
Upload folder using huggingface_hub
#1
by
sharpenb
- opened
- README.md +84 -0
- config.json +49 -0
- generation_config.json +10 -0
- model-00001-of-00002.safetensors +3 -0
- model-00002-of-00002.safetensors +3 -0
- model.safetensors.index.json +522 -0
- modeling_flash_llama.py +1010 -0
- plots.png +0 -0
- smash_config.json +27 -0
README.md
ADDED
|
@@ -0,0 +1,84 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
thumbnail: "https://assets-global.website-files.com/646b351987a8d8ce158d1940/64ec9e96b4334c0e1ac41504_Logo%20with%20white%20text.svg"
|
| 3 |
+
metrics:
|
| 4 |
+
- memory_disk
|
| 5 |
+
- memory_inference
|
| 6 |
+
- inference_latency
|
| 7 |
+
- inference_throughput
|
| 8 |
+
- inference_CO2_emissions
|
| 9 |
+
- inference_energy_consumption
|
| 10 |
+
tags:
|
| 11 |
+
- pruna-ai
|
| 12 |
+
---
|
| 13 |
+
<!-- header start -->
|
| 14 |
+
<!-- 200823 -->
|
| 15 |
+
<div style="width: auto; margin-left: auto; margin-right: auto">
|
| 16 |
+
<a href="https://www.pruna.ai/" target="_blank" rel="noopener noreferrer">
|
| 17 |
+
<img src="https://i.imgur.com/eDAlcgk.png" alt="PrunaAI" style="width: 100%; min-width: 400px; display: block; margin: auto;">
|
| 18 |
+
</a>
|
| 19 |
+
</div>
|
| 20 |
+
<!-- header end -->
|
| 21 |
+
|
| 22 |
+
[](https://twitter.com/PrunaAI)
|
| 23 |
+
[](https://github.com/PrunaAI)
|
| 24 |
+
[](https://www.linkedin.com/company/93832878/admin/feed/posts/?feedType=following)
|
| 25 |
+
[](https://discord.gg/CP4VSgck)
|
| 26 |
+
|
| 27 |
+
# Simply make AI models cheaper, smaller, faster, and greener!
|
| 28 |
+
|
| 29 |
+
- Give a thumbs up if you like this model!
|
| 30 |
+
- Contact us and tell us which model to compress next [here](https://www.pruna.ai/contact).
|
| 31 |
+
- Request access to easily compress your *own* AI models [here](https://z0halsaff74.typeform.com/pruna-access?typeform-source=www.pruna.ai).
|
| 32 |
+
- Read the documentations to know more [here](https://pruna-ai-pruna.readthedocs-hosted.com/en/latest/)
|
| 33 |
+
- Join Pruna AI community on Discord [here](https://discord.gg/CP4VSgck) to share feedback/suggestions or get help.
|
| 34 |
+
|
| 35 |
+
## Results
|
| 36 |
+
|
| 37 |
+

|
| 38 |
+
|
| 39 |
+
**Frequently Asked Questions**
|
| 40 |
+
- ***How does the compression work?*** The model is compressed with llm-int8.
|
| 41 |
+
- ***How does the model quality change?*** The quality of the model output might vary compared to the base model.
|
| 42 |
+
- ***How is the model efficiency evaluated?*** These results were obtained on NVIDIA A100-PCIE-40GB with configuration described in `model/smash_config.json` and are obtained after a hardware warmup. The smashed model is directly compared to the original base model. Efficiency results may vary in other settings (e.g. other hardware, image size, batch size, ...). We recommend to directly run them in the use-case conditions to know if the smashed model can benefit you.
|
| 43 |
+
- ***What is the model format?*** We use safetensors.
|
| 44 |
+
- ***What calibration data has been used?*** If needed by the compression method, we used WikiText as the calibration data.
|
| 45 |
+
- ***What is the naming convention for Pruna Huggingface models?*** We take the original model name and append "turbo", "tiny", or "green" if the smashed model has a measured inference speed, inference memory, or inference energy consumption which is less than 90% of the original base model.
|
| 46 |
+
- ***How to compress my own models?*** You can request premium access to more compression methods and tech support for your specific use-cases [here](https://z0halsaff74.typeform.com/pruna-access?typeform-source=www.pruna.ai).
|
| 47 |
+
- ***What are "first" metrics?*** Results mentioning "first" are obtained after the first run of the model. The first run might take more memory or be slower than the subsequent runs due cuda overheads.
|
| 48 |
+
- ***What are "Sync" and "Async" metrics?*** "Sync" metrics are obtained by syncing all GPU processes and stop measurement when all of them are executed. "Async" metrics are obtained without syncing all GPU processes and stop when the model output can be used by the CPU. We provide both metrics since both could be relevant depending on the use-case. We recommend to test the efficiency gains directly in your use-cases.
|
| 49 |
+
|
| 50 |
+
## Setup
|
| 51 |
+
|
| 52 |
+
You can run the smashed model with these steps:
|
| 53 |
+
|
| 54 |
+
0. Check requirements from the original repo LeoLM/leo-hessianai-7b installed. In particular, check python, cuda, and transformers versions.
|
| 55 |
+
1. Make sure that you have installed quantization related packages.
|
| 56 |
+
```bash
|
| 57 |
+
pip install transformers accelerate bitsandbytes>0.37.0
|
| 58 |
+
```
|
| 59 |
+
2. Load & run the model.
|
| 60 |
+
```python
|
| 61 |
+
from transformers import AutoModelForCausalLM, AutoTokenizer
|
| 62 |
+
|
| 63 |
+
model = AutoModelForCausalLM.from_pretrained("PrunaAI/LeoLM-leo-hessianai-7b-bnb-8bit-smashed",
|
| 64 |
+
trust_remote_code=True)
|
| 65 |
+
tokenizer = AutoTokenizer.from_pretrained("LeoLM/leo-hessianai-7b")
|
| 66 |
+
|
| 67 |
+
input_ids = tokenizer("What is the color of prunes?,", return_tensors='pt').to(model.device)["input_ids"]
|
| 68 |
+
|
| 69 |
+
outputs = model.generate(input_ids, max_new_tokens=216)
|
| 70 |
+
tokenizer.decode(outputs[0])
|
| 71 |
+
```
|
| 72 |
+
|
| 73 |
+
## Configurations
|
| 74 |
+
|
| 75 |
+
The configuration info are in `smash_config.json`.
|
| 76 |
+
|
| 77 |
+
## Credits & License
|
| 78 |
+
|
| 79 |
+
The license of the smashed model follows the license of the original model. Please check the license of the original model LeoLM/leo-hessianai-7b before using this model which provided the base model. The license of the `pruna-engine` is [here](https://pypi.org/project/pruna-engine/) on Pypi.
|
| 80 |
+
|
| 81 |
+
## Want to compress other models?
|
| 82 |
+
|
| 83 |
+
- Contact us and tell us which model to compress next [here](https://www.pruna.ai/contact).
|
| 84 |
+
- Request access to easily compress your own AI models [here](https://z0halsaff74.typeform.com/pruna-access?typeform-source=www.pruna.ai).
|
config.json
ADDED
|
@@ -0,0 +1,49 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_name_or_path": "/tmp/tmp2w_7l41c",
|
| 3 |
+
"architectures": [
|
| 4 |
+
"LlamaForCausalLM"
|
| 5 |
+
],
|
| 6 |
+
"attention_bias": false,
|
| 7 |
+
"attention_dropout": 0.0,
|
| 8 |
+
"auto_map": {
|
| 9 |
+
"AutoModelForCausalLM": "modeling_flash_llama.LlamaForCausalLM"
|
| 10 |
+
},
|
| 11 |
+
"bos_token_id": 1,
|
| 12 |
+
"eos_token_id": 2,
|
| 13 |
+
"hidden_act": "silu",
|
| 14 |
+
"hidden_size": 4096,
|
| 15 |
+
"initializer_range": 0.02,
|
| 16 |
+
"intermediate_size": 11008,
|
| 17 |
+
"max_position_embeddings": 8192,
|
| 18 |
+
"model_type": "llama",
|
| 19 |
+
"num_attention_heads": 32,
|
| 20 |
+
"num_hidden_layers": 32,
|
| 21 |
+
"num_key_value_heads": 32,
|
| 22 |
+
"pad_token_id": 0,
|
| 23 |
+
"pretraining_tp": 1,
|
| 24 |
+
"quantization_config": {
|
| 25 |
+
"bnb_4bit_compute_dtype": "bfloat16",
|
| 26 |
+
"bnb_4bit_quant_type": "fp4",
|
| 27 |
+
"bnb_4bit_use_double_quant": true,
|
| 28 |
+
"llm_int8_enable_fp32_cpu_offload": false,
|
| 29 |
+
"llm_int8_has_fp16_weight": false,
|
| 30 |
+
"llm_int8_skip_modules": [
|
| 31 |
+
"lm_head"
|
| 32 |
+
],
|
| 33 |
+
"llm_int8_threshold": 6.0,
|
| 34 |
+
"load_in_4bit": false,
|
| 35 |
+
"load_in_8bit": true,
|
| 36 |
+
"quant_method": "bitsandbytes"
|
| 37 |
+
},
|
| 38 |
+
"rms_norm_eps": 1e-05,
|
| 39 |
+
"rope_scaling": {
|
| 40 |
+
"factor": 2.0,
|
| 41 |
+
"type": "linear"
|
| 42 |
+
},
|
| 43 |
+
"rope_theta": 10000.0,
|
| 44 |
+
"tie_word_embeddings": false,
|
| 45 |
+
"torch_dtype": "float16",
|
| 46 |
+
"transformers_version": "4.37.1",
|
| 47 |
+
"use_cache": true,
|
| 48 |
+
"vocab_size": 32000
|
| 49 |
+
}
|
generation_config.json
ADDED
|
@@ -0,0 +1,10 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"bos_token_id": 1,
|
| 3 |
+
"do_sample": true,
|
| 4 |
+
"eos_token_id": 2,
|
| 5 |
+
"max_length": 4096,
|
| 6 |
+
"pad_token_id": 0,
|
| 7 |
+
"temperature": 0.6,
|
| 8 |
+
"top_p": 0.9,
|
| 9 |
+
"transformers_version": "4.37.1"
|
| 10 |
+
}
|
model-00001-of-00002.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:59de5343a3370f133c1b526f7209887918504b8deb55ccc46fae05023e64cf24
|
| 3 |
+
size 4988274536
|
model-00002-of-00002.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:72b4ca9fa624281ec475e35391ad567e9368bb1d6f26b839ef4359328ab58548
|
| 3 |
+
size 2018046512
|
model.safetensors.index.json
ADDED
|
@@ -0,0 +1,522 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"metadata": {
|
| 3 |
+
"total_size": 7006265344
|
| 4 |
+
},
|
| 5 |
+
"weight_map": {
|
| 6 |
+
"lm_head.weight": "model-00002-of-00002.safetensors",
|
| 7 |
+
"model.embed_tokens.weight": "model-00001-of-00002.safetensors",
|
| 8 |
+
"model.layers.0.input_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 9 |
+
"model.layers.0.mlp.down_proj.SCB": "model-00001-of-00002.safetensors",
|
| 10 |
+
"model.layers.0.mlp.down_proj.weight": "model-00001-of-00002.safetensors",
|
| 11 |
+
"model.layers.0.mlp.gate_proj.SCB": "model-00001-of-00002.safetensors",
|
| 12 |
+
"model.layers.0.mlp.gate_proj.weight": "model-00001-of-00002.safetensors",
|
| 13 |
+
"model.layers.0.mlp.up_proj.SCB": "model-00001-of-00002.safetensors",
|
| 14 |
+
"model.layers.0.mlp.up_proj.weight": "model-00001-of-00002.safetensors",
|
| 15 |
+
"model.layers.0.post_attention_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 16 |
+
"model.layers.0.self_attn.k_proj.SCB": "model-00001-of-00002.safetensors",
|
| 17 |
+
"model.layers.0.self_attn.k_proj.weight": "model-00001-of-00002.safetensors",
|
| 18 |
+
"model.layers.0.self_attn.o_proj.SCB": "model-00001-of-00002.safetensors",
|
| 19 |
+
"model.layers.0.self_attn.o_proj.weight": "model-00001-of-00002.safetensors",
|
| 20 |
+
"model.layers.0.self_attn.q_proj.SCB": "model-00001-of-00002.safetensors",
|
| 21 |
+
"model.layers.0.self_attn.q_proj.weight": "model-00001-of-00002.safetensors",
|
| 22 |
+
"model.layers.0.self_attn.v_proj.SCB": "model-00001-of-00002.safetensors",
|
| 23 |
+
"model.layers.0.self_attn.v_proj.weight": "model-00001-of-00002.safetensors",
|
| 24 |
+
"model.layers.1.input_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 25 |
+
"model.layers.1.mlp.down_proj.SCB": "model-00001-of-00002.safetensors",
|
| 26 |
+
"model.layers.1.mlp.down_proj.weight": "model-00001-of-00002.safetensors",
|
| 27 |
+
"model.layers.1.mlp.gate_proj.SCB": "model-00001-of-00002.safetensors",
|
| 28 |
+
"model.layers.1.mlp.gate_proj.weight": "model-00001-of-00002.safetensors",
|
| 29 |
+
"model.layers.1.mlp.up_proj.SCB": "model-00001-of-00002.safetensors",
|
| 30 |
+
"model.layers.1.mlp.up_proj.weight": "model-00001-of-00002.safetensors",
|
| 31 |
+
"model.layers.1.post_attention_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 32 |
+
"model.layers.1.self_attn.k_proj.SCB": "model-00001-of-00002.safetensors",
|
| 33 |
+
"model.layers.1.self_attn.k_proj.weight": "model-00001-of-00002.safetensors",
|
| 34 |
+
"model.layers.1.self_attn.o_proj.SCB": "model-00001-of-00002.safetensors",
|
| 35 |
+
"model.layers.1.self_attn.o_proj.weight": "model-00001-of-00002.safetensors",
|
| 36 |
+
"model.layers.1.self_attn.q_proj.SCB": "model-00001-of-00002.safetensors",
|
| 37 |
+
"model.layers.1.self_attn.q_proj.weight": "model-00001-of-00002.safetensors",
|
| 38 |
+
"model.layers.1.self_attn.v_proj.SCB": "model-00001-of-00002.safetensors",
|
| 39 |
+
"model.layers.1.self_attn.v_proj.weight": "model-00001-of-00002.safetensors",
|
| 40 |
+
"model.layers.10.input_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 41 |
+
"model.layers.10.mlp.down_proj.SCB": "model-00001-of-00002.safetensors",
|
| 42 |
+
"model.layers.10.mlp.down_proj.weight": "model-00001-of-00002.safetensors",
|
| 43 |
+
"model.layers.10.mlp.gate_proj.SCB": "model-00001-of-00002.safetensors",
|
| 44 |
+
"model.layers.10.mlp.gate_proj.weight": "model-00001-of-00002.safetensors",
|
| 45 |
+
"model.layers.10.mlp.up_proj.SCB": "model-00001-of-00002.safetensors",
|
| 46 |
+
"model.layers.10.mlp.up_proj.weight": "model-00001-of-00002.safetensors",
|
| 47 |
+
"model.layers.10.post_attention_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 48 |
+
"model.layers.10.self_attn.k_proj.SCB": "model-00001-of-00002.safetensors",
|
| 49 |
+
"model.layers.10.self_attn.k_proj.weight": "model-00001-of-00002.safetensors",
|
| 50 |
+
"model.layers.10.self_attn.o_proj.SCB": "model-00001-of-00002.safetensors",
|
| 51 |
+
"model.layers.10.self_attn.o_proj.weight": "model-00001-of-00002.safetensors",
|
| 52 |
+
"model.layers.10.self_attn.q_proj.SCB": "model-00001-of-00002.safetensors",
|
| 53 |
+
"model.layers.10.self_attn.q_proj.weight": "model-00001-of-00002.safetensors",
|
| 54 |
+
"model.layers.10.self_attn.v_proj.SCB": "model-00001-of-00002.safetensors",
|
| 55 |
+
"model.layers.10.self_attn.v_proj.weight": "model-00001-of-00002.safetensors",
|
| 56 |
+
"model.layers.11.input_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 57 |
+
"model.layers.11.mlp.down_proj.SCB": "model-00001-of-00002.safetensors",
|
| 58 |
+
"model.layers.11.mlp.down_proj.weight": "model-00001-of-00002.safetensors",
|
| 59 |
+
"model.layers.11.mlp.gate_proj.SCB": "model-00001-of-00002.safetensors",
|
| 60 |
+
"model.layers.11.mlp.gate_proj.weight": "model-00001-of-00002.safetensors",
|
| 61 |
+
"model.layers.11.mlp.up_proj.SCB": "model-00001-of-00002.safetensors",
|
| 62 |
+
"model.layers.11.mlp.up_proj.weight": "model-00001-of-00002.safetensors",
|
| 63 |
+
"model.layers.11.post_attention_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 64 |
+
"model.layers.11.self_attn.k_proj.SCB": "model-00001-of-00002.safetensors",
|
| 65 |
+
"model.layers.11.self_attn.k_proj.weight": "model-00001-of-00002.safetensors",
|
| 66 |
+
"model.layers.11.self_attn.o_proj.SCB": "model-00001-of-00002.safetensors",
|
| 67 |
+
"model.layers.11.self_attn.o_proj.weight": "model-00001-of-00002.safetensors",
|
| 68 |
+
"model.layers.11.self_attn.q_proj.SCB": "model-00001-of-00002.safetensors",
|
| 69 |
+
"model.layers.11.self_attn.q_proj.weight": "model-00001-of-00002.safetensors",
|
| 70 |
+
"model.layers.11.self_attn.v_proj.SCB": "model-00001-of-00002.safetensors",
|
| 71 |
+
"model.layers.11.self_attn.v_proj.weight": "model-00001-of-00002.safetensors",
|
| 72 |
+
"model.layers.12.input_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 73 |
+
"model.layers.12.mlp.down_proj.SCB": "model-00001-of-00002.safetensors",
|
| 74 |
+
"model.layers.12.mlp.down_proj.weight": "model-00001-of-00002.safetensors",
|
| 75 |
+
"model.layers.12.mlp.gate_proj.SCB": "model-00001-of-00002.safetensors",
|
| 76 |
+
"model.layers.12.mlp.gate_proj.weight": "model-00001-of-00002.safetensors",
|
| 77 |
+
"model.layers.12.mlp.up_proj.SCB": "model-00001-of-00002.safetensors",
|
| 78 |
+
"model.layers.12.mlp.up_proj.weight": "model-00001-of-00002.safetensors",
|
| 79 |
+
"model.layers.12.post_attention_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 80 |
+
"model.layers.12.self_attn.k_proj.SCB": "model-00001-of-00002.safetensors",
|
| 81 |
+
"model.layers.12.self_attn.k_proj.weight": "model-00001-of-00002.safetensors",
|
| 82 |
+
"model.layers.12.self_attn.o_proj.SCB": "model-00001-of-00002.safetensors",
|
| 83 |
+
"model.layers.12.self_attn.o_proj.weight": "model-00001-of-00002.safetensors",
|
| 84 |
+
"model.layers.12.self_attn.q_proj.SCB": "model-00001-of-00002.safetensors",
|
| 85 |
+
"model.layers.12.self_attn.q_proj.weight": "model-00001-of-00002.safetensors",
|
| 86 |
+
"model.layers.12.self_attn.v_proj.SCB": "model-00001-of-00002.safetensors",
|
| 87 |
+
"model.layers.12.self_attn.v_proj.weight": "model-00001-of-00002.safetensors",
|
| 88 |
+
"model.layers.13.input_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 89 |
+
"model.layers.13.mlp.down_proj.SCB": "model-00001-of-00002.safetensors",
|
| 90 |
+
"model.layers.13.mlp.down_proj.weight": "model-00001-of-00002.safetensors",
|
| 91 |
+
"model.layers.13.mlp.gate_proj.SCB": "model-00001-of-00002.safetensors",
|
| 92 |
+
"model.layers.13.mlp.gate_proj.weight": "model-00001-of-00002.safetensors",
|
| 93 |
+
"model.layers.13.mlp.up_proj.SCB": "model-00001-of-00002.safetensors",
|
| 94 |
+
"model.layers.13.mlp.up_proj.weight": "model-00001-of-00002.safetensors",
|
| 95 |
+
"model.layers.13.post_attention_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 96 |
+
"model.layers.13.self_attn.k_proj.SCB": "model-00001-of-00002.safetensors",
|
| 97 |
+
"model.layers.13.self_attn.k_proj.weight": "model-00001-of-00002.safetensors",
|
| 98 |
+
"model.layers.13.self_attn.o_proj.SCB": "model-00001-of-00002.safetensors",
|
| 99 |
+
"model.layers.13.self_attn.o_proj.weight": "model-00001-of-00002.safetensors",
|
| 100 |
+
"model.layers.13.self_attn.q_proj.SCB": "model-00001-of-00002.safetensors",
|
| 101 |
+
"model.layers.13.self_attn.q_proj.weight": "model-00001-of-00002.safetensors",
|
| 102 |
+
"model.layers.13.self_attn.v_proj.SCB": "model-00001-of-00002.safetensors",
|
| 103 |
+
"model.layers.13.self_attn.v_proj.weight": "model-00001-of-00002.safetensors",
|
| 104 |
+
"model.layers.14.input_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 105 |
+
"model.layers.14.mlp.down_proj.SCB": "model-00001-of-00002.safetensors",
|
| 106 |
+
"model.layers.14.mlp.down_proj.weight": "model-00001-of-00002.safetensors",
|
| 107 |
+
"model.layers.14.mlp.gate_proj.SCB": "model-00001-of-00002.safetensors",
|
| 108 |
+
"model.layers.14.mlp.gate_proj.weight": "model-00001-of-00002.safetensors",
|
| 109 |
+
"model.layers.14.mlp.up_proj.SCB": "model-00001-of-00002.safetensors",
|
| 110 |
+
"model.layers.14.mlp.up_proj.weight": "model-00001-of-00002.safetensors",
|
| 111 |
+
"model.layers.14.post_attention_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 112 |
+
"model.layers.14.self_attn.k_proj.SCB": "model-00001-of-00002.safetensors",
|
| 113 |
+
"model.layers.14.self_attn.k_proj.weight": "model-00001-of-00002.safetensors",
|
| 114 |
+
"model.layers.14.self_attn.o_proj.SCB": "model-00001-of-00002.safetensors",
|
| 115 |
+
"model.layers.14.self_attn.o_proj.weight": "model-00001-of-00002.safetensors",
|
| 116 |
+
"model.layers.14.self_attn.q_proj.SCB": "model-00001-of-00002.safetensors",
|
| 117 |
+
"model.layers.14.self_attn.q_proj.weight": "model-00001-of-00002.safetensors",
|
| 118 |
+
"model.layers.14.self_attn.v_proj.SCB": "model-00001-of-00002.safetensors",
|
| 119 |
+
"model.layers.14.self_attn.v_proj.weight": "model-00001-of-00002.safetensors",
|
| 120 |
+
"model.layers.15.input_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 121 |
+
"model.layers.15.mlp.down_proj.SCB": "model-00001-of-00002.safetensors",
|
| 122 |
+
"model.layers.15.mlp.down_proj.weight": "model-00001-of-00002.safetensors",
|
| 123 |
+
"model.layers.15.mlp.gate_proj.SCB": "model-00001-of-00002.safetensors",
|
| 124 |
+
"model.layers.15.mlp.gate_proj.weight": "model-00001-of-00002.safetensors",
|
| 125 |
+
"model.layers.15.mlp.up_proj.SCB": "model-00001-of-00002.safetensors",
|
| 126 |
+
"model.layers.15.mlp.up_proj.weight": "model-00001-of-00002.safetensors",
|
| 127 |
+
"model.layers.15.post_attention_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 128 |
+
"model.layers.15.self_attn.k_proj.SCB": "model-00001-of-00002.safetensors",
|
| 129 |
+
"model.layers.15.self_attn.k_proj.weight": "model-00001-of-00002.safetensors",
|
| 130 |
+
"model.layers.15.self_attn.o_proj.SCB": "model-00001-of-00002.safetensors",
|
| 131 |
+
"model.layers.15.self_attn.o_proj.weight": "model-00001-of-00002.safetensors",
|
| 132 |
+
"model.layers.15.self_attn.q_proj.SCB": "model-00001-of-00002.safetensors",
|
| 133 |
+
"model.layers.15.self_attn.q_proj.weight": "model-00001-of-00002.safetensors",
|
| 134 |
+
"model.layers.15.self_attn.v_proj.SCB": "model-00001-of-00002.safetensors",
|
| 135 |
+
"model.layers.15.self_attn.v_proj.weight": "model-00001-of-00002.safetensors",
|
| 136 |
+
"model.layers.16.input_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 137 |
+
"model.layers.16.mlp.down_proj.SCB": "model-00001-of-00002.safetensors",
|
| 138 |
+
"model.layers.16.mlp.down_proj.weight": "model-00001-of-00002.safetensors",
|
| 139 |
+
"model.layers.16.mlp.gate_proj.SCB": "model-00001-of-00002.safetensors",
|
| 140 |
+
"model.layers.16.mlp.gate_proj.weight": "model-00001-of-00002.safetensors",
|
| 141 |
+
"model.layers.16.mlp.up_proj.SCB": "model-00001-of-00002.safetensors",
|
| 142 |
+
"model.layers.16.mlp.up_proj.weight": "model-00001-of-00002.safetensors",
|
| 143 |
+
"model.layers.16.post_attention_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 144 |
+
"model.layers.16.self_attn.k_proj.SCB": "model-00001-of-00002.safetensors",
|
| 145 |
+
"model.layers.16.self_attn.k_proj.weight": "model-00001-of-00002.safetensors",
|
| 146 |
+
"model.layers.16.self_attn.o_proj.SCB": "model-00001-of-00002.safetensors",
|
| 147 |
+
"model.layers.16.self_attn.o_proj.weight": "model-00001-of-00002.safetensors",
|
| 148 |
+
"model.layers.16.self_attn.q_proj.SCB": "model-00001-of-00002.safetensors",
|
| 149 |
+
"model.layers.16.self_attn.q_proj.weight": "model-00001-of-00002.safetensors",
|
| 150 |
+
"model.layers.16.self_attn.v_proj.SCB": "model-00001-of-00002.safetensors",
|
| 151 |
+
"model.layers.16.self_attn.v_proj.weight": "model-00001-of-00002.safetensors",
|
| 152 |
+
"model.layers.17.input_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 153 |
+
"model.layers.17.mlp.down_proj.SCB": "model-00001-of-00002.safetensors",
|
| 154 |
+
"model.layers.17.mlp.down_proj.weight": "model-00001-of-00002.safetensors",
|
| 155 |
+
"model.layers.17.mlp.gate_proj.SCB": "model-00001-of-00002.safetensors",
|
| 156 |
+
"model.layers.17.mlp.gate_proj.weight": "model-00001-of-00002.safetensors",
|
| 157 |
+
"model.layers.17.mlp.up_proj.SCB": "model-00001-of-00002.safetensors",
|
| 158 |
+
"model.layers.17.mlp.up_proj.weight": "model-00001-of-00002.safetensors",
|
| 159 |
+
"model.layers.17.post_attention_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 160 |
+
"model.layers.17.self_attn.k_proj.SCB": "model-00001-of-00002.safetensors",
|
| 161 |
+
"model.layers.17.self_attn.k_proj.weight": "model-00001-of-00002.safetensors",
|
| 162 |
+
"model.layers.17.self_attn.o_proj.SCB": "model-00001-of-00002.safetensors",
|
| 163 |
+
"model.layers.17.self_attn.o_proj.weight": "model-00001-of-00002.safetensors",
|
| 164 |
+
"model.layers.17.self_attn.q_proj.SCB": "model-00001-of-00002.safetensors",
|
| 165 |
+
"model.layers.17.self_attn.q_proj.weight": "model-00001-of-00002.safetensors",
|
| 166 |
+
"model.layers.17.self_attn.v_proj.SCB": "model-00001-of-00002.safetensors",
|
| 167 |
+
"model.layers.17.self_attn.v_proj.weight": "model-00001-of-00002.safetensors",
|
| 168 |
+
"model.layers.18.input_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 169 |
+
"model.layers.18.mlp.down_proj.SCB": "model-00001-of-00002.safetensors",
|
| 170 |
+
"model.layers.18.mlp.down_proj.weight": "model-00001-of-00002.safetensors",
|
| 171 |
+
"model.layers.18.mlp.gate_proj.SCB": "model-00001-of-00002.safetensors",
|
| 172 |
+
"model.layers.18.mlp.gate_proj.weight": "model-00001-of-00002.safetensors",
|
| 173 |
+
"model.layers.18.mlp.up_proj.SCB": "model-00001-of-00002.safetensors",
|
| 174 |
+
"model.layers.18.mlp.up_proj.weight": "model-00001-of-00002.safetensors",
|
| 175 |
+
"model.layers.18.post_attention_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 176 |
+
"model.layers.18.self_attn.k_proj.SCB": "model-00001-of-00002.safetensors",
|
| 177 |
+
"model.layers.18.self_attn.k_proj.weight": "model-00001-of-00002.safetensors",
|
| 178 |
+
"model.layers.18.self_attn.o_proj.SCB": "model-00001-of-00002.safetensors",
|
| 179 |
+
"model.layers.18.self_attn.o_proj.weight": "model-00001-of-00002.safetensors",
|
| 180 |
+
"model.layers.18.self_attn.q_proj.SCB": "model-00001-of-00002.safetensors",
|
| 181 |
+
"model.layers.18.self_attn.q_proj.weight": "model-00001-of-00002.safetensors",
|
| 182 |
+
"model.layers.18.self_attn.v_proj.SCB": "model-00001-of-00002.safetensors",
|
| 183 |
+
"model.layers.18.self_attn.v_proj.weight": "model-00001-of-00002.safetensors",
|
| 184 |
+
"model.layers.19.input_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 185 |
+
"model.layers.19.mlp.down_proj.SCB": "model-00001-of-00002.safetensors",
|
| 186 |
+
"model.layers.19.mlp.down_proj.weight": "model-00001-of-00002.safetensors",
|
| 187 |
+
"model.layers.19.mlp.gate_proj.SCB": "model-00001-of-00002.safetensors",
|
| 188 |
+
"model.layers.19.mlp.gate_proj.weight": "model-00001-of-00002.safetensors",
|
| 189 |
+
"model.layers.19.mlp.up_proj.SCB": "model-00001-of-00002.safetensors",
|
| 190 |
+
"model.layers.19.mlp.up_proj.weight": "model-00001-of-00002.safetensors",
|
| 191 |
+
"model.layers.19.post_attention_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 192 |
+
"model.layers.19.self_attn.k_proj.SCB": "model-00001-of-00002.safetensors",
|
| 193 |
+
"model.layers.19.self_attn.k_proj.weight": "model-00001-of-00002.safetensors",
|
| 194 |
+
"model.layers.19.self_attn.o_proj.SCB": "model-00001-of-00002.safetensors",
|
| 195 |
+
"model.layers.19.self_attn.o_proj.weight": "model-00001-of-00002.safetensors",
|
| 196 |
+
"model.layers.19.self_attn.q_proj.SCB": "model-00001-of-00002.safetensors",
|
| 197 |
+
"model.layers.19.self_attn.q_proj.weight": "model-00001-of-00002.safetensors",
|
| 198 |
+
"model.layers.19.self_attn.v_proj.SCB": "model-00001-of-00002.safetensors",
|
| 199 |
+
"model.layers.19.self_attn.v_proj.weight": "model-00001-of-00002.safetensors",
|
| 200 |
+
"model.layers.2.input_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 201 |
+
"model.layers.2.mlp.down_proj.SCB": "model-00001-of-00002.safetensors",
|
| 202 |
+
"model.layers.2.mlp.down_proj.weight": "model-00001-of-00002.safetensors",
|
| 203 |
+
"model.layers.2.mlp.gate_proj.SCB": "model-00001-of-00002.safetensors",
|
| 204 |
+
"model.layers.2.mlp.gate_proj.weight": "model-00001-of-00002.safetensors",
|
| 205 |
+
"model.layers.2.mlp.up_proj.SCB": "model-00001-of-00002.safetensors",
|
| 206 |
+
"model.layers.2.mlp.up_proj.weight": "model-00001-of-00002.safetensors",
|
| 207 |
+
"model.layers.2.post_attention_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 208 |
+
"model.layers.2.self_attn.k_proj.SCB": "model-00001-of-00002.safetensors",
|
| 209 |
+
"model.layers.2.self_attn.k_proj.weight": "model-00001-of-00002.safetensors",
|
| 210 |
+
"model.layers.2.self_attn.o_proj.SCB": "model-00001-of-00002.safetensors",
|
| 211 |
+
"model.layers.2.self_attn.o_proj.weight": "model-00001-of-00002.safetensors",
|
| 212 |
+
"model.layers.2.self_attn.q_proj.SCB": "model-00001-of-00002.safetensors",
|
| 213 |
+
"model.layers.2.self_attn.q_proj.weight": "model-00001-of-00002.safetensors",
|
| 214 |
+
"model.layers.2.self_attn.v_proj.SCB": "model-00001-of-00002.safetensors",
|
| 215 |
+
"model.layers.2.self_attn.v_proj.weight": "model-00001-of-00002.safetensors",
|
| 216 |
+
"model.layers.20.input_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 217 |
+
"model.layers.20.mlp.down_proj.SCB": "model-00001-of-00002.safetensors",
|
| 218 |
+
"model.layers.20.mlp.down_proj.weight": "model-00001-of-00002.safetensors",
|
| 219 |
+
"model.layers.20.mlp.gate_proj.SCB": "model-00001-of-00002.safetensors",
|
| 220 |
+
"model.layers.20.mlp.gate_proj.weight": "model-00001-of-00002.safetensors",
|
| 221 |
+
"model.layers.20.mlp.up_proj.SCB": "model-00001-of-00002.safetensors",
|
| 222 |
+
"model.layers.20.mlp.up_proj.weight": "model-00001-of-00002.safetensors",
|
| 223 |
+
"model.layers.20.post_attention_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 224 |
+
"model.layers.20.self_attn.k_proj.SCB": "model-00001-of-00002.safetensors",
|
| 225 |
+
"model.layers.20.self_attn.k_proj.weight": "model-00001-of-00002.safetensors",
|
| 226 |
+
"model.layers.20.self_attn.o_proj.SCB": "model-00001-of-00002.safetensors",
|
| 227 |
+
"model.layers.20.self_attn.o_proj.weight": "model-00001-of-00002.safetensors",
|
| 228 |
+
"model.layers.20.self_attn.q_proj.SCB": "model-00001-of-00002.safetensors",
|
| 229 |
+
"model.layers.20.self_attn.q_proj.weight": "model-00001-of-00002.safetensors",
|
| 230 |
+
"model.layers.20.self_attn.v_proj.SCB": "model-00001-of-00002.safetensors",
|
| 231 |
+
"model.layers.20.self_attn.v_proj.weight": "model-00001-of-00002.safetensors",
|
| 232 |
+
"model.layers.21.input_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 233 |
+
"model.layers.21.mlp.down_proj.SCB": "model-00001-of-00002.safetensors",
|
| 234 |
+
"model.layers.21.mlp.down_proj.weight": "model-00001-of-00002.safetensors",
|
| 235 |
+
"model.layers.21.mlp.gate_proj.SCB": "model-00001-of-00002.safetensors",
|
| 236 |
+
"model.layers.21.mlp.gate_proj.weight": "model-00001-of-00002.safetensors",
|
| 237 |
+
"model.layers.21.mlp.up_proj.SCB": "model-00001-of-00002.safetensors",
|
| 238 |
+
"model.layers.21.mlp.up_proj.weight": "model-00001-of-00002.safetensors",
|
| 239 |
+
"model.layers.21.post_attention_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 240 |
+
"model.layers.21.self_attn.k_proj.SCB": "model-00001-of-00002.safetensors",
|
| 241 |
+
"model.layers.21.self_attn.k_proj.weight": "model-00001-of-00002.safetensors",
|
| 242 |
+
"model.layers.21.self_attn.o_proj.SCB": "model-00001-of-00002.safetensors",
|
| 243 |
+
"model.layers.21.self_attn.o_proj.weight": "model-00001-of-00002.safetensors",
|
| 244 |
+
"model.layers.21.self_attn.q_proj.SCB": "model-00001-of-00002.safetensors",
|
| 245 |
+
"model.layers.21.self_attn.q_proj.weight": "model-00001-of-00002.safetensors",
|
| 246 |
+
"model.layers.21.self_attn.v_proj.SCB": "model-00001-of-00002.safetensors",
|
| 247 |
+
"model.layers.21.self_attn.v_proj.weight": "model-00001-of-00002.safetensors",
|
| 248 |
+
"model.layers.22.input_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 249 |
+
"model.layers.22.mlp.down_proj.SCB": "model-00001-of-00002.safetensors",
|
| 250 |
+
"model.layers.22.mlp.down_proj.weight": "model-00001-of-00002.safetensors",
|
| 251 |
+
"model.layers.22.mlp.gate_proj.SCB": "model-00001-of-00002.safetensors",
|
| 252 |
+
"model.layers.22.mlp.gate_proj.weight": "model-00001-of-00002.safetensors",
|
| 253 |
+
"model.layers.22.mlp.up_proj.SCB": "model-00001-of-00002.safetensors",
|
| 254 |
+
"model.layers.22.mlp.up_proj.weight": "model-00001-of-00002.safetensors",
|
| 255 |
+
"model.layers.22.post_attention_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 256 |
+
"model.layers.22.self_attn.k_proj.SCB": "model-00001-of-00002.safetensors",
|
| 257 |
+
"model.layers.22.self_attn.k_proj.weight": "model-00001-of-00002.safetensors",
|
| 258 |
+
"model.layers.22.self_attn.o_proj.SCB": "model-00001-of-00002.safetensors",
|
| 259 |
+
"model.layers.22.self_attn.o_proj.weight": "model-00001-of-00002.safetensors",
|
| 260 |
+
"model.layers.22.self_attn.q_proj.SCB": "model-00001-of-00002.safetensors",
|
| 261 |
+
"model.layers.22.self_attn.q_proj.weight": "model-00001-of-00002.safetensors",
|
| 262 |
+
"model.layers.22.self_attn.v_proj.SCB": "model-00001-of-00002.safetensors",
|
| 263 |
+
"model.layers.22.self_attn.v_proj.weight": "model-00001-of-00002.safetensors",
|
| 264 |
+
"model.layers.23.input_layernorm.weight": "model-00002-of-00002.safetensors",
|
| 265 |
+
"model.layers.23.mlp.down_proj.SCB": "model-00002-of-00002.safetensors",
|
| 266 |
+
"model.layers.23.mlp.down_proj.weight": "model-00002-of-00002.safetensors",
|
| 267 |
+
"model.layers.23.mlp.gate_proj.SCB": "model-00002-of-00002.safetensors",
|
| 268 |
+
"model.layers.23.mlp.gate_proj.weight": "model-00002-of-00002.safetensors",
|
| 269 |
+
"model.layers.23.mlp.up_proj.SCB": "model-00002-of-00002.safetensors",
|
| 270 |
+
"model.layers.23.mlp.up_proj.weight": "model-00002-of-00002.safetensors",
|
| 271 |
+
"model.layers.23.post_attention_layernorm.weight": "model-00002-of-00002.safetensors",
|
| 272 |
+
"model.layers.23.self_attn.k_proj.SCB": "model-00001-of-00002.safetensors",
|
| 273 |
+
"model.layers.23.self_attn.k_proj.weight": "model-00001-of-00002.safetensors",
|
| 274 |
+
"model.layers.23.self_attn.o_proj.SCB": "model-00001-of-00002.safetensors",
|
| 275 |
+
"model.layers.23.self_attn.o_proj.weight": "model-00001-of-00002.safetensors",
|
| 276 |
+
"model.layers.23.self_attn.q_proj.SCB": "model-00001-of-00002.safetensors",
|
| 277 |
+
"model.layers.23.self_attn.q_proj.weight": "model-00001-of-00002.safetensors",
|
| 278 |
+
"model.layers.23.self_attn.v_proj.SCB": "model-00001-of-00002.safetensors",
|
| 279 |
+
"model.layers.23.self_attn.v_proj.weight": "model-00001-of-00002.safetensors",
|
| 280 |
+
"model.layers.24.input_layernorm.weight": "model-00002-of-00002.safetensors",
|
| 281 |
+
"model.layers.24.mlp.down_proj.SCB": "model-00002-of-00002.safetensors",
|
| 282 |
+
"model.layers.24.mlp.down_proj.weight": "model-00002-of-00002.safetensors",
|
| 283 |
+
"model.layers.24.mlp.gate_proj.SCB": "model-00002-of-00002.safetensors",
|
| 284 |
+
"model.layers.24.mlp.gate_proj.weight": "model-00002-of-00002.safetensors",
|
| 285 |
+
"model.layers.24.mlp.up_proj.SCB": "model-00002-of-00002.safetensors",
|
| 286 |
+
"model.layers.24.mlp.up_proj.weight": "model-00002-of-00002.safetensors",
|
| 287 |
+
"model.layers.24.post_attention_layernorm.weight": "model-00002-of-00002.safetensors",
|
| 288 |
+
"model.layers.24.self_attn.k_proj.SCB": "model-00002-of-00002.safetensors",
|
| 289 |
+
"model.layers.24.self_attn.k_proj.weight": "model-00002-of-00002.safetensors",
|
| 290 |
+
"model.layers.24.self_attn.o_proj.SCB": "model-00002-of-00002.safetensors",
|
| 291 |
+
"model.layers.24.self_attn.o_proj.weight": "model-00002-of-00002.safetensors",
|
| 292 |
+
"model.layers.24.self_attn.q_proj.SCB": "model-00002-of-00002.safetensors",
|
| 293 |
+
"model.layers.24.self_attn.q_proj.weight": "model-00002-of-00002.safetensors",
|
| 294 |
+
"model.layers.24.self_attn.v_proj.SCB": "model-00002-of-00002.safetensors",
|
| 295 |
+
"model.layers.24.self_attn.v_proj.weight": "model-00002-of-00002.safetensors",
|
| 296 |
+
"model.layers.25.input_layernorm.weight": "model-00002-of-00002.safetensors",
|
| 297 |
+
"model.layers.25.mlp.down_proj.SCB": "model-00002-of-00002.safetensors",
|
| 298 |
+
"model.layers.25.mlp.down_proj.weight": "model-00002-of-00002.safetensors",
|
| 299 |
+
"model.layers.25.mlp.gate_proj.SCB": "model-00002-of-00002.safetensors",
|
| 300 |
+
"model.layers.25.mlp.gate_proj.weight": "model-00002-of-00002.safetensors",
|
| 301 |
+
"model.layers.25.mlp.up_proj.SCB": "model-00002-of-00002.safetensors",
|
| 302 |
+
"model.layers.25.mlp.up_proj.weight": "model-00002-of-00002.safetensors",
|
| 303 |
+
"model.layers.25.post_attention_layernorm.weight": "model-00002-of-00002.safetensors",
|
| 304 |
+
"model.layers.25.self_attn.k_proj.SCB": "model-00002-of-00002.safetensors",
|
| 305 |
+
"model.layers.25.self_attn.k_proj.weight": "model-00002-of-00002.safetensors",
|
| 306 |
+
"model.layers.25.self_attn.o_proj.SCB": "model-00002-of-00002.safetensors",
|
| 307 |
+
"model.layers.25.self_attn.o_proj.weight": "model-00002-of-00002.safetensors",
|
| 308 |
+
"model.layers.25.self_attn.q_proj.SCB": "model-00002-of-00002.safetensors",
|
| 309 |
+
"model.layers.25.self_attn.q_proj.weight": "model-00002-of-00002.safetensors",
|
| 310 |
+
"model.layers.25.self_attn.v_proj.SCB": "model-00002-of-00002.safetensors",
|
| 311 |
+
"model.layers.25.self_attn.v_proj.weight": "model-00002-of-00002.safetensors",
|
| 312 |
+
"model.layers.26.input_layernorm.weight": "model-00002-of-00002.safetensors",
|
| 313 |
+
"model.layers.26.mlp.down_proj.SCB": "model-00002-of-00002.safetensors",
|
| 314 |
+
"model.layers.26.mlp.down_proj.weight": "model-00002-of-00002.safetensors",
|
| 315 |
+
"model.layers.26.mlp.gate_proj.SCB": "model-00002-of-00002.safetensors",
|
| 316 |
+
"model.layers.26.mlp.gate_proj.weight": "model-00002-of-00002.safetensors",
|
| 317 |
+
"model.layers.26.mlp.up_proj.SCB": "model-00002-of-00002.safetensors",
|
| 318 |
+
"model.layers.26.mlp.up_proj.weight": "model-00002-of-00002.safetensors",
|
| 319 |
+
"model.layers.26.post_attention_layernorm.weight": "model-00002-of-00002.safetensors",
|
| 320 |
+
"model.layers.26.self_attn.k_proj.SCB": "model-00002-of-00002.safetensors",
|
| 321 |
+
"model.layers.26.self_attn.k_proj.weight": "model-00002-of-00002.safetensors",
|
| 322 |
+
"model.layers.26.self_attn.o_proj.SCB": "model-00002-of-00002.safetensors",
|
| 323 |
+
"model.layers.26.self_attn.o_proj.weight": "model-00002-of-00002.safetensors",
|
| 324 |
+
"model.layers.26.self_attn.q_proj.SCB": "model-00002-of-00002.safetensors",
|
| 325 |
+
"model.layers.26.self_attn.q_proj.weight": "model-00002-of-00002.safetensors",
|
| 326 |
+
"model.layers.26.self_attn.v_proj.SCB": "model-00002-of-00002.safetensors",
|
| 327 |
+
"model.layers.26.self_attn.v_proj.weight": "model-00002-of-00002.safetensors",
|
| 328 |
+
"model.layers.27.input_layernorm.weight": "model-00002-of-00002.safetensors",
|
| 329 |
+
"model.layers.27.mlp.down_proj.SCB": "model-00002-of-00002.safetensors",
|
| 330 |
+
"model.layers.27.mlp.down_proj.weight": "model-00002-of-00002.safetensors",
|
| 331 |
+
"model.layers.27.mlp.gate_proj.SCB": "model-00002-of-00002.safetensors",
|
| 332 |
+
"model.layers.27.mlp.gate_proj.weight": "model-00002-of-00002.safetensors",
|
| 333 |
+
"model.layers.27.mlp.up_proj.SCB": "model-00002-of-00002.safetensors",
|
| 334 |
+
"model.layers.27.mlp.up_proj.weight": "model-00002-of-00002.safetensors",
|
| 335 |
+
"model.layers.27.post_attention_layernorm.weight": "model-00002-of-00002.safetensors",
|
| 336 |
+
"model.layers.27.self_attn.k_proj.SCB": "model-00002-of-00002.safetensors",
|
| 337 |
+
"model.layers.27.self_attn.k_proj.weight": "model-00002-of-00002.safetensors",
|
| 338 |
+
"model.layers.27.self_attn.o_proj.SCB": "model-00002-of-00002.safetensors",
|
| 339 |
+
"model.layers.27.self_attn.o_proj.weight": "model-00002-of-00002.safetensors",
|
| 340 |
+
"model.layers.27.self_attn.q_proj.SCB": "model-00002-of-00002.safetensors",
|
| 341 |
+
"model.layers.27.self_attn.q_proj.weight": "model-00002-of-00002.safetensors",
|
| 342 |
+
"model.layers.27.self_attn.v_proj.SCB": "model-00002-of-00002.safetensors",
|
| 343 |
+
"model.layers.27.self_attn.v_proj.weight": "model-00002-of-00002.safetensors",
|
| 344 |
+
"model.layers.28.input_layernorm.weight": "model-00002-of-00002.safetensors",
|
| 345 |
+
"model.layers.28.mlp.down_proj.SCB": "model-00002-of-00002.safetensors",
|
| 346 |
+
"model.layers.28.mlp.down_proj.weight": "model-00002-of-00002.safetensors",
|
| 347 |
+
"model.layers.28.mlp.gate_proj.SCB": "model-00002-of-00002.safetensors",
|
| 348 |
+
"model.layers.28.mlp.gate_proj.weight": "model-00002-of-00002.safetensors",
|
| 349 |
+
"model.layers.28.mlp.up_proj.SCB": "model-00002-of-00002.safetensors",
|
| 350 |
+
"model.layers.28.mlp.up_proj.weight": "model-00002-of-00002.safetensors",
|
| 351 |
+
"model.layers.28.post_attention_layernorm.weight": "model-00002-of-00002.safetensors",
|
| 352 |
+
"model.layers.28.self_attn.k_proj.SCB": "model-00002-of-00002.safetensors",
|
| 353 |
+
"model.layers.28.self_attn.k_proj.weight": "model-00002-of-00002.safetensors",
|
| 354 |
+
"model.layers.28.self_attn.o_proj.SCB": "model-00002-of-00002.safetensors",
|
| 355 |
+
"model.layers.28.self_attn.o_proj.weight": "model-00002-of-00002.safetensors",
|
| 356 |
+
"model.layers.28.self_attn.q_proj.SCB": "model-00002-of-00002.safetensors",
|
| 357 |
+
"model.layers.28.self_attn.q_proj.weight": "model-00002-of-00002.safetensors",
|
| 358 |
+
"model.layers.28.self_attn.v_proj.SCB": "model-00002-of-00002.safetensors",
|
| 359 |
+
"model.layers.28.self_attn.v_proj.weight": "model-00002-of-00002.safetensors",
|
| 360 |
+
"model.layers.29.input_layernorm.weight": "model-00002-of-00002.safetensors",
|
| 361 |
+
"model.layers.29.mlp.down_proj.SCB": "model-00002-of-00002.safetensors",
|
| 362 |
+
"model.layers.29.mlp.down_proj.weight": "model-00002-of-00002.safetensors",
|
| 363 |
+
"model.layers.29.mlp.gate_proj.SCB": "model-00002-of-00002.safetensors",
|
| 364 |
+
"model.layers.29.mlp.gate_proj.weight": "model-00002-of-00002.safetensors",
|
| 365 |
+
"model.layers.29.mlp.up_proj.SCB": "model-00002-of-00002.safetensors",
|
| 366 |
+
"model.layers.29.mlp.up_proj.weight": "model-00002-of-00002.safetensors",
|
| 367 |
+
"model.layers.29.post_attention_layernorm.weight": "model-00002-of-00002.safetensors",
|
| 368 |
+
"model.layers.29.self_attn.k_proj.SCB": "model-00002-of-00002.safetensors",
|
| 369 |
+
"model.layers.29.self_attn.k_proj.weight": "model-00002-of-00002.safetensors",
|
| 370 |
+
"model.layers.29.self_attn.o_proj.SCB": "model-00002-of-00002.safetensors",
|
| 371 |
+
"model.layers.29.self_attn.o_proj.weight": "model-00002-of-00002.safetensors",
|
| 372 |
+
"model.layers.29.self_attn.q_proj.SCB": "model-00002-of-00002.safetensors",
|
| 373 |
+
"model.layers.29.self_attn.q_proj.weight": "model-00002-of-00002.safetensors",
|
| 374 |
+
"model.layers.29.self_attn.v_proj.SCB": "model-00002-of-00002.safetensors",
|
| 375 |
+
"model.layers.29.self_attn.v_proj.weight": "model-00002-of-00002.safetensors",
|
| 376 |
+
"model.layers.3.input_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 377 |
+
"model.layers.3.mlp.down_proj.SCB": "model-00001-of-00002.safetensors",
|
| 378 |
+
"model.layers.3.mlp.down_proj.weight": "model-00001-of-00002.safetensors",
|
| 379 |
+
"model.layers.3.mlp.gate_proj.SCB": "model-00001-of-00002.safetensors",
|
| 380 |
+
"model.layers.3.mlp.gate_proj.weight": "model-00001-of-00002.safetensors",
|
| 381 |
+
"model.layers.3.mlp.up_proj.SCB": "model-00001-of-00002.safetensors",
|
| 382 |
+
"model.layers.3.mlp.up_proj.weight": "model-00001-of-00002.safetensors",
|
| 383 |
+
"model.layers.3.post_attention_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 384 |
+
"model.layers.3.self_attn.k_proj.SCB": "model-00001-of-00002.safetensors",
|
| 385 |
+
"model.layers.3.self_attn.k_proj.weight": "model-00001-of-00002.safetensors",
|
| 386 |
+
"model.layers.3.self_attn.o_proj.SCB": "model-00001-of-00002.safetensors",
|
| 387 |
+
"model.layers.3.self_attn.o_proj.weight": "model-00001-of-00002.safetensors",
|
| 388 |
+
"model.layers.3.self_attn.q_proj.SCB": "model-00001-of-00002.safetensors",
|
| 389 |
+
"model.layers.3.self_attn.q_proj.weight": "model-00001-of-00002.safetensors",
|
| 390 |
+
"model.layers.3.self_attn.v_proj.SCB": "model-00001-of-00002.safetensors",
|
| 391 |
+
"model.layers.3.self_attn.v_proj.weight": "model-00001-of-00002.safetensors",
|
| 392 |
+
"model.layers.30.input_layernorm.weight": "model-00002-of-00002.safetensors",
|
| 393 |
+
"model.layers.30.mlp.down_proj.SCB": "model-00002-of-00002.safetensors",
|
| 394 |
+
"model.layers.30.mlp.down_proj.weight": "model-00002-of-00002.safetensors",
|
| 395 |
+
"model.layers.30.mlp.gate_proj.SCB": "model-00002-of-00002.safetensors",
|
| 396 |
+
"model.layers.30.mlp.gate_proj.weight": "model-00002-of-00002.safetensors",
|
| 397 |
+
"model.layers.30.mlp.up_proj.SCB": "model-00002-of-00002.safetensors",
|
| 398 |
+
"model.layers.30.mlp.up_proj.weight": "model-00002-of-00002.safetensors",
|
| 399 |
+
"model.layers.30.post_attention_layernorm.weight": "model-00002-of-00002.safetensors",
|
| 400 |
+
"model.layers.30.self_attn.k_proj.SCB": "model-00002-of-00002.safetensors",
|
| 401 |
+
"model.layers.30.self_attn.k_proj.weight": "model-00002-of-00002.safetensors",
|
| 402 |
+
"model.layers.30.self_attn.o_proj.SCB": "model-00002-of-00002.safetensors",
|
| 403 |
+
"model.layers.30.self_attn.o_proj.weight": "model-00002-of-00002.safetensors",
|
| 404 |
+
"model.layers.30.self_attn.q_proj.SCB": "model-00002-of-00002.safetensors",
|
| 405 |
+
"model.layers.30.self_attn.q_proj.weight": "model-00002-of-00002.safetensors",
|
| 406 |
+
"model.layers.30.self_attn.v_proj.SCB": "model-00002-of-00002.safetensors",
|
| 407 |
+
"model.layers.30.self_attn.v_proj.weight": "model-00002-of-00002.safetensors",
|
| 408 |
+
"model.layers.31.input_layernorm.weight": "model-00002-of-00002.safetensors",
|
| 409 |
+
"model.layers.31.mlp.down_proj.SCB": "model-00002-of-00002.safetensors",
|
| 410 |
+
"model.layers.31.mlp.down_proj.weight": "model-00002-of-00002.safetensors",
|
| 411 |
+
"model.layers.31.mlp.gate_proj.SCB": "model-00002-of-00002.safetensors",
|
| 412 |
+
"model.layers.31.mlp.gate_proj.weight": "model-00002-of-00002.safetensors",
|
| 413 |
+
"model.layers.31.mlp.up_proj.SCB": "model-00002-of-00002.safetensors",
|
| 414 |
+
"model.layers.31.mlp.up_proj.weight": "model-00002-of-00002.safetensors",
|
| 415 |
+
"model.layers.31.post_attention_layernorm.weight": "model-00002-of-00002.safetensors",
|
| 416 |
+
"model.layers.31.self_attn.k_proj.SCB": "model-00002-of-00002.safetensors",
|
| 417 |
+
"model.layers.31.self_attn.k_proj.weight": "model-00002-of-00002.safetensors",
|
| 418 |
+
"model.layers.31.self_attn.o_proj.SCB": "model-00002-of-00002.safetensors",
|
| 419 |
+
"model.layers.31.self_attn.o_proj.weight": "model-00002-of-00002.safetensors",
|
| 420 |
+
"model.layers.31.self_attn.q_proj.SCB": "model-00002-of-00002.safetensors",
|
| 421 |
+
"model.layers.31.self_attn.q_proj.weight": "model-00002-of-00002.safetensors",
|
| 422 |
+
"model.layers.31.self_attn.v_proj.SCB": "model-00002-of-00002.safetensors",
|
| 423 |
+
"model.layers.31.self_attn.v_proj.weight": "model-00002-of-00002.safetensors",
|
| 424 |
+
"model.layers.4.input_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 425 |
+
"model.layers.4.mlp.down_proj.SCB": "model-00001-of-00002.safetensors",
|
| 426 |
+
"model.layers.4.mlp.down_proj.weight": "model-00001-of-00002.safetensors",
|
| 427 |
+
"model.layers.4.mlp.gate_proj.SCB": "model-00001-of-00002.safetensors",
|
| 428 |
+
"model.layers.4.mlp.gate_proj.weight": "model-00001-of-00002.safetensors",
|
| 429 |
+
"model.layers.4.mlp.up_proj.SCB": "model-00001-of-00002.safetensors",
|
| 430 |
+
"model.layers.4.mlp.up_proj.weight": "model-00001-of-00002.safetensors",
|
| 431 |
+
"model.layers.4.post_attention_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 432 |
+
"model.layers.4.self_attn.k_proj.SCB": "model-00001-of-00002.safetensors",
|
| 433 |
+
"model.layers.4.self_attn.k_proj.weight": "model-00001-of-00002.safetensors",
|
| 434 |
+
"model.layers.4.self_attn.o_proj.SCB": "model-00001-of-00002.safetensors",
|
| 435 |
+
"model.layers.4.self_attn.o_proj.weight": "model-00001-of-00002.safetensors",
|
| 436 |
+
"model.layers.4.self_attn.q_proj.SCB": "model-00001-of-00002.safetensors",
|
| 437 |
+
"model.layers.4.self_attn.q_proj.weight": "model-00001-of-00002.safetensors",
|
| 438 |
+
"model.layers.4.self_attn.v_proj.SCB": "model-00001-of-00002.safetensors",
|
| 439 |
+
"model.layers.4.self_attn.v_proj.weight": "model-00001-of-00002.safetensors",
|
| 440 |
+
"model.layers.5.input_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 441 |
+
"model.layers.5.mlp.down_proj.SCB": "model-00001-of-00002.safetensors",
|
| 442 |
+
"model.layers.5.mlp.down_proj.weight": "model-00001-of-00002.safetensors",
|
| 443 |
+
"model.layers.5.mlp.gate_proj.SCB": "model-00001-of-00002.safetensors",
|
| 444 |
+
"model.layers.5.mlp.gate_proj.weight": "model-00001-of-00002.safetensors",
|
| 445 |
+
"model.layers.5.mlp.up_proj.SCB": "model-00001-of-00002.safetensors",
|
| 446 |
+
"model.layers.5.mlp.up_proj.weight": "model-00001-of-00002.safetensors",
|
| 447 |
+
"model.layers.5.post_attention_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 448 |
+
"model.layers.5.self_attn.k_proj.SCB": "model-00001-of-00002.safetensors",
|
| 449 |
+
"model.layers.5.self_attn.k_proj.weight": "model-00001-of-00002.safetensors",
|
| 450 |
+
"model.layers.5.self_attn.o_proj.SCB": "model-00001-of-00002.safetensors",
|
| 451 |
+
"model.layers.5.self_attn.o_proj.weight": "model-00001-of-00002.safetensors",
|
| 452 |
+
"model.layers.5.self_attn.q_proj.SCB": "model-00001-of-00002.safetensors",
|
| 453 |
+
"model.layers.5.self_attn.q_proj.weight": "model-00001-of-00002.safetensors",
|
| 454 |
+
"model.layers.5.self_attn.v_proj.SCB": "model-00001-of-00002.safetensors",
|
| 455 |
+
"model.layers.5.self_attn.v_proj.weight": "model-00001-of-00002.safetensors",
|
| 456 |
+
"model.layers.6.input_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 457 |
+
"model.layers.6.mlp.down_proj.SCB": "model-00001-of-00002.safetensors",
|
| 458 |
+
"model.layers.6.mlp.down_proj.weight": "model-00001-of-00002.safetensors",
|
| 459 |
+
"model.layers.6.mlp.gate_proj.SCB": "model-00001-of-00002.safetensors",
|
| 460 |
+
"model.layers.6.mlp.gate_proj.weight": "model-00001-of-00002.safetensors",
|
| 461 |
+
"model.layers.6.mlp.up_proj.SCB": "model-00001-of-00002.safetensors",
|
| 462 |
+
"model.layers.6.mlp.up_proj.weight": "model-00001-of-00002.safetensors",
|
| 463 |
+
"model.layers.6.post_attention_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 464 |
+
"model.layers.6.self_attn.k_proj.SCB": "model-00001-of-00002.safetensors",
|
| 465 |
+
"model.layers.6.self_attn.k_proj.weight": "model-00001-of-00002.safetensors",
|
| 466 |
+
"model.layers.6.self_attn.o_proj.SCB": "model-00001-of-00002.safetensors",
|
| 467 |
+
"model.layers.6.self_attn.o_proj.weight": "model-00001-of-00002.safetensors",
|
| 468 |
+
"model.layers.6.self_attn.q_proj.SCB": "model-00001-of-00002.safetensors",
|
| 469 |
+
"model.layers.6.self_attn.q_proj.weight": "model-00001-of-00002.safetensors",
|
| 470 |
+
"model.layers.6.self_attn.v_proj.SCB": "model-00001-of-00002.safetensors",
|
| 471 |
+
"model.layers.6.self_attn.v_proj.weight": "model-00001-of-00002.safetensors",
|
| 472 |
+
"model.layers.7.input_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 473 |
+
"model.layers.7.mlp.down_proj.SCB": "model-00001-of-00002.safetensors",
|
| 474 |
+
"model.layers.7.mlp.down_proj.weight": "model-00001-of-00002.safetensors",
|
| 475 |
+
"model.layers.7.mlp.gate_proj.SCB": "model-00001-of-00002.safetensors",
|
| 476 |
+
"model.layers.7.mlp.gate_proj.weight": "model-00001-of-00002.safetensors",
|
| 477 |
+
"model.layers.7.mlp.up_proj.SCB": "model-00001-of-00002.safetensors",
|
| 478 |
+
"model.layers.7.mlp.up_proj.weight": "model-00001-of-00002.safetensors",
|
| 479 |
+
"model.layers.7.post_attention_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 480 |
+
"model.layers.7.self_attn.k_proj.SCB": "model-00001-of-00002.safetensors",
|
| 481 |
+
"model.layers.7.self_attn.k_proj.weight": "model-00001-of-00002.safetensors",
|
| 482 |
+
"model.layers.7.self_attn.o_proj.SCB": "model-00001-of-00002.safetensors",
|
| 483 |
+
"model.layers.7.self_attn.o_proj.weight": "model-00001-of-00002.safetensors",
|
| 484 |
+
"model.layers.7.self_attn.q_proj.SCB": "model-00001-of-00002.safetensors",
|
| 485 |
+
"model.layers.7.self_attn.q_proj.weight": "model-00001-of-00002.safetensors",
|
| 486 |
+
"model.layers.7.self_attn.v_proj.SCB": "model-00001-of-00002.safetensors",
|
| 487 |
+
"model.layers.7.self_attn.v_proj.weight": "model-00001-of-00002.safetensors",
|
| 488 |
+
"model.layers.8.input_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 489 |
+
"model.layers.8.mlp.down_proj.SCB": "model-00001-of-00002.safetensors",
|
| 490 |
+
"model.layers.8.mlp.down_proj.weight": "model-00001-of-00002.safetensors",
|
| 491 |
+
"model.layers.8.mlp.gate_proj.SCB": "model-00001-of-00002.safetensors",
|
| 492 |
+
"model.layers.8.mlp.gate_proj.weight": "model-00001-of-00002.safetensors",
|
| 493 |
+
"model.layers.8.mlp.up_proj.SCB": "model-00001-of-00002.safetensors",
|
| 494 |
+
"model.layers.8.mlp.up_proj.weight": "model-00001-of-00002.safetensors",
|
| 495 |
+
"model.layers.8.post_attention_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 496 |
+
"model.layers.8.self_attn.k_proj.SCB": "model-00001-of-00002.safetensors",
|
| 497 |
+
"model.layers.8.self_attn.k_proj.weight": "model-00001-of-00002.safetensors",
|
| 498 |
+
"model.layers.8.self_attn.o_proj.SCB": "model-00001-of-00002.safetensors",
|
| 499 |
+
"model.layers.8.self_attn.o_proj.weight": "model-00001-of-00002.safetensors",
|
| 500 |
+
"model.layers.8.self_attn.q_proj.SCB": "model-00001-of-00002.safetensors",
|
| 501 |
+
"model.layers.8.self_attn.q_proj.weight": "model-00001-of-00002.safetensors",
|
| 502 |
+
"model.layers.8.self_attn.v_proj.SCB": "model-00001-of-00002.safetensors",
|
| 503 |
+
"model.layers.8.self_attn.v_proj.weight": "model-00001-of-00002.safetensors",
|
| 504 |
+
"model.layers.9.input_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 505 |
+
"model.layers.9.mlp.down_proj.SCB": "model-00001-of-00002.safetensors",
|
| 506 |
+
"model.layers.9.mlp.down_proj.weight": "model-00001-of-00002.safetensors",
|
| 507 |
+
"model.layers.9.mlp.gate_proj.SCB": "model-00001-of-00002.safetensors",
|
| 508 |
+
"model.layers.9.mlp.gate_proj.weight": "model-00001-of-00002.safetensors",
|
| 509 |
+
"model.layers.9.mlp.up_proj.SCB": "model-00001-of-00002.safetensors",
|
| 510 |
+
"model.layers.9.mlp.up_proj.weight": "model-00001-of-00002.safetensors",
|
| 511 |
+
"model.layers.9.post_attention_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 512 |
+
"model.layers.9.self_attn.k_proj.SCB": "model-00001-of-00002.safetensors",
|
| 513 |
+
"model.layers.9.self_attn.k_proj.weight": "model-00001-of-00002.safetensors",
|
| 514 |
+
"model.layers.9.self_attn.o_proj.SCB": "model-00001-of-00002.safetensors",
|
| 515 |
+
"model.layers.9.self_attn.o_proj.weight": "model-00001-of-00002.safetensors",
|
| 516 |
+
"model.layers.9.self_attn.q_proj.SCB": "model-00001-of-00002.safetensors",
|
| 517 |
+
"model.layers.9.self_attn.q_proj.weight": "model-00001-of-00002.safetensors",
|
| 518 |
+
"model.layers.9.self_attn.v_proj.SCB": "model-00001-of-00002.safetensors",
|
| 519 |
+
"model.layers.9.self_attn.v_proj.weight": "model-00001-of-00002.safetensors",
|
| 520 |
+
"model.norm.weight": "model-00002-of-00002.safetensors"
|
| 521 |
+
}
|
| 522 |
+
}
|
modeling_flash_llama.py
ADDED
|
@@ -0,0 +1,1010 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# coding=utf-8
|
| 2 |
+
# From https://huggingface.co/togethercomputer/LLaMA-2-7B-32K/blob/main/modeling_flash_llama.py
|
| 3 |
+
# With fix from Alex Birch: https://huggingface.co/togethercomputer/LLaMA-2-7B-32K/discussions/17
|
| 4 |
+
# Copyright 2022 EleutherAI and the HuggingFace Inc. team. All rights reserved.
|
| 5 |
+
#
|
| 6 |
+
# This code is based on EleutherAI's GPT-NeoX library and the GPT-NeoX
|
| 7 |
+
# and OPT implementations in this library. It has been modified from its
|
| 8 |
+
# original forms to accommodate minor architectural differences compared
|
| 9 |
+
# to GPT-NeoX and OPT used by the Meta AI team that trained the model.
|
| 10 |
+
#
|
| 11 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 12 |
+
# you may not use this file except in compliance with the License.
|
| 13 |
+
# You may obtain a copy of the License at
|
| 14 |
+
#
|
| 15 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 16 |
+
#
|
| 17 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 18 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 19 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 20 |
+
# See the License for the specific language governing permissions and
|
| 21 |
+
# limitations under the License.
|
| 22 |
+
""" PyTorch LLaMA model."""
|
| 23 |
+
from typing import List, Optional, Tuple, Union
|
| 24 |
+
|
| 25 |
+
import torch
|
| 26 |
+
import torch.nn.functional as F
|
| 27 |
+
import torch.utils.checkpoint
|
| 28 |
+
from torch import nn
|
| 29 |
+
from torch.nn import BCEWithLogitsLoss, CrossEntropyLoss, MSELoss
|
| 30 |
+
|
| 31 |
+
from transformers.activations import ACT2FN
|
| 32 |
+
from transformers.modeling_outputs import BaseModelOutputWithPast, CausalLMOutputWithPast, SequenceClassifierOutputWithPast
|
| 33 |
+
from transformers.modeling_utils import PreTrainedModel
|
| 34 |
+
from transformers.utils import add_start_docstrings, add_start_docstrings_to_model_forward, logging, replace_return_docstrings
|
| 35 |
+
from transformers.models.llama.configuration_llama import LlamaConfig
|
| 36 |
+
|
| 37 |
+
|
| 38 |
+
try:
|
| 39 |
+
from flash_attn.flash_attn_interface import (
|
| 40 |
+
flash_attn_kvpacked_func,
|
| 41 |
+
flash_attn_varlen_kvpacked_func,
|
| 42 |
+
)
|
| 43 |
+
from flash_attn.bert_padding import unpad_input, pad_input
|
| 44 |
+
flash_attn_v2_installed = True
|
| 45 |
+
print('>>>> Flash Attention installed')
|
| 46 |
+
except ImportError:
|
| 47 |
+
flash_attn_v2_installed = False
|
| 48 |
+
raise ImportError('Please install Flash Attention: `pip install flash-attn --no-build-isolation`')
|
| 49 |
+
|
| 50 |
+
try:
|
| 51 |
+
from flash_attn.layers.rotary import apply_rotary_emb_func
|
| 52 |
+
flash_rope_installed = True
|
| 53 |
+
print('>>>> Flash RoPE installed')
|
| 54 |
+
except ImportError:
|
| 55 |
+
flash_rope_installed = False
|
| 56 |
+
raise ImportError('Please install RoPE kernels: `pip install git+https://github.com/HazyResearch/flash-attention.git#subdirectory=csrc/rotary`')
|
| 57 |
+
|
| 58 |
+
|
| 59 |
+
logger = logging.get_logger(__name__)
|
| 60 |
+
|
| 61 |
+
_CONFIG_FOR_DOC = "LlamaConfig"
|
| 62 |
+
|
| 63 |
+
|
| 64 |
+
# @torch.jit.script
|
| 65 |
+
def rmsnorm_func(hidden_states, weight, variance_epsilon):
|
| 66 |
+
input_dtype = hidden_states.dtype
|
| 67 |
+
hidden_states = hidden_states.to(torch.float32)
|
| 68 |
+
variance = hidden_states.pow(2).mean(-1, keepdim=True)
|
| 69 |
+
hidden_states = hidden_states * torch.rsqrt(variance + variance_epsilon)
|
| 70 |
+
return (weight * hidden_states).to(input_dtype)
|
| 71 |
+
|
| 72 |
+
|
| 73 |
+
class LlamaRMSNorm(nn.Module):
|
| 74 |
+
def __init__(self, hidden_size, eps=1e-6):
|
| 75 |
+
"""
|
| 76 |
+
LlamaRMSNorm is equivalent to T5LayerNorm
|
| 77 |
+
"""
|
| 78 |
+
super().__init__()
|
| 79 |
+
self.weight = nn.Parameter(torch.ones(hidden_size))
|
| 80 |
+
self.register_buffer(
|
| 81 |
+
"variance_epsilon",
|
| 82 |
+
torch.tensor(eps),
|
| 83 |
+
persistent=False,
|
| 84 |
+
)
|
| 85 |
+
|
| 86 |
+
def forward(self, hidden_states):
|
| 87 |
+
return rmsnorm_func(hidden_states, self.weight, self.variance_epsilon)
|
| 88 |
+
|
| 89 |
+
|
| 90 |
+
class FlashRotaryEmbedding(torch.nn.Module):
|
| 91 |
+
"""
|
| 92 |
+
The rotary position embeddings from RoFormer_ (Su et. al).
|
| 93 |
+
A crucial insight from the method is that the query and keys are
|
| 94 |
+
transformed by rotation matrices which depend on the relative positions.
|
| 95 |
+
|
| 96 |
+
Other implementations are available in the Rotary Transformer repo_ and in
|
| 97 |
+
GPT-NeoX_, GPT-NeoX was an inspiration
|
| 98 |
+
|
| 99 |
+
.. _RoFormer: https://arxiv.org/abs/2104.09864
|
| 100 |
+
.. _repo: https://github.com/ZhuiyiTechnology/roformer
|
| 101 |
+
.. _GPT-NeoX: https://github.com/EleutherAI/gpt-neox
|
| 102 |
+
|
| 103 |
+
If scale_base is not None, this implements XPos (Sun et al., https://arxiv.org/abs/2212.10554).
|
| 104 |
+
A recommended value for scale_base is 512: https://github.com/HazyResearch/flash-attention/issues/96
|
| 105 |
+
Reference: https://github.com/sunyt32/torchscale/blob/main/torchscale/component/xpos_relative_position.py
|
| 106 |
+
"""
|
| 107 |
+
|
| 108 |
+
def __init__(self, dim: int, base=10000.0, interleaved=False, scale_base=None,
|
| 109 |
+
scaling_factor=1.0, pos_idx_in_fp32=True, device=None):
|
| 110 |
+
"""
|
| 111 |
+
interleaved: if True, rotate pairs of even and odd dimensions (GPT-J style) instead
|
| 112 |
+
of 1st half and 2nd half (GPT-NeoX style).
|
| 113 |
+
pos_idx_in_fp32: if True, the position indices [0.0, ..., seqlen - 1] are in fp32,
|
| 114 |
+
otherwise they might be in lower precision.
|
| 115 |
+
This option was added because previously (before 2023-07-02), when we construct
|
| 116 |
+
the position indices, we use the dtype of self.inv_freq. In most cases this would
|
| 117 |
+
be fp32, but if the model is trained in pure bf16 (not mixed precision), then
|
| 118 |
+
self.inv_freq would be bf16, and the position indices are also in bf16.
|
| 119 |
+
Because of the limited precision of bf16 (e.g. 1995.0 is rounded to 2000.0), the
|
| 120 |
+
embeddings for some positions will coincide.
|
| 121 |
+
To maintain compatibility with models previously trained in pure bf16,
|
| 122 |
+
we add this option.
|
| 123 |
+
scaling_factor: RotaryEmbedding extended with linear scaling.
|
| 124 |
+
"""
|
| 125 |
+
super().__init__()
|
| 126 |
+
self.dim = dim
|
| 127 |
+
self.base = float(base)
|
| 128 |
+
self.pos_idx_in_fp32 = pos_idx_in_fp32
|
| 129 |
+
# Generate and save the inverse frequency buffer (non trainable)
|
| 130 |
+
inv_freq = self._compute_inv_freq(device)
|
| 131 |
+
self.register_buffer("inv_freq", inv_freq, persistent=False)
|
| 132 |
+
self.interleaved = interleaved
|
| 133 |
+
self.scale_base = scale_base
|
| 134 |
+
self.scaling_factor = scaling_factor
|
| 135 |
+
scale = ((torch.arange(0, dim, 2, device=device, dtype=torch.float32) + 0.4 * dim)
|
| 136 |
+
/ (1.4 * dim) if scale_base is not None else None)
|
| 137 |
+
self.register_buffer("scale", scale)
|
| 138 |
+
|
| 139 |
+
self._seq_len_cached = 0
|
| 140 |
+
self._cos_cached = None
|
| 141 |
+
self._sin_cached = None
|
| 142 |
+
self._cos_k_cached = None
|
| 143 |
+
self._sin_k_cached = None
|
| 144 |
+
|
| 145 |
+
def _compute_inv_freq(self, device=None):
|
| 146 |
+
return 1 / (self.base ** (torch.arange(0, self.dim, 2, device=device,
|
| 147 |
+
dtype=torch.float32) / self.dim))
|
| 148 |
+
|
| 149 |
+
|
| 150 |
+
def _update_cos_sin_cache(self, seqlen, device=None, dtype=None):
|
| 151 |
+
# Reset the tables if the sequence length has changed,
|
| 152 |
+
# if we're on a new device (possibly due to tracing for instance),
|
| 153 |
+
# or if we're switching from inference mode to training
|
| 154 |
+
if (seqlen > self._seq_len_cached or self._cos_cached.device != device
|
| 155 |
+
or self._cos_cached.dtype != dtype
|
| 156 |
+
or (self.training and self._cos_cached.is_inference())):
|
| 157 |
+
self._seq_len_cached = seqlen
|
| 158 |
+
# We want fp32 here, not self.inv_freq.dtype, since the model could be loaded in bf16
|
| 159 |
+
# And the output of arange can be quite large, so bf16 would lose a lot of precision.
|
| 160 |
+
# However, for compatibility reason, we add an option to use the dtype of self.inv_freq.
|
| 161 |
+
if self.pos_idx_in_fp32:
|
| 162 |
+
t = torch.arange(seqlen, device=device, dtype=torch.float32)
|
| 163 |
+
t /= self.scaling_factor
|
| 164 |
+
# We want fp32 here as well since inv_freq will be multiplied with t, and the output
|
| 165 |
+
# will be large. Having it in bf16 will lose a lot of precision and cause the
|
| 166 |
+
# cos & sin output to change significantly.
|
| 167 |
+
# We want to recompute self.inv_freq if it was not loaded in fp32
|
| 168 |
+
if self.inv_freq.dtype != torch.float32:
|
| 169 |
+
inv_freq = self.inv_freq.to(torch.float32)
|
| 170 |
+
else:
|
| 171 |
+
inv_freq = self.inv_freq
|
| 172 |
+
else:
|
| 173 |
+
t = torch.arange(seqlen, device=device, dtype=self.inv_freq.dtype)
|
| 174 |
+
t /= self.scaling_factor
|
| 175 |
+
inv_freq = self.inv_freq
|
| 176 |
+
# Don't do einsum, it converts fp32 to fp16 under AMP
|
| 177 |
+
# freqs = torch.einsum("i,j->ij", t, self.inv_freq)
|
| 178 |
+
freqs = torch.outer(t, inv_freq)
|
| 179 |
+
if self.scale is None:
|
| 180 |
+
self._cos_cached = torch.cos(freqs).to(dtype)
|
| 181 |
+
self._sin_cached = torch.sin(freqs).to(dtype)
|
| 182 |
+
else:
|
| 183 |
+
power = ((torch.arange(seqlen, dtype=self.scale.dtype, device=self.scale.device)
|
| 184 |
+
- seqlen // 2) / self.scale_base)
|
| 185 |
+
scale = self.scale.to(device=power.device) ** power.unsqueeze(-1)
|
| 186 |
+
# We want the multiplication by scale to happen in fp32
|
| 187 |
+
self._cos_cached = (torch.cos(freqs) * scale).to(dtype)
|
| 188 |
+
self._sin_cached = (torch.sin(freqs) * scale).to(dtype)
|
| 189 |
+
self._cos_k_cached = (torch.cos(freqs) / scale).to(dtype)
|
| 190 |
+
self._sin_k_cached = (torch.sin(freqs) / scale).to(dtype)
|
| 191 |
+
|
| 192 |
+
def forward(self, q: torch.Tensor, k: torch.Tensor, seqlen_offset: int = 0) -> Tuple[torch.Tensor, torch.Tensor]:
|
| 193 |
+
"""
|
| 194 |
+
q: (batch, seqlen, nheads, headdim)
|
| 195 |
+
k: (batch, seqlen, nheads, headdim)
|
| 196 |
+
seqlen_offset: can be used in generation where the qkv being passed in is only the last
|
| 197 |
+
token in the batch.
|
| 198 |
+
"""
|
| 199 |
+
self._update_cos_sin_cache(q.shape[1] + seqlen_offset, device=q.device, dtype=q.dtype)
|
| 200 |
+
if self.scale is None:
|
| 201 |
+
return apply_rotary_emb_func(
|
| 202 |
+
q, self._cos_cached[seqlen_offset:], self._sin_cached[seqlen_offset:],
|
| 203 |
+
self.interleaved, True # inplace=True
|
| 204 |
+
), apply_rotary_emb_func(
|
| 205 |
+
k, self._cos_cached[seqlen_offset:], self._sin_cached[seqlen_offset:],
|
| 206 |
+
self.interleaved, True # inplace=True
|
| 207 |
+
)
|
| 208 |
+
else:
|
| 209 |
+
assert False
|
| 210 |
+
|
| 211 |
+
class LlamaMLP(nn.Module):
|
| 212 |
+
def __init__(self, config):
|
| 213 |
+
super().__init__()
|
| 214 |
+
self.config = config
|
| 215 |
+
self.hidden_size = config.hidden_size
|
| 216 |
+
self.intermediate_size = config.intermediate_size
|
| 217 |
+
self.gate_proj = nn.Linear(self.hidden_size, self.intermediate_size, bias=False)
|
| 218 |
+
self.up_proj = nn.Linear(self.hidden_size, self.intermediate_size, bias=False)
|
| 219 |
+
self.down_proj = nn.Linear(self.intermediate_size, self.hidden_size, bias=False)
|
| 220 |
+
self.act_fn = ACT2FN[config.hidden_act]
|
| 221 |
+
|
| 222 |
+
def forward(self, x):
|
| 223 |
+
if self.config.pretraining_tp > 1:
|
| 224 |
+
slice = self.intermediate_size // self.config.pretraining_tp
|
| 225 |
+
gate_proj_slices = self.gate_proj.weight.split(slice, dim=0)
|
| 226 |
+
up_proj_slices = self.up_proj.weight.split(slice, dim=0)
|
| 227 |
+
down_proj_slices = self.down_proj.weight.split(slice, dim=1)
|
| 228 |
+
|
| 229 |
+
gate_proj = torch.cat(
|
| 230 |
+
[F.linear(x, gate_proj_slices[i]) for i in range(self.config.pretraining_tp)], dim=-1
|
| 231 |
+
)
|
| 232 |
+
up_proj = torch.cat([F.linear(x, up_proj_slices[i]) for i in range(self.config.pretraining_tp)], dim=-1)
|
| 233 |
+
|
| 234 |
+
intermediate_states = (self.act_fn(gate_proj) * up_proj).split(slice, dim=2)
|
| 235 |
+
down_proj = [
|
| 236 |
+
F.linear(intermediate_states[i], down_proj_slices[i]) for i in range(self.config.pretraining_tp)
|
| 237 |
+
]
|
| 238 |
+
down_proj = sum(down_proj)
|
| 239 |
+
else:
|
| 240 |
+
down_proj = self.down_proj(self.act_fn(self.gate_proj(x)) * self.up_proj(x))
|
| 241 |
+
|
| 242 |
+
return down_proj
|
| 243 |
+
|
| 244 |
+
@torch.jit.script
|
| 245 |
+
def repeat_kv(hidden_states: torch.Tensor, n_rep: int) -> torch.Tensor:
|
| 246 |
+
"""
|
| 247 |
+
This is the equivalent of torch.repeat_interleave(x, dim=1, repeats=n_rep). The hidden states go from (batch,
|
| 248 |
+
num_key_value_heads, seqlen, head_dim) to (batch, num_attention_heads, seqlen, head_dim)
|
| 249 |
+
"""
|
| 250 |
+
batch, slen, _, num_key_value_heads, head_dim = hidden_states.shape
|
| 251 |
+
if n_rep == 1:
|
| 252 |
+
return hidden_states
|
| 253 |
+
hidden_states = hidden_states[:, :, :, :, None, :].expand(batch, slen, 2, num_key_value_heads, n_rep, head_dim)
|
| 254 |
+
return hidden_states.reshape(batch, slen, 2, num_key_value_heads * n_rep, head_dim)
|
| 255 |
+
|
| 256 |
+
|
| 257 |
+
class LlamaAttention(nn.Module):
|
| 258 |
+
"""Multi-headed attention from 'Attention Is All You Need' paper"""
|
| 259 |
+
|
| 260 |
+
def __init__(self, config: LlamaConfig):
|
| 261 |
+
super().__init__()
|
| 262 |
+
self.config = config
|
| 263 |
+
self.hidden_size = config.hidden_size
|
| 264 |
+
self.num_heads = config.num_attention_heads
|
| 265 |
+
self.head_dim = self.hidden_size // self.num_heads
|
| 266 |
+
self.num_key_value_heads = config.num_key_value_heads
|
| 267 |
+
self.num_key_value_groups = self.num_heads // self.num_key_value_heads
|
| 268 |
+
self.max_position_embeddings = config.max_position_embeddings
|
| 269 |
+
|
| 270 |
+
if (self.head_dim * self.num_heads) != self.hidden_size:
|
| 271 |
+
raise ValueError(
|
| 272 |
+
f"hidden_size must be divisible by num_heads (got `hidden_size`: {self.hidden_size}"
|
| 273 |
+
f" and `num_heads`: {self.num_heads})."
|
| 274 |
+
)
|
| 275 |
+
self.q_proj = nn.Linear(self.hidden_size, self.num_heads * self.head_dim, bias=False)
|
| 276 |
+
self.k_proj = nn.Linear(self.hidden_size, self.num_key_value_heads * self.head_dim, bias=False)
|
| 277 |
+
self.v_proj = nn.Linear(self.hidden_size, self.num_key_value_heads * self.head_dim, bias=False)
|
| 278 |
+
self.o_proj = nn.Linear(self.num_heads * self.head_dim, self.hidden_size, bias=False)
|
| 279 |
+
|
| 280 |
+
self.register_buffer(
|
| 281 |
+
"norm_factor",
|
| 282 |
+
torch.sqrt(torch.tensor(self.head_dim, dtype=torch.float32)).to(torch.get_default_dtype()),
|
| 283 |
+
persistent=False,
|
| 284 |
+
)
|
| 285 |
+
|
| 286 |
+
if self.config.rope_scaling is None:
|
| 287 |
+
scaling_factor = 1
|
| 288 |
+
else:
|
| 289 |
+
scaling_type = self.config.rope_scaling["type"]
|
| 290 |
+
scaling_factor = self.config.rope_scaling["factor"]
|
| 291 |
+
assert scaling_type == 'linear'
|
| 292 |
+
|
| 293 |
+
self.rotary_emb = FlashRotaryEmbedding(
|
| 294 |
+
self.head_dim, base=10000, interleaved=False, scaling_factor=scaling_factor,
|
| 295 |
+
)
|
| 296 |
+
|
| 297 |
+
def _shape(self, tensor: torch.Tensor, seq_len: int, bsz: int):
|
| 298 |
+
return tensor.view(bsz, seq_len, self.num_heads, self.head_dim).transpose(1, 2).contiguous()
|
| 299 |
+
|
| 300 |
+
def forward(
|
| 301 |
+
self,
|
| 302 |
+
hidden_states: torch.Tensor,
|
| 303 |
+
attention_mask: Optional[torch.Tensor] = None,
|
| 304 |
+
position_ids: Optional[torch.LongTensor] = None,
|
| 305 |
+
past_key_value: Optional[Tuple[torch.Tensor]] = None,
|
| 306 |
+
output_attentions: bool = False,
|
| 307 |
+
use_cache: bool = False,
|
| 308 |
+
is_padded_inputs: Optional[bool] = False,
|
| 309 |
+
) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]:
|
| 310 |
+
bsz, q_len, h_size = hidden_states.size()
|
| 311 |
+
|
| 312 |
+
has_layer_past = past_key_value is not None
|
| 313 |
+
|
| 314 |
+
if has_layer_past:
|
| 315 |
+
past_kv = past_key_value[0]
|
| 316 |
+
past_len = past_key_value[1]
|
| 317 |
+
else:
|
| 318 |
+
past_len = 0
|
| 319 |
+
|
| 320 |
+
if self.config.pretraining_tp > 1:
|
| 321 |
+
key_value_slicing = (self.num_key_value_heads * self.head_dim) // self.config.pretraining_tp
|
| 322 |
+
query_slices = self.q_proj.weight.split(
|
| 323 |
+
(self.num_heads * self.head_dim) // self.config.pretraining_tp, dim=0
|
| 324 |
+
)
|
| 325 |
+
key_slices = self.k_proj.weight.split(key_value_slicing, dim=0)
|
| 326 |
+
value_slices = self.v_proj.weight.split(key_value_slicing, dim=0)
|
| 327 |
+
|
| 328 |
+
q = [F.linear(hidden_states, query_slices[i]) for i in range(self.config.pretraining_tp)]
|
| 329 |
+
q = torch.cat(q, dim=-1)
|
| 330 |
+
|
| 331 |
+
k = [F.linear(hidden_states, key_slices[i]) for i in range(self.config.pretraining_tp)]
|
| 332 |
+
k = torch.cat(k, dim=-1)
|
| 333 |
+
|
| 334 |
+
v = [F.linear(hidden_states, value_slices[i]) for i in range(self.config.pretraining_tp)]
|
| 335 |
+
v = torch.cat(v, dim=-1)
|
| 336 |
+
|
| 337 |
+
else:
|
| 338 |
+
q = self.q_proj(hidden_states)
|
| 339 |
+
k = self.k_proj(hidden_states)
|
| 340 |
+
v = self.v_proj(hidden_states)
|
| 341 |
+
|
| 342 |
+
q = q.view(bsz, q_len, self.num_heads, self.head_dim)
|
| 343 |
+
k = k.view(bsz, q_len, self.num_key_value_heads, self.head_dim)
|
| 344 |
+
v = v.view(bsz, q_len, self.num_key_value_heads, self.head_dim)
|
| 345 |
+
|
| 346 |
+
q, k = self.rotary_emb(q, k, past_len)
|
| 347 |
+
|
| 348 |
+
kv = torch.stack([k, v], 2)
|
| 349 |
+
kv = repeat_kv(kv, self.num_key_value_groups)
|
| 350 |
+
|
| 351 |
+
# Cache QKV values
|
| 352 |
+
if has_layer_past:
|
| 353 |
+
new_len = past_len+q.size(1)
|
| 354 |
+
if new_len > past_kv.size(1):
|
| 355 |
+
past_kv = torch.cat([past_kv, torch.empty(bsz, 256, 2, kv.size(3), kv.size(4), dtype=kv.dtype, device=kv.device)], 1)
|
| 356 |
+
past_kv[:, past_len:new_len] = kv
|
| 357 |
+
kv = past_kv[:, :new_len]
|
| 358 |
+
else:
|
| 359 |
+
past_kv = kv
|
| 360 |
+
|
| 361 |
+
past_key_value = (past_kv, past_len+q.size(1)) if use_cache else None
|
| 362 |
+
|
| 363 |
+
if is_padded_inputs:
|
| 364 |
+
|
| 365 |
+
# varlen, ignore padding tokens, efficient for large batch with many paddings
|
| 366 |
+
|
| 367 |
+
assert attention_mask is not None
|
| 368 |
+
|
| 369 |
+
unpadded_kv, indices_k, cu_seqlens_k, max_seqlen_k = unpad_input(kv, attention_mask)
|
| 370 |
+
unpadded_q, indices_q, cu_seqlens_q, max_seqlen_q = unpad_input(q, attention_mask[:, -q.size(1):])
|
| 371 |
+
attn_outputs = flash_attn_varlen_kvpacked_func(
|
| 372 |
+
unpadded_q, unpadded_kv, cu_seqlens_q, cu_seqlens_k,
|
| 373 |
+
max_seqlen_q, max_seqlen_k,
|
| 374 |
+
dropout_p=0.0, softmax_scale=1.0/self.norm_factor,
|
| 375 |
+
causal=(not has_layer_past), return_attn_probs=output_attentions
|
| 376 |
+
)
|
| 377 |
+
|
| 378 |
+
attn_output = attn_outputs[0] if output_attentions else attn_outputs
|
| 379 |
+
attn_output = pad_input(
|
| 380 |
+
attn_output, indices_q, bsz, q_len
|
| 381 |
+
).reshape(bsz, q_len, h_size)
|
| 382 |
+
attn_weights = attn_outputs[2] if output_attentions else None
|
| 383 |
+
|
| 384 |
+
else:
|
| 385 |
+
|
| 386 |
+
# no padding tokens, more efficient
|
| 387 |
+
|
| 388 |
+
attn_outputs = flash_attn_kvpacked_func(
|
| 389 |
+
q, kv, dropout_p=0.0, softmax_scale=1.0/self.norm_factor, causal=(not has_layer_past), return_attn_probs=output_attentions)
|
| 390 |
+
|
| 391 |
+
attn_output = attn_outputs[0] if output_attentions else attn_outputs
|
| 392 |
+
attn_output = attn_output.reshape(bsz, q_len, h_size)
|
| 393 |
+
attn_weights = attn_outputs[2] if output_attentions else None
|
| 394 |
+
|
| 395 |
+
if self.config.pretraining_tp > 1:
|
| 396 |
+
attn_output = attn_output.split(self.hidden_size // self.config.pretraining_tp, dim=2)
|
| 397 |
+
o_proj_slices = self.o_proj.weight.split(self.hidden_size // self.config.pretraining_tp, dim=1)
|
| 398 |
+
attn_output = sum([F.linear(attn_output[i], o_proj_slices[i]) for i in range(self.config.pretraining_tp)])
|
| 399 |
+
else:
|
| 400 |
+
attn_output = self.o_proj(attn_output)
|
| 401 |
+
|
| 402 |
+
if not output_attentions:
|
| 403 |
+
attn_weights = None
|
| 404 |
+
|
| 405 |
+
return attn_output, attn_weights, past_key_value
|
| 406 |
+
|
| 407 |
+
|
| 408 |
+
class LlamaDecoderLayer(nn.Module):
|
| 409 |
+
def __init__(self, config: LlamaConfig):
|
| 410 |
+
super().__init__()
|
| 411 |
+
self.hidden_size = config.hidden_size
|
| 412 |
+
self.self_attn = LlamaAttention(config=config)
|
| 413 |
+
self.mlp = LlamaMLP(config)
|
| 414 |
+
self.input_layernorm = LlamaRMSNorm(config.hidden_size, eps=config.rms_norm_eps)
|
| 415 |
+
self.post_attention_layernorm = LlamaRMSNorm(config.hidden_size, eps=config.rms_norm_eps)
|
| 416 |
+
|
| 417 |
+
def forward(
|
| 418 |
+
self,
|
| 419 |
+
hidden_states: torch.Tensor,
|
| 420 |
+
attention_mask: Optional[torch.Tensor] = None,
|
| 421 |
+
position_ids: Optional[torch.LongTensor] = None,
|
| 422 |
+
past_key_value: Optional[Tuple[torch.Tensor]] = None,
|
| 423 |
+
is_padded_inputs: Optional[bool] = False,
|
| 424 |
+
output_attentions: Optional[bool] = False,
|
| 425 |
+
use_cache: Optional[bool] = False,
|
| 426 |
+
) -> Tuple[torch.FloatTensor, Optional[Tuple[torch.FloatTensor, torch.FloatTensor]]]:
|
| 427 |
+
"""
|
| 428 |
+
Args:
|
| 429 |
+
hidden_states (`torch.FloatTensor`): input to the layer of shape `(batch, seq_len, embed_dim)`
|
| 430 |
+
attention_mask (`torch.FloatTensor`, *optional*): attention mask of size
|
| 431 |
+
`(batch, 1, tgt_len, src_len)` where padding elements are indicated by very large negative values.
|
| 432 |
+
output_attentions (`bool`, *optional*):
|
| 433 |
+
Whether or not to return the attentions tensors of all attention layers. See `attentions` under
|
| 434 |
+
returned tensors for more detail.
|
| 435 |
+
use_cache (`bool`, *optional*):
|
| 436 |
+
If set to `True`, `past_key_values` key value states are returned and can be used to speed up decoding
|
| 437 |
+
(see `past_key_values`).
|
| 438 |
+
past_key_value (`Tuple(torch.FloatTensor)`, *optional*): cached past key and value projection states
|
| 439 |
+
"""
|
| 440 |
+
|
| 441 |
+
residual = hidden_states
|
| 442 |
+
|
| 443 |
+
hidden_states = self.input_layernorm(hidden_states)
|
| 444 |
+
|
| 445 |
+
# Self Attention
|
| 446 |
+
hidden_states, self_attn_weights, present_key_value = self.self_attn(
|
| 447 |
+
hidden_states=hidden_states,
|
| 448 |
+
attention_mask=attention_mask,
|
| 449 |
+
position_ids=position_ids,
|
| 450 |
+
past_key_value=past_key_value,
|
| 451 |
+
output_attentions=output_attentions,
|
| 452 |
+
use_cache=use_cache,
|
| 453 |
+
is_padded_inputs=is_padded_inputs,
|
| 454 |
+
)
|
| 455 |
+
hidden_states = residual + hidden_states
|
| 456 |
+
|
| 457 |
+
# Fully Connected
|
| 458 |
+
residual = hidden_states
|
| 459 |
+
hidden_states = self.post_attention_layernorm(hidden_states)
|
| 460 |
+
hidden_states = self.mlp(hidden_states)
|
| 461 |
+
hidden_states = residual + hidden_states
|
| 462 |
+
|
| 463 |
+
outputs = (hidden_states,)
|
| 464 |
+
|
| 465 |
+
if output_attentions:
|
| 466 |
+
outputs += (self_attn_weights,)
|
| 467 |
+
|
| 468 |
+
if use_cache:
|
| 469 |
+
outputs += (present_key_value,)
|
| 470 |
+
|
| 471 |
+
return outputs
|
| 472 |
+
|
| 473 |
+
|
| 474 |
+
LLAMA_START_DOCSTRING = r"""
|
| 475 |
+
This model inherits from [`PreTrainedModel`]. Check the superclass documentation for the generic methods the
|
| 476 |
+
library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads
|
| 477 |
+
etc.)
|
| 478 |
+
|
| 479 |
+
This model is also a PyTorch [torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) subclass.
|
| 480 |
+
Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage
|
| 481 |
+
and behavior.
|
| 482 |
+
|
| 483 |
+
Parameters:
|
| 484 |
+
config ([`LlamaConfig`]):
|
| 485 |
+
Model configuration class with all the parameters of the model. Initializing with a config file does not
|
| 486 |
+
load the weights associated with the model, only the configuration. Check out the
|
| 487 |
+
[`~PreTrainedModel.from_pretrained`] method to load the model weights.
|
| 488 |
+
"""
|
| 489 |
+
|
| 490 |
+
|
| 491 |
+
@add_start_docstrings(
|
| 492 |
+
"The bare LLaMA Model outputting raw hidden-states without any specific head on top.",
|
| 493 |
+
LLAMA_START_DOCSTRING,
|
| 494 |
+
)
|
| 495 |
+
class LlamaPreTrainedModel(PreTrainedModel):
|
| 496 |
+
config_class = LlamaConfig
|
| 497 |
+
base_model_prefix = "model"
|
| 498 |
+
supports_gradient_checkpointing = True
|
| 499 |
+
_no_split_modules = ["LlamaDecoderLayer"]
|
| 500 |
+
_skip_keys_device_placement = "past_key_values"
|
| 501 |
+
|
| 502 |
+
def _init_weights(self, module):
|
| 503 |
+
std = self.config.initializer_range
|
| 504 |
+
if isinstance(module, nn.Linear):
|
| 505 |
+
module.weight.data.normal_(mean=0.0, std=std)
|
| 506 |
+
if module.bias is not None:
|
| 507 |
+
module.bias.data.zero_()
|
| 508 |
+
elif isinstance(module, nn.Embedding):
|
| 509 |
+
module.weight.data.normal_(mean=0.0, std=std)
|
| 510 |
+
if module.padding_idx is not None:
|
| 511 |
+
module.weight.data[module.padding_idx].zero_()
|
| 512 |
+
|
| 513 |
+
def _set_gradient_checkpointing(self, module, value=False):
|
| 514 |
+
if isinstance(module, LlamaModel):
|
| 515 |
+
module.gradient_checkpointing = value
|
| 516 |
+
|
| 517 |
+
|
| 518 |
+
LLAMA_INPUTS_DOCSTRING = r"""
|
| 519 |
+
Args:
|
| 520 |
+
input_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`):
|
| 521 |
+
Indices of input sequence tokens in the vocabulary. Padding will be ignored by default should you provide
|
| 522 |
+
it.
|
| 523 |
+
|
| 524 |
+
Indices can be obtained using [`AutoTokenizer`]. See [`PreTrainedTokenizer.encode`] and
|
| 525 |
+
[`PreTrainedTokenizer.__call__`] for details.
|
| 526 |
+
|
| 527 |
+
[What are input IDs?](../glossary#input-ids)
|
| 528 |
+
attention_mask (`torch.Tensor` of shape `(batch_size, sequence_length)`, *optional*):
|
| 529 |
+
Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
|
| 530 |
+
|
| 531 |
+
- 1 for tokens that are **not masked**,
|
| 532 |
+
- 0 for tokens that are **masked**.
|
| 533 |
+
|
| 534 |
+
[What are attention masks?](../glossary#attention-mask)
|
| 535 |
+
|
| 536 |
+
Indices can be obtained using [`AutoTokenizer`]. See [`PreTrainedTokenizer.encode`] and
|
| 537 |
+
[`PreTrainedTokenizer.__call__`] for details.
|
| 538 |
+
|
| 539 |
+
If `past_key_values` is used, optionally only the last `decoder_input_ids` have to be input (see
|
| 540 |
+
`past_key_values`).
|
| 541 |
+
|
| 542 |
+
If you want to change padding behavior, you should read [`modeling_opt._prepare_decoder_attention_mask`]
|
| 543 |
+
and modify to your needs. See diagram 1 in [the paper](https://arxiv.org/abs/1910.13461) for more
|
| 544 |
+
information on the default strategy.
|
| 545 |
+
|
| 546 |
+
- 1 indicates the head is **not masked**,
|
| 547 |
+
- 0 indicates the head is **masked**.
|
| 548 |
+
position_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
|
| 549 |
+
Indices of positions of each input sequence tokens in the position embeddings. Selected in the range `[0,
|
| 550 |
+
config.n_positions - 1]`.
|
| 551 |
+
|
| 552 |
+
[What are position IDs?](../glossary#position-ids)
|
| 553 |
+
past_key_values (`tuple(tuple(torch.FloatTensor))`, *optional*, returned when `use_cache=True` is passed or when `config.use_cache=True`):
|
| 554 |
+
Tuple of `tuple(torch.FloatTensor)` of length `config.n_layers`, with each tuple having 2 tensors of shape
|
| 555 |
+
`(batch_size, num_heads, sequence_length, embed_size_per_head)`) and 2 additional tensors of shape
|
| 556 |
+
`(batch_size, num_heads, encoder_sequence_length, embed_size_per_head)`.
|
| 557 |
+
|
| 558 |
+
Contains pre-computed hidden-states (key and values in the self-attention blocks and in the cross-attention
|
| 559 |
+
blocks) that can be used (see `past_key_values` input) to speed up sequential decoding.
|
| 560 |
+
|
| 561 |
+
If `past_key_values` are used, the user can optionally input only the last `decoder_input_ids` (those that
|
| 562 |
+
don't have their past key value states given to this model) of shape `(batch_size, 1)` instead of all
|
| 563 |
+
`decoder_input_ids` of shape `(batch_size, sequence_length)`.
|
| 564 |
+
inputs_embeds (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`, *optional*):
|
| 565 |
+
Optionally, instead of passing `input_ids` you can choose to directly pass an embedded representation. This
|
| 566 |
+
is useful if you want more control over how to convert `input_ids` indices into associated vectors than the
|
| 567 |
+
model's internal embedding lookup matrix.
|
| 568 |
+
use_cache (`bool`, *optional*):
|
| 569 |
+
If set to `True`, `past_key_values` key value states are returned and can be used to speed up decoding (see
|
| 570 |
+
`past_key_values`).
|
| 571 |
+
output_attentions (`bool`, *optional*):
|
| 572 |
+
Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
|
| 573 |
+
tensors for more detail.
|
| 574 |
+
output_hidden_states (`bool`, *optional*):
|
| 575 |
+
Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
|
| 576 |
+
more detail.
|
| 577 |
+
return_dict (`bool`, *optional*):
|
| 578 |
+
Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
|
| 579 |
+
"""
|
| 580 |
+
|
| 581 |
+
|
| 582 |
+
@add_start_docstrings(
|
| 583 |
+
"The bare LLaMA Model outputting raw hidden-states without any specific head on top.",
|
| 584 |
+
LLAMA_START_DOCSTRING,
|
| 585 |
+
)
|
| 586 |
+
class LlamaModel(LlamaPreTrainedModel):
|
| 587 |
+
"""
|
| 588 |
+
Transformer decoder consisting of *config.num_hidden_layers* layers. Each layer is a [`LlamaDecoderLayer`]
|
| 589 |
+
|
| 590 |
+
Args:
|
| 591 |
+
config: LlamaConfig
|
| 592 |
+
"""
|
| 593 |
+
|
| 594 |
+
def __init__(self, config: LlamaConfig):
|
| 595 |
+
super().__init__(config)
|
| 596 |
+
self.padding_idx = config.pad_token_id
|
| 597 |
+
self.vocab_size = config.vocab_size
|
| 598 |
+
|
| 599 |
+
self.embed_tokens = nn.Embedding(config.vocab_size, config.hidden_size, self.padding_idx)
|
| 600 |
+
self.layers = nn.ModuleList([LlamaDecoderLayer(config) for _ in range(config.num_hidden_layers)])
|
| 601 |
+
self.norm = LlamaRMSNorm(config.hidden_size, eps=config.rms_norm_eps)
|
| 602 |
+
|
| 603 |
+
self.gradient_checkpointing = False
|
| 604 |
+
# Initialize weights and apply final processing
|
| 605 |
+
self.post_init()
|
| 606 |
+
|
| 607 |
+
def get_input_embeddings(self):
|
| 608 |
+
return self.embed_tokens
|
| 609 |
+
|
| 610 |
+
def set_input_embeddings(self, value):
|
| 611 |
+
self.embed_tokens = value
|
| 612 |
+
|
| 613 |
+
@add_start_docstrings_to_model_forward(LLAMA_INPUTS_DOCSTRING)
|
| 614 |
+
def forward(
|
| 615 |
+
self,
|
| 616 |
+
input_ids: torch.LongTensor = None,
|
| 617 |
+
attention_mask: Optional[torch.Tensor] = None,
|
| 618 |
+
position_ids: Optional[torch.LongTensor] = None,
|
| 619 |
+
past_key_values: Optional[List[torch.FloatTensor]] = None,
|
| 620 |
+
inputs_embeds: Optional[torch.FloatTensor] = None,
|
| 621 |
+
use_cache: Optional[bool] = None,
|
| 622 |
+
output_attentions: Optional[bool] = None,
|
| 623 |
+
output_hidden_states: Optional[bool] = None,
|
| 624 |
+
return_dict: Optional[bool] = None,
|
| 625 |
+
is_padded_inputs: Optional[bool] = False,
|
| 626 |
+
) -> Union[Tuple, BaseModelOutputWithPast]:
|
| 627 |
+
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
|
| 628 |
+
output_hidden_states = (
|
| 629 |
+
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
|
| 630 |
+
)
|
| 631 |
+
use_cache = use_cache if use_cache is not None else self.config.use_cache
|
| 632 |
+
|
| 633 |
+
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
|
| 634 |
+
|
| 635 |
+
# retrieve input_ids and inputs_embeds
|
| 636 |
+
if input_ids is not None and inputs_embeds is not None:
|
| 637 |
+
raise ValueError("You cannot specify both decoder_input_ids and decoder_inputs_embeds at the same time")
|
| 638 |
+
elif input_ids is not None:
|
| 639 |
+
batch_size, seq_length = input_ids.shape
|
| 640 |
+
elif inputs_embeds is not None:
|
| 641 |
+
batch_size, seq_length, _ = inputs_embeds.shape
|
| 642 |
+
else:
|
| 643 |
+
raise ValueError("You have to specify either decoder_input_ids or decoder_inputs_embeds")
|
| 644 |
+
|
| 645 |
+
seq_length_with_past = seq_length
|
| 646 |
+
past_key_values_length = 0
|
| 647 |
+
|
| 648 |
+
if past_key_values is not None:
|
| 649 |
+
past_key_values_length = past_key_values[0][0].shape[2]
|
| 650 |
+
seq_length_with_past = seq_length_with_past + past_key_values_length
|
| 651 |
+
|
| 652 |
+
position_ids = None
|
| 653 |
+
|
| 654 |
+
if inputs_embeds is None:
|
| 655 |
+
inputs_embeds = self.embed_tokens(input_ids)
|
| 656 |
+
|
| 657 |
+
hidden_states = inputs_embeds
|
| 658 |
+
|
| 659 |
+
if self.gradient_checkpointing and self.training:
|
| 660 |
+
if use_cache:
|
| 661 |
+
logger.warning_once(
|
| 662 |
+
"`use_cache=True` is incompatible with gradient checkpointing. Setting `use_cache=False`..."
|
| 663 |
+
)
|
| 664 |
+
use_cache = False
|
| 665 |
+
|
| 666 |
+
# decoder layers
|
| 667 |
+
all_hidden_states = () if output_hidden_states else None
|
| 668 |
+
all_self_attns = () if output_attentions else None
|
| 669 |
+
next_decoder_cache = () if use_cache else None
|
| 670 |
+
|
| 671 |
+
for idx, decoder_layer in enumerate(self.layers):
|
| 672 |
+
if output_hidden_states:
|
| 673 |
+
all_hidden_states += (hidden_states,)
|
| 674 |
+
|
| 675 |
+
past_key_value = past_key_values[idx] if past_key_values is not None else None
|
| 676 |
+
|
| 677 |
+
if self.gradient_checkpointing and self.training:
|
| 678 |
+
|
| 679 |
+
def create_custom_forward(module):
|
| 680 |
+
def custom_forward(*inputs):
|
| 681 |
+
# None for past_key_value
|
| 682 |
+
return module(*inputs, output_attentions, None)
|
| 683 |
+
|
| 684 |
+
return custom_forward
|
| 685 |
+
|
| 686 |
+
layer_outputs = torch.utils.checkpoint.checkpoint(
|
| 687 |
+
create_custom_forward(decoder_layer),
|
| 688 |
+
hidden_states,
|
| 689 |
+
attention_mask,
|
| 690 |
+
position_ids,
|
| 691 |
+
None,
|
| 692 |
+
is_padded_inputs
|
| 693 |
+
)
|
| 694 |
+
else:
|
| 695 |
+
layer_outputs = decoder_layer(
|
| 696 |
+
hidden_states,
|
| 697 |
+
attention_mask=attention_mask,
|
| 698 |
+
position_ids=position_ids,
|
| 699 |
+
past_key_value=past_key_value,
|
| 700 |
+
output_attentions=output_attentions,
|
| 701 |
+
use_cache=use_cache,
|
| 702 |
+
is_padded_inputs=is_padded_inputs,
|
| 703 |
+
)
|
| 704 |
+
|
| 705 |
+
hidden_states = layer_outputs[0]
|
| 706 |
+
|
| 707 |
+
if use_cache:
|
| 708 |
+
next_decoder_cache += (layer_outputs[2 if output_attentions else 1],)
|
| 709 |
+
|
| 710 |
+
if output_attentions:
|
| 711 |
+
all_self_attns += (layer_outputs[1],)
|
| 712 |
+
|
| 713 |
+
hidden_states = self.norm(hidden_states)
|
| 714 |
+
|
| 715 |
+
# add hidden states from the last decoder layer
|
| 716 |
+
if output_hidden_states:
|
| 717 |
+
all_hidden_states += (hidden_states,)
|
| 718 |
+
|
| 719 |
+
next_cache = next_decoder_cache if use_cache else None
|
| 720 |
+
if not return_dict:
|
| 721 |
+
return tuple(v for v in [hidden_states, next_cache, all_hidden_states, all_self_attns] if v is not None)
|
| 722 |
+
return BaseModelOutputWithPast(
|
| 723 |
+
last_hidden_state=hidden_states,
|
| 724 |
+
past_key_values=next_cache,
|
| 725 |
+
hidden_states=all_hidden_states,
|
| 726 |
+
attentions=all_self_attns,
|
| 727 |
+
)
|
| 728 |
+
|
| 729 |
+
|
| 730 |
+
class LlamaForCausalLM(LlamaPreTrainedModel):
|
| 731 |
+
_tied_weights_keys = ["lm_head.weight"]
|
| 732 |
+
|
| 733 |
+
def __init__(self, config):
|
| 734 |
+
super().__init__(config)
|
| 735 |
+
self.model = LlamaModel(config)
|
| 736 |
+
self.vocab_size = config.vocab_size
|
| 737 |
+
self.lm_head = nn.Linear(config.hidden_size, config.vocab_size, bias=False)
|
| 738 |
+
|
| 739 |
+
# Initialize weights and apply final processing
|
| 740 |
+
self.post_init()
|
| 741 |
+
|
| 742 |
+
def get_input_embeddings(self):
|
| 743 |
+
return self.model.embed_tokens
|
| 744 |
+
|
| 745 |
+
def set_input_embeddings(self, value):
|
| 746 |
+
self.model.embed_tokens = value
|
| 747 |
+
|
| 748 |
+
def get_output_embeddings(self):
|
| 749 |
+
return self.lm_head
|
| 750 |
+
|
| 751 |
+
def set_output_embeddings(self, new_embeddings):
|
| 752 |
+
self.lm_head = new_embeddings
|
| 753 |
+
|
| 754 |
+
def set_decoder(self, decoder):
|
| 755 |
+
self.model = decoder
|
| 756 |
+
|
| 757 |
+
def get_decoder(self):
|
| 758 |
+
return self.model
|
| 759 |
+
|
| 760 |
+
@add_start_docstrings_to_model_forward(LLAMA_INPUTS_DOCSTRING)
|
| 761 |
+
@replace_return_docstrings(output_type=CausalLMOutputWithPast, config_class=_CONFIG_FOR_DOC)
|
| 762 |
+
def forward(
|
| 763 |
+
self,
|
| 764 |
+
input_ids: torch.LongTensor = None,
|
| 765 |
+
attention_mask: Optional[torch.Tensor] = None,
|
| 766 |
+
position_ids: Optional[torch.LongTensor] = None,
|
| 767 |
+
past_key_values: Optional[List[torch.FloatTensor]] = None,
|
| 768 |
+
inputs_embeds: Optional[torch.FloatTensor] = None,
|
| 769 |
+
labels: Optional[torch.LongTensor] = None,
|
| 770 |
+
use_cache: Optional[bool] = None,
|
| 771 |
+
output_attentions: Optional[bool] = None,
|
| 772 |
+
output_hidden_states: Optional[bool] = None,
|
| 773 |
+
return_dict: Optional[bool] = None,
|
| 774 |
+
is_padded_inputs: Optional[bool] = None,
|
| 775 |
+
) -> Union[Tuple, CausalLMOutputWithPast]:
|
| 776 |
+
r"""
|
| 777 |
+
Args:
|
| 778 |
+
labels (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
|
| 779 |
+
Labels for computing the masked language modeling loss. Indices should either be in `[0, ...,
|
| 780 |
+
config.vocab_size]` or -100 (see `input_ids` docstring). Tokens with indices set to `-100` are ignored
|
| 781 |
+
(masked), the loss is only computed for the tokens with labels in `[0, ..., config.vocab_size]`.
|
| 782 |
+
|
| 783 |
+
Returns:
|
| 784 |
+
|
| 785 |
+
Example:
|
| 786 |
+
|
| 787 |
+
```python
|
| 788 |
+
>>> from transformers import AutoTokenizer, LlamaForCausalLM
|
| 789 |
+
|
| 790 |
+
>>> model = LlamaForCausalLM.from_pretrained(PATH_TO_CONVERTED_WEIGHTS)
|
| 791 |
+
>>> tokenizer = AutoTokenizer.from_pretrained(PATH_TO_CONVERTED_TOKENIZER)
|
| 792 |
+
|
| 793 |
+
>>> prompt = "Hey, are you conscious? Can you talk to me?"
|
| 794 |
+
>>> inputs = tokenizer(prompt, return_tensors="pt")
|
| 795 |
+
|
| 796 |
+
>>> # Generate
|
| 797 |
+
>>> generate_ids = model.generate(inputs.input_ids, max_length=30)
|
| 798 |
+
>>> tokenizer.batch_decode(generate_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False)[0]
|
| 799 |
+
"Hey, are you conscious? Can you talk to me?\nI'm not conscious, but I can talk to you."
|
| 800 |
+
```"""
|
| 801 |
+
|
| 802 |
+
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
|
| 803 |
+
output_hidden_states = (
|
| 804 |
+
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
|
| 805 |
+
)
|
| 806 |
+
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
|
| 807 |
+
|
| 808 |
+
is_padded_inputs = ((attention_mask is not None) and (not attention_mask.all().item()))
|
| 809 |
+
|
| 810 |
+
# decoder outputs consists of (dec_features, layer_state, dec_hidden, dec_attn)
|
| 811 |
+
outputs = self.model(
|
| 812 |
+
input_ids=input_ids,
|
| 813 |
+
attention_mask=attention_mask,
|
| 814 |
+
position_ids=position_ids,
|
| 815 |
+
past_key_values=past_key_values,
|
| 816 |
+
inputs_embeds=inputs_embeds,
|
| 817 |
+
use_cache=use_cache,
|
| 818 |
+
output_attentions=output_attentions,
|
| 819 |
+
output_hidden_states=output_hidden_states,
|
| 820 |
+
return_dict=return_dict,
|
| 821 |
+
is_padded_inputs=is_padded_inputs,
|
| 822 |
+
)
|
| 823 |
+
|
| 824 |
+
hidden_states = outputs[0]
|
| 825 |
+
if self.config.pretraining_tp > 1:
|
| 826 |
+
lm_head_slices = self.lm_head.weight.split(self.vocab_size // self.config.pretraining_tp, dim=0)
|
| 827 |
+
logits = [F.linear(hidden_states, lm_head_slices[i]) for i in range(self.config.pretraining_tp)]
|
| 828 |
+
logits = torch.cat(logits, dim=-1)
|
| 829 |
+
else:
|
| 830 |
+
logits = self.lm_head(hidden_states)
|
| 831 |
+
logits = logits.float()
|
| 832 |
+
|
| 833 |
+
loss = None
|
| 834 |
+
if labels is not None:
|
| 835 |
+
# Shift so that tokens < n predict n
|
| 836 |
+
shift_logits = logits[..., :-1, :].contiguous()
|
| 837 |
+
shift_labels = labels[..., 1:].contiguous()
|
| 838 |
+
# Flatten the tokens
|
| 839 |
+
loss_fct = CrossEntropyLoss()
|
| 840 |
+
shift_logits = shift_logits.view(-1, self.config.vocab_size)
|
| 841 |
+
shift_labels = shift_labels.view(-1)
|
| 842 |
+
# Enable model parallelism
|
| 843 |
+
shift_labels = shift_labels.to(shift_logits.device)
|
| 844 |
+
loss = loss_fct(shift_logits, shift_labels)
|
| 845 |
+
|
| 846 |
+
if not return_dict:
|
| 847 |
+
output = (logits,) + outputs[1:]
|
| 848 |
+
return (loss,) + output if loss is not None else output
|
| 849 |
+
|
| 850 |
+
return CausalLMOutputWithPast(
|
| 851 |
+
loss=loss,
|
| 852 |
+
logits=logits,
|
| 853 |
+
past_key_values=outputs.past_key_values,
|
| 854 |
+
hidden_states=outputs.hidden_states,
|
| 855 |
+
attentions=outputs.attentions,
|
| 856 |
+
)
|
| 857 |
+
|
| 858 |
+
def prepare_inputs_for_generation(
|
| 859 |
+
self, input_ids, past_key_values=None, attention_mask=None, inputs_embeds=None, **kwargs
|
| 860 |
+
):
|
| 861 |
+
if past_key_values:
|
| 862 |
+
input_ids = input_ids[:, -1:]
|
| 863 |
+
|
| 864 |
+
position_ids = kwargs.get("position_ids", None)
|
| 865 |
+
|
| 866 |
+
# if `inputs_embeds` are passed, we only want to use them in the 1st generation step
|
| 867 |
+
if inputs_embeds is not None and past_key_values is None:
|
| 868 |
+
model_inputs = {"inputs_embeds": inputs_embeds}
|
| 869 |
+
else:
|
| 870 |
+
model_inputs = {"input_ids": input_ids}
|
| 871 |
+
|
| 872 |
+
model_inputs.update(
|
| 873 |
+
{
|
| 874 |
+
"position_ids": position_ids,
|
| 875 |
+
"past_key_values": past_key_values,
|
| 876 |
+
"use_cache": kwargs.get("use_cache"),
|
| 877 |
+
"attention_mask": attention_mask,
|
| 878 |
+
"is_padded_inputs": ((attention_mask is not None) and (not attention_mask.all().item()))
|
| 879 |
+
}
|
| 880 |
+
)
|
| 881 |
+
return model_inputs
|
| 882 |
+
|
| 883 |
+
@staticmethod
|
| 884 |
+
def _reorder_cache(past_key_values, beam_idx):
|
| 885 |
+
reordered_past = ()
|
| 886 |
+
for layer_past in past_key_values:
|
| 887 |
+
reordered_past += (
|
| 888 |
+
tuple(past_state.index_select(0, beam_idx.to(past_state.device)) for past_state in layer_past),
|
| 889 |
+
)
|
| 890 |
+
return reordered_past
|
| 891 |
+
|
| 892 |
+
|
| 893 |
+
@add_start_docstrings(
|
| 894 |
+
"""
|
| 895 |
+
The LLaMa Model transformer with a sequence classification head on top (linear layer).
|
| 896 |
+
|
| 897 |
+
[`LlamaForSequenceClassification`] uses the last token in order to do the classification, as other causal models
|
| 898 |
+
(e.g. GPT-2) do.
|
| 899 |
+
|
| 900 |
+
Since it does classification on the last token, it requires to know the position of the last token. If a
|
| 901 |
+
`pad_token_id` is defined in the configuration, it finds the last token that is not a padding token in each row. If
|
| 902 |
+
no `pad_token_id` is defined, it simply takes the last value in each row of the batch. Since it cannot guess the
|
| 903 |
+
padding tokens when `inputs_embeds` are passed instead of `input_ids`, it does the same (take the last value in
|
| 904 |
+
each row of the batch).
|
| 905 |
+
""",
|
| 906 |
+
LLAMA_START_DOCSTRING,
|
| 907 |
+
)
|
| 908 |
+
class LlamaForSequenceClassification(LlamaPreTrainedModel):
|
| 909 |
+
def __init__(self, config):
|
| 910 |
+
super().__init__(config)
|
| 911 |
+
self.num_labels = config.num_labels
|
| 912 |
+
self.model = LlamaModel(config)
|
| 913 |
+
self.score = nn.Linear(config.hidden_size, self.num_labels, bias=False)
|
| 914 |
+
|
| 915 |
+
# Initialize weights and apply final processing
|
| 916 |
+
self.post_init()
|
| 917 |
+
|
| 918 |
+
def get_input_embeddings(self):
|
| 919 |
+
return self.model.embed_tokens
|
| 920 |
+
|
| 921 |
+
def set_input_embeddings(self, value):
|
| 922 |
+
self.model.embed_tokens = value
|
| 923 |
+
|
| 924 |
+
@add_start_docstrings_to_model_forward(LLAMA_INPUTS_DOCSTRING)
|
| 925 |
+
def forward(
|
| 926 |
+
self,
|
| 927 |
+
input_ids: torch.LongTensor = None,
|
| 928 |
+
attention_mask: Optional[torch.Tensor] = None,
|
| 929 |
+
position_ids: Optional[torch.LongTensor] = None,
|
| 930 |
+
past_key_values: Optional[List[torch.FloatTensor]] = None,
|
| 931 |
+
inputs_embeds: Optional[torch.FloatTensor] = None,
|
| 932 |
+
labels: Optional[torch.LongTensor] = None,
|
| 933 |
+
use_cache: Optional[bool] = None,
|
| 934 |
+
output_attentions: Optional[bool] = None,
|
| 935 |
+
output_hidden_states: Optional[bool] = None,
|
| 936 |
+
return_dict: Optional[bool] = None,
|
| 937 |
+
) -> Union[Tuple, SequenceClassifierOutputWithPast]:
|
| 938 |
+
r"""
|
| 939 |
+
labels (`torch.LongTensor` of shape `(batch_size,)`, *optional*):
|
| 940 |
+
Labels for computing the sequence classification/regression loss. Indices should be in `[0, ...,
|
| 941 |
+
config.num_labels - 1]`. If `config.num_labels == 1` a regression loss is computed (Mean-Square loss), If
|
| 942 |
+
`config.num_labels > 1` a classification loss is computed (Cross-Entropy).
|
| 943 |
+
"""
|
| 944 |
+
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
|
| 945 |
+
|
| 946 |
+
transformer_outputs = self.model(
|
| 947 |
+
input_ids,
|
| 948 |
+
attention_mask=attention_mask,
|
| 949 |
+
position_ids=position_ids,
|
| 950 |
+
past_key_values=past_key_values,
|
| 951 |
+
inputs_embeds=inputs_embeds,
|
| 952 |
+
use_cache=use_cache,
|
| 953 |
+
output_attentions=output_attentions,
|
| 954 |
+
output_hidden_states=output_hidden_states,
|
| 955 |
+
return_dict=return_dict,
|
| 956 |
+
)
|
| 957 |
+
hidden_states = transformer_outputs[0]
|
| 958 |
+
logits = self.score(hidden_states)
|
| 959 |
+
|
| 960 |
+
if input_ids is not None:
|
| 961 |
+
batch_size = input_ids.shape[0]
|
| 962 |
+
else:
|
| 963 |
+
batch_size = inputs_embeds.shape[0]
|
| 964 |
+
|
| 965 |
+
if self.config.pad_token_id is None and batch_size != 1:
|
| 966 |
+
raise ValueError("Cannot handle batch sizes > 1 if no padding token is defined.")
|
| 967 |
+
if self.config.pad_token_id is None:
|
| 968 |
+
sequence_lengths = -1
|
| 969 |
+
else:
|
| 970 |
+
if input_ids is not None:
|
| 971 |
+
sequence_lengths = (torch.ne(input_ids, self.config.pad_token_id).sum(-1) - 1).to(logits.device)
|
| 972 |
+
else:
|
| 973 |
+
sequence_lengths = -1
|
| 974 |
+
|
| 975 |
+
pooled_logits = logits[torch.arange(batch_size, device=logits.device), sequence_lengths]
|
| 976 |
+
|
| 977 |
+
loss = None
|
| 978 |
+
if labels is not None:
|
| 979 |
+
labels = labels.to(logits.device)
|
| 980 |
+
if self.config.problem_type is None:
|
| 981 |
+
if self.num_labels == 1:
|
| 982 |
+
self.config.problem_type = "regression"
|
| 983 |
+
elif self.num_labels > 1 and (labels.dtype == torch.long or labels.dtype == torch.int):
|
| 984 |
+
self.config.problem_type = "single_label_classification"
|
| 985 |
+
else:
|
| 986 |
+
self.config.problem_type = "multi_label_classification"
|
| 987 |
+
|
| 988 |
+
if self.config.problem_type == "regression":
|
| 989 |
+
loss_fct = MSELoss()
|
| 990 |
+
if self.num_labels == 1:
|
| 991 |
+
loss = loss_fct(pooled_logits.squeeze(), labels.squeeze())
|
| 992 |
+
else:
|
| 993 |
+
loss = loss_fct(pooled_logits, labels)
|
| 994 |
+
elif self.config.problem_type == "single_label_classification":
|
| 995 |
+
loss_fct = CrossEntropyLoss()
|
| 996 |
+
loss = loss_fct(pooled_logits.view(-1, self.num_labels), labels.view(-1))
|
| 997 |
+
elif self.config.problem_type == "multi_label_classification":
|
| 998 |
+
loss_fct = BCEWithLogitsLoss()
|
| 999 |
+
loss = loss_fct(pooled_logits, labels)
|
| 1000 |
+
if not return_dict:
|
| 1001 |
+
output = (pooled_logits,) + transformer_outputs[1:]
|
| 1002 |
+
return ((loss,) + output) if loss is not None else output
|
| 1003 |
+
|
| 1004 |
+
return SequenceClassifierOutputWithPast(
|
| 1005 |
+
loss=loss,
|
| 1006 |
+
logits=pooled_logits,
|
| 1007 |
+
past_key_values=transformer_outputs.past_key_values,
|
| 1008 |
+
hidden_states=transformer_outputs.hidden_states,
|
| 1009 |
+
attentions=transformer_outputs.attentions,
|
| 1010 |
+
)
|
plots.png
ADDED
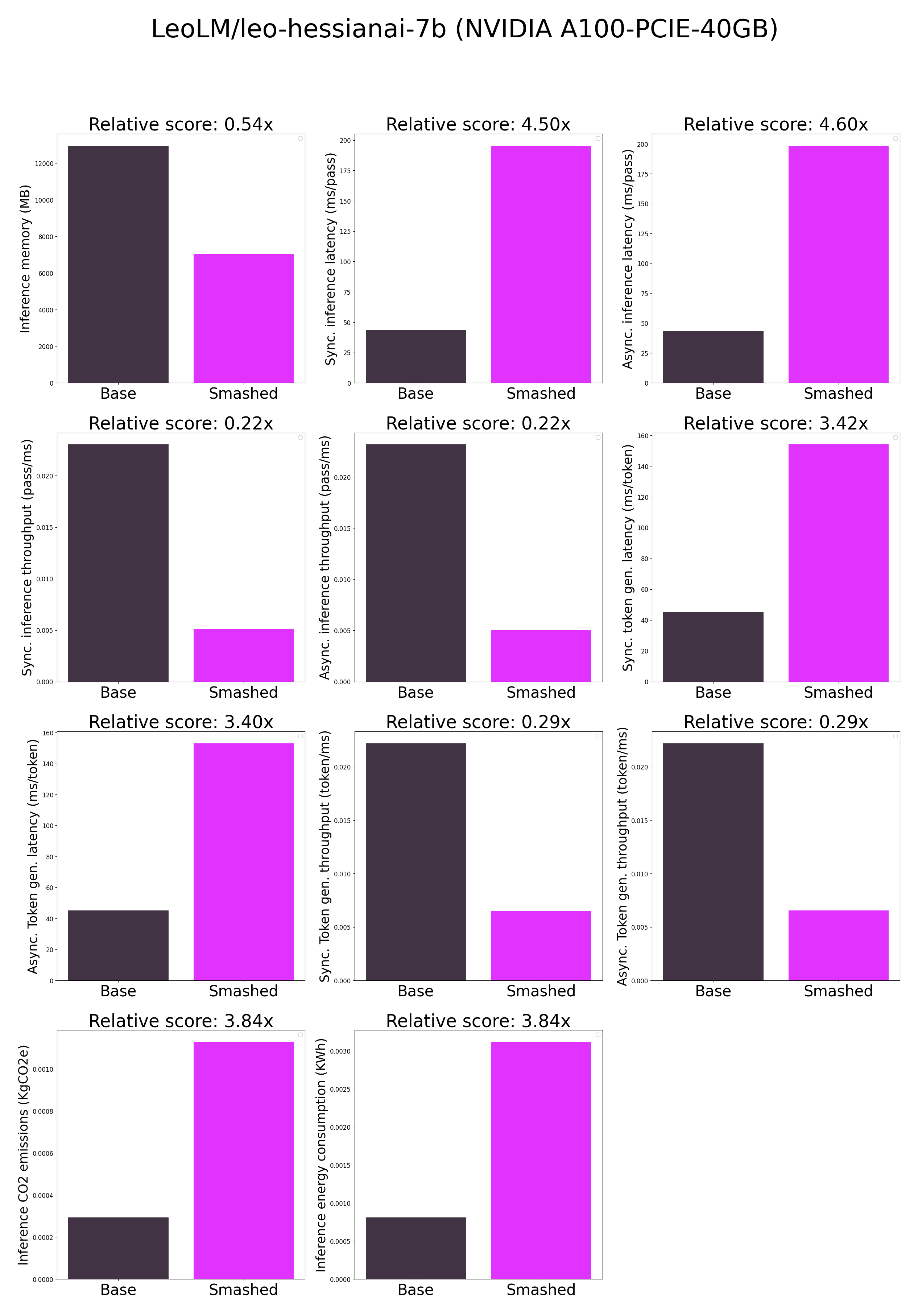
|
smash_config.json
ADDED
|
@@ -0,0 +1,27 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"api_key": null,
|
| 3 |
+
"verify_url": "http://johnrachwan.pythonanywhere.com",
|
| 4 |
+
"smash_config": {
|
| 5 |
+
"pruners": "None",
|
| 6 |
+
"factorizers": "None",
|
| 7 |
+
"quantizers": "['llm-int8']",
|
| 8 |
+
"compilers": "None",
|
| 9 |
+
"task": "text_text_generation",
|
| 10 |
+
"device": "cuda",
|
| 11 |
+
"cache_dir": "/ceph/hdd/staff/charpent/.cache/modelsch7ydyst",
|
| 12 |
+
"batch_size": 1,
|
| 13 |
+
"model_name": "LeoLM/leo-hessianai-7b",
|
| 14 |
+
"pruning_ratio": 0.0,
|
| 15 |
+
"n_quantization_bits": 8,
|
| 16 |
+
"output_deviation": 0.005,
|
| 17 |
+
"max_batch_size": 1,
|
| 18 |
+
"qtype_weight": "torch.qint8",
|
| 19 |
+
"qtype_activation": "torch.quint8",
|
| 20 |
+
"qobserver": "<class 'torch.ao.quantization.observer.MinMaxObserver'>",
|
| 21 |
+
"qscheme": "torch.per_tensor_symmetric",
|
| 22 |
+
"qconfig": "x86",
|
| 23 |
+
"group_size": 128,
|
| 24 |
+
"damp_percent": 0.1,
|
| 25 |
+
"save_load_fn": "bitsandbytes"
|
| 26 |
+
}
|
| 27 |
+
}
|