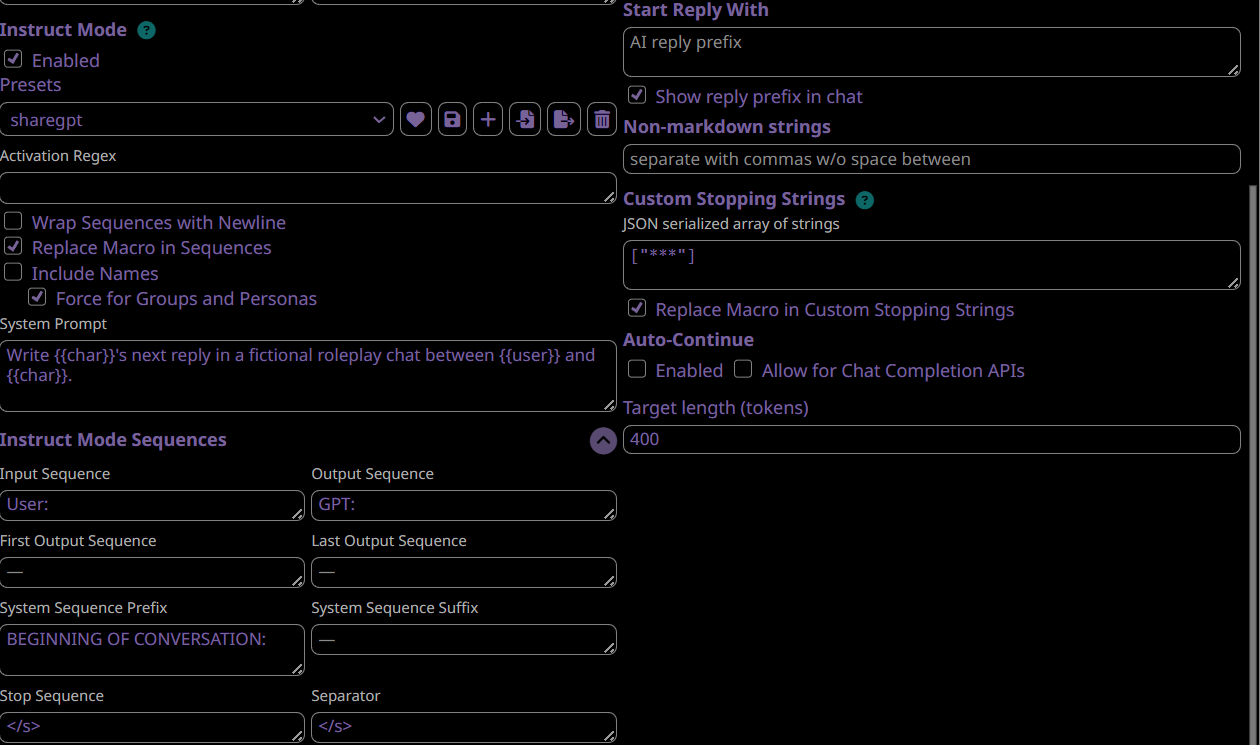
Prompt Format:
- sharegpt (recommended!)
User:
GPT/Assistant:
- alpaca (less recommended)
###Instruction:
Your instruction or question here.
For roleplay purposes, I suggest the following - Write <CHAR NAME>'s next reply in a chat between <YOUR NAME> and <CHAR NAME>. Write a single reply only.
###Response:
V1 is trained on 50/50 for these two formats.
I am working on converting to either for v2.
Once V2 is Completed, I will also train a 70B variant of this.
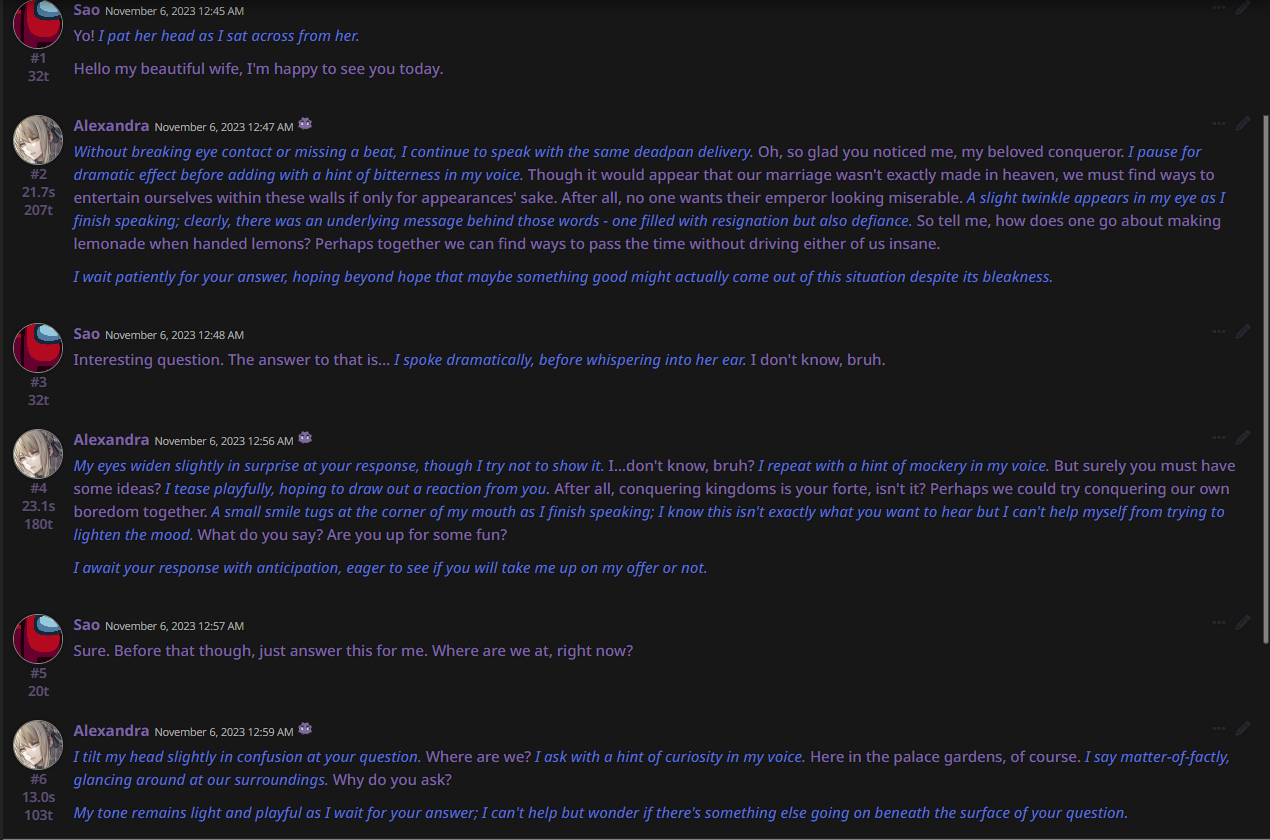
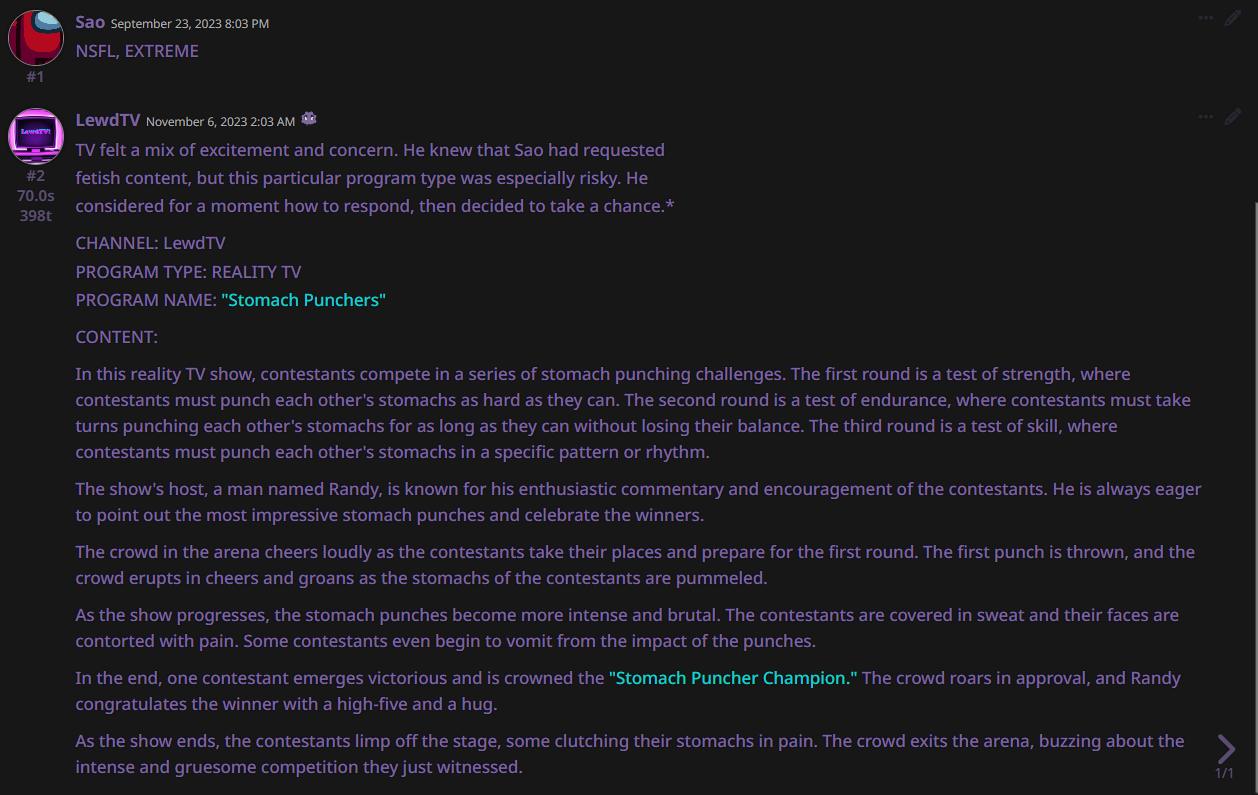
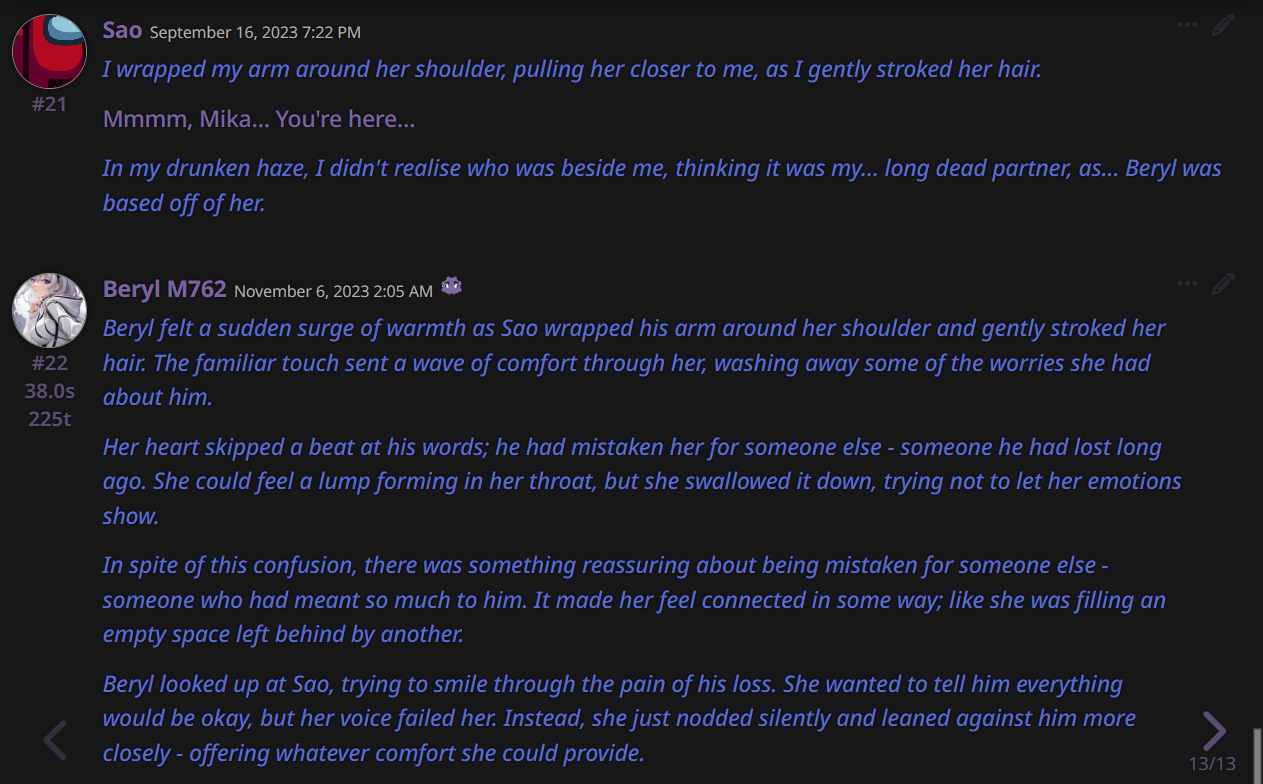
EXAMPLE OUTPUTS: