
![]()
Description
RUN KILLED. REDOING
A sort of recreation of OpenCAI with a larger dataset. Likely not very useful by itself, but might be good to add within a merge.
The unprocessed dataset is currently 10,105,611 messages.
204,476,977 tokens in chunks of 6000 tokens.
Prompt format
LLaMa-3 Instruct format. No system training. Nicknames used instead of user and assistant.
<|start_header_id|>Bob<|end_header_id|>
Hello.<|eot_id|><|start_header_id|>Joe<|end_header_id|>
Hey. How are you?<|eot_id|>
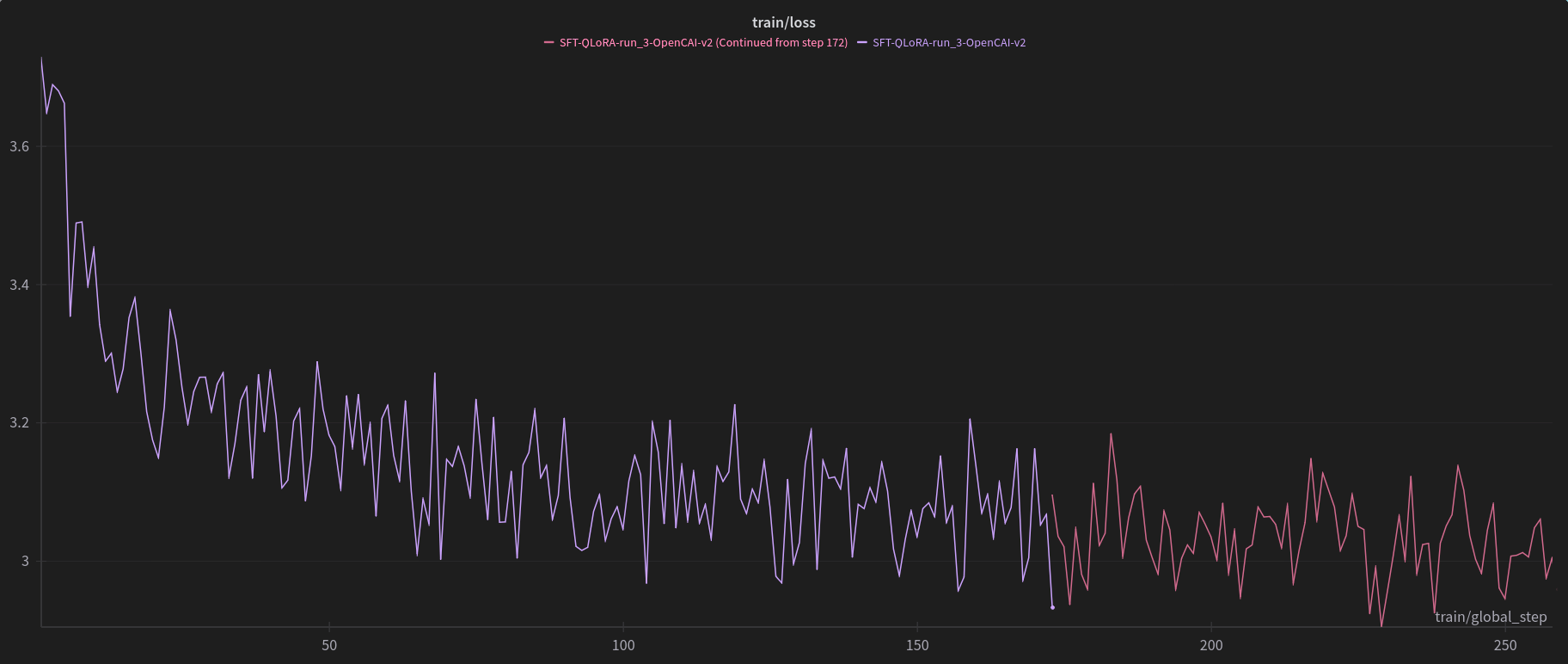
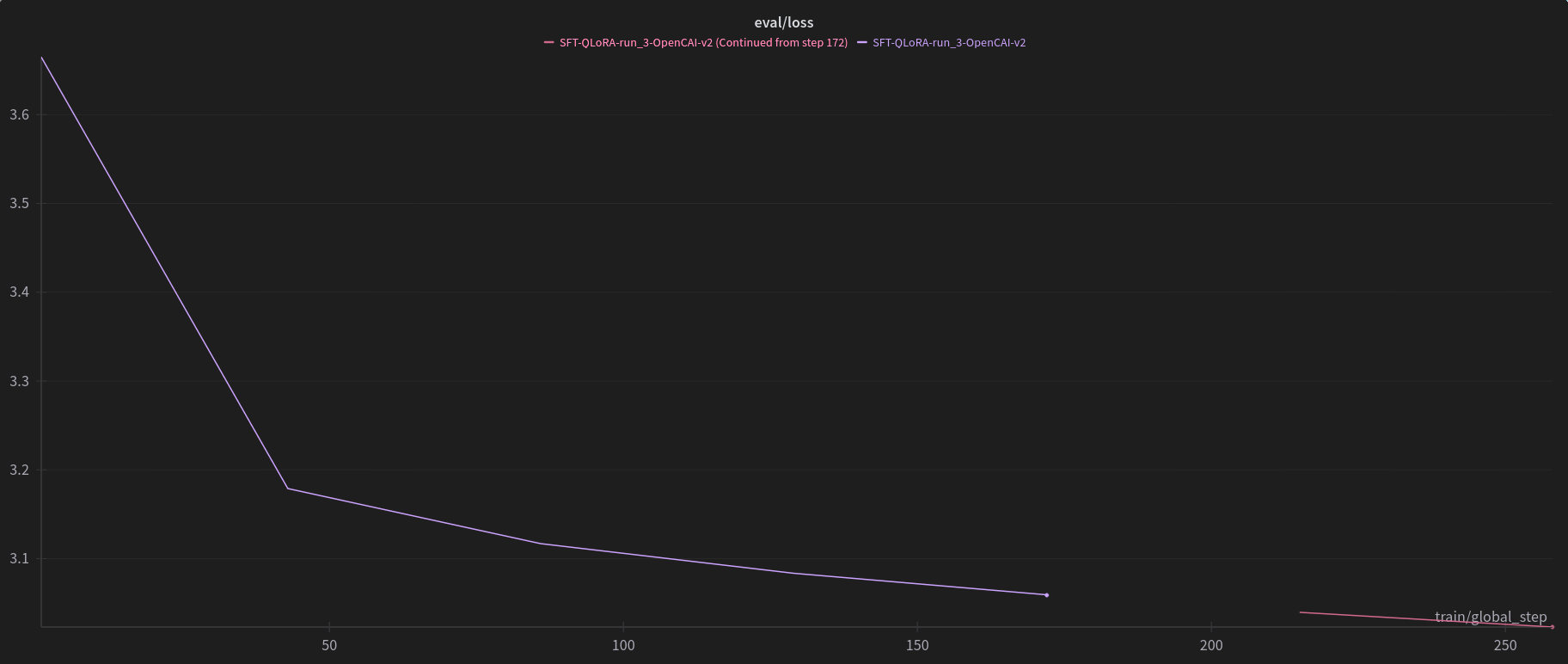
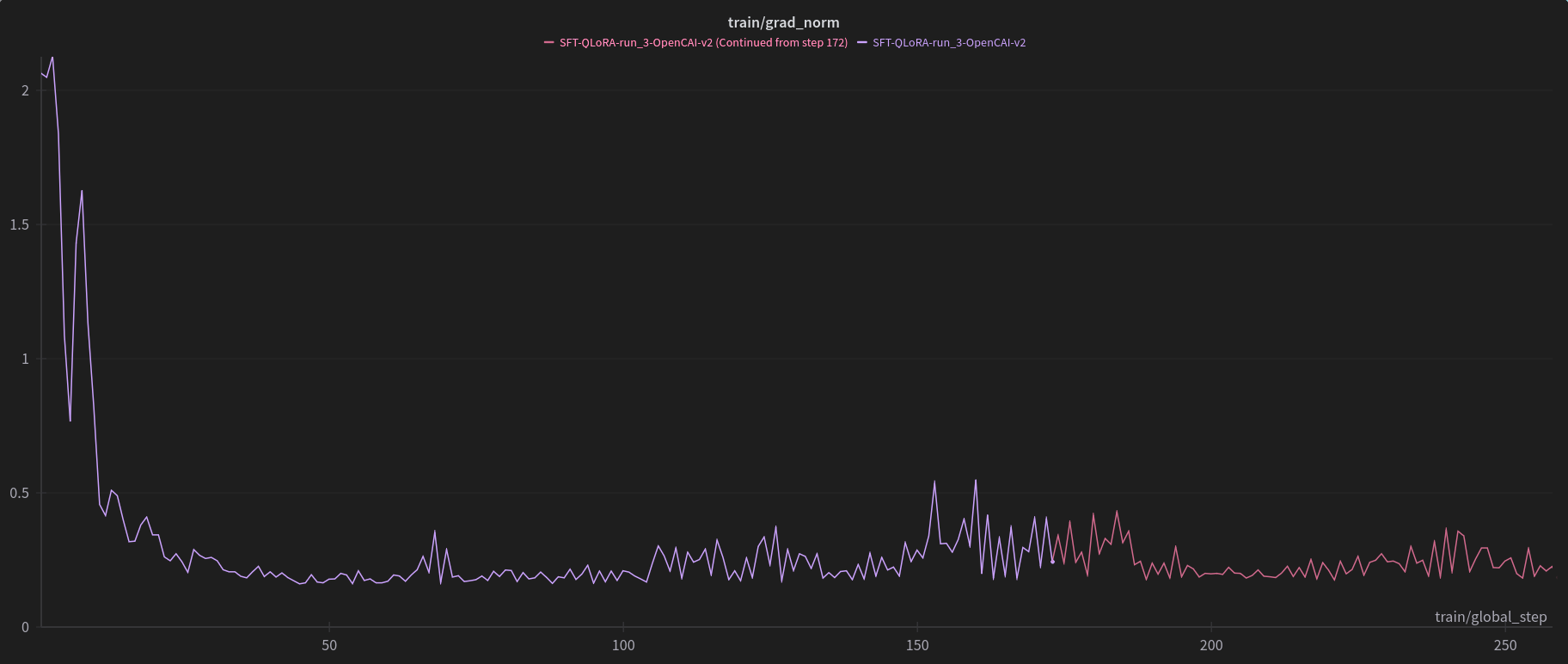
In progress training graphs
Checkpoint 258/2105
Training settings
# Weights and Biases logging config
wandb_project: L3-OpenCAI-v2-8B
wandb_entity:
wandb_watch:
wandb_name: SFT-QLoRA-run_3-OpenCAI-v2
wandb_log_model:
# Model architecture config
base_model: meta-llama/Meta-Llama-3-8B-Instruct
model_type: AutoModelForCausalLM
tokenizer_type: AutoTokenizer
# Hugging Face saving config
hub_model_id:
hub_strategy:
push_dataset_to_hub:
hf_use_auth_token:
# Model checkpointing config
output_dir: ./L3-OpenCAI-v2-run_3-SFT-8B-QLoRA
resume_from_checkpoint:
save_steps:
saves_per_epoch: 50
save_safetensors: true
save_total_limit: 3
# Mixed precision training config
bf16: true
fp16: false
tf32: false
# Model loading config
load_in_8bit: false
load_in_4bit: true
strict: false
# Sequence config
sequence_len: 6008
s2_attention: false
sample_packing: true
eval_sample_packing: true
pad_to_sequence_len: true
train_on_inputs: false
group_by_length: false
# QLoRA adapter config
adapter: qlora
lora_model_dir:
lora_r: 128
lora_alpha: 128
lora_dropout: 0.125
lora_fan_in_fan_out:
lora_target_linear:
save_embedding_layers:
peft_layers_to_transform:
peft_use_dora:
peft_use_rslora:
peft_layer_replication:
lora_target_modules:
- gate_proj
- down_proj
- up_proj
- q_proj
- v_proj
- k_proj
- o_proj
lora_modules_to_save:
# Unfrozen parameters for FFT
unfrozen_parameters:
# Dataset config
datasets:
- path: ./local_datasets/OpenCAI-v2-6000-CustomShareGPT.json
type: customllama3
val_set_size: 0.01
evaluation_strategy:
eval_steps:
evals_per_epoch: 50
test_datasets:
dataset_prepared_path: ./OpenCAI-v2-seed42-l3
shuffle_merged_datasets: true
# Training hyperparameters
num_epochs: 1
gradient_accumulation_steps: 16
micro_batch_size: 1
eval_batch_size: 1
warmup_steps: 25
optimizer: paged_adamw_8bit
lr_scheduler: cosine
learning_rate: 0.00002
loraplus_lr_ratio: 8
loraplus_lr_embedding:
cosine_min_lr_ratio: 0.1
weight_decay: 0.1
max_grad_norm: 1
logging_steps: 1
# Model optimization
gradient_checkpointing: unsloth
xformers_attention: false
flash_attention: false
sdp_attention: true
# Loss monitoring config
early_stopping_patience: false
loss_watchdog_threshold: 100.0
loss_watchdog_patience: 3
# Debug config
debug: true
seed: 42
# DeepSpeed and FSDP config
deepspeed:
fsdp:
fsdp_config:
# Token config
special_tokens:
bos_token: "<|begin_of_text|>"
eos_token: "<|end_of_text|>"
pad_token: "<|end_of_text|>"
tokens:
# Don't mess with this, it's here for accelerate and torchrun
local_rank:
Framework versions
- PEFT 0.10.0
- Downloads last month
- 2
Unable to determine this model’s pipeline type. Check the
docs
.