
InkSight Release
Collection
Hugging Face collection of InkSight
•
4 items
•
Updated
•
2
From InkSight: Offline-to-Online Handwriting Conversion by Learning to Read and Write
from huggingface_hub import from_pretrained_keras
import tensorflow_text
model = from_pretrained_keras("Derendering/InkSight-Small-p")
cf = model.signatures['serving_default']
prompt = "Derender the ink." # "Recognize and derender." or "Derender the ink: <text>"
input_text = tf.constant([prompt], dtype=tf.string)
image_encoded = tf.reshape(tf.io.encode_jpeg(np.array(image)[:, :, :3]), (1, 1))
output = cf(**{'input_text': input_text, 'image/encoded': image_encoded})
For full usage, please refer to the notebook: ![]()
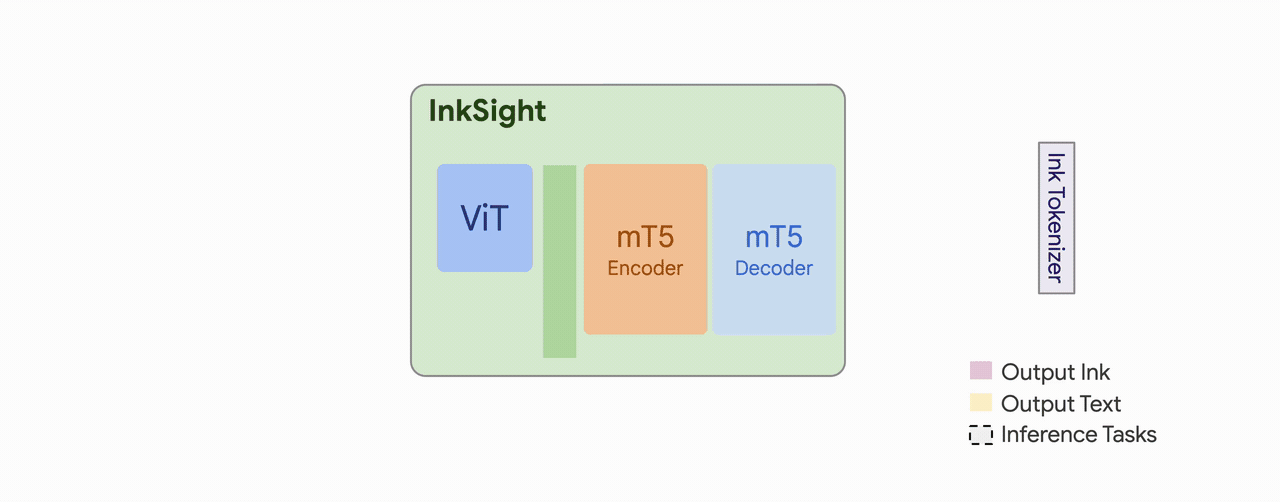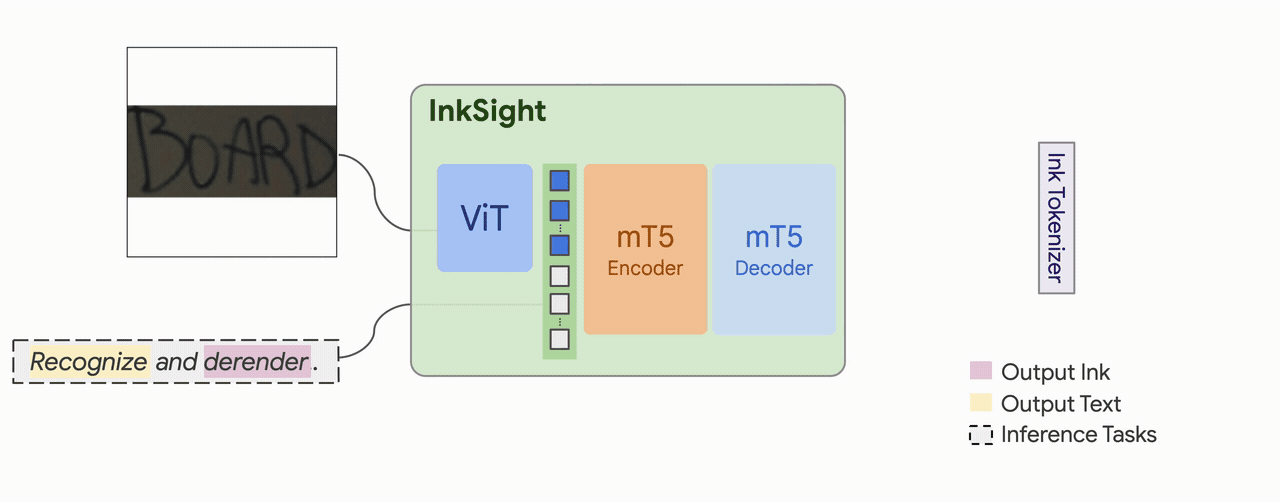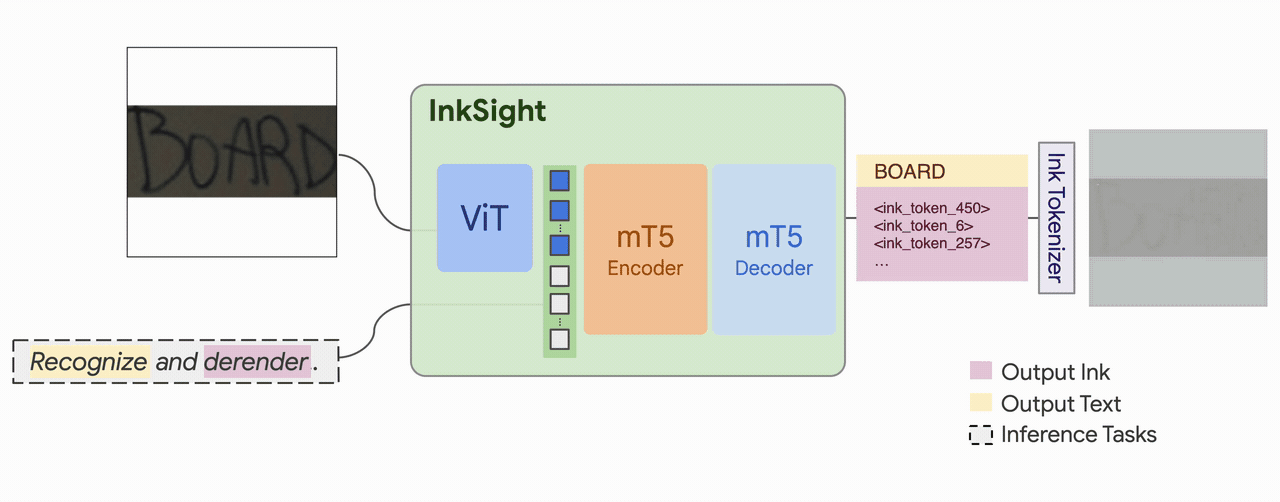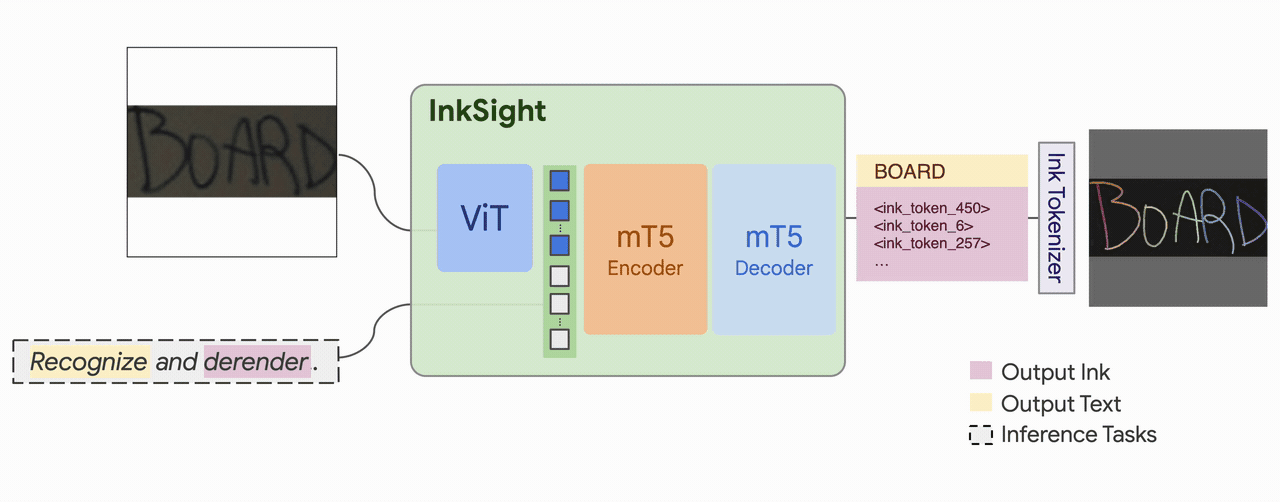
| Model Architecture | A multimodal sequence-to-sequence Transformer model with the mT5 encoder-decoder architecture. It takes text tokens and ViT dense image embeddings as inputs to an encoder and autoregressively predicts discrete text and ink tokens with a decoder. |
|---|---|
| Input(s) | A pair of image and text. |
| Output(s) | Generated digital ink and text. |
| Usage |
Application: The model is for research prototype, and the public version is released and available for the public. Known Caveats: None. |
| System Type |
System Description: This is a standalone model. Upstream Dependencies: None. Downstream Dependencies: None. |
| Implementation Frameworks |
Hardware & Software: Hardware: TPU v5e. Software: T5X , JAX/Flax, Flaxformer. Compute Requirements: We train all of our models for 340k steps with batch size 512. With frozen ViT encoders, the training of Small-i takes ∼33h on 64 TPU v5e chips and the training of Large-i takes ∼105h on 64 TPU v5e chips. |
| Data Overview | Training Datasets: The ViT encoder of Small-p is pretrained on ImageNet-21k, mT5 encoder and decoder are initialized from scratch. The entire model is trained on the mixture of publicly available datasets described in next section. |
| Evaluation Results | Evaluation Methods: Human evaluation (reported in Section 4.5.1 of the paper) and automated evaluations (reported in Section 4.5.2 of the paper). |
| Model Usage & Limitations |
Sensitive Use: The model is capable of converting images to digital inks. This model should not be used for any of the privacy-intruding use cases, e.g., forging handwritings. Known Limitations: Reported in Appendix I of the paper. Ethical Considerations & Potential Societal Consequences: Reported in Sections 6.1 and 6.2 of the paper. |
If you find our work useful for your research and applications, please cite using this BibTeX:
@article{mitrevski2024inksight,
title={InkSight: Offline-to-Online Handwriting Conversion by Learning to Read and Write},
author={Mitrevski, Blagoj and Rak, Arina and Schnitzler, Julian and Li, Chengkun and Maksai, Andrii and Berent, Jesse and Musat, Claudiu},
journal={arXiv preprint arXiv:2402.05804},
year={2024}
}