
animeGender-dvgg-0.8
A cutting edge lightweight model set for animation characters' gender classification.
Updated info: This model is an update, as well as an advanced version of our previous classificational model animeGender-dvgg-0.7, with new features and capabilities described below.
Description
Our proposal model, animeGender-dvgg-0.8, which is a binary classification model created by DOF-Studio (2023) and based on a famous structure named resnet (while in the previous version, we used vgg structure), aims to identify the gender, or sex of a particular animation character (particularly designed for Japanese-style 2D anime characters). It is trained by DOF-Studio in July, 2023, on an expanded organizational private dataset that is manually collected and tagged by our staff. In our previous tests, this version of the animeGender model series have shown an unprecedentedly unimpeachable and charming result of our test, verification, even one deliberately designed stress test dataset.
Please note although that this model is still not the final version of our character-gender identification model series, it is only a phased result (Version 0.8) of our open-source project, which means upgraded versions will be soon released by our team in the near future, and we are confident to tell that as we are aiming to create a more sophisticated and intelligent network structure on the performance of versatility and functionality, rather than merely pursuing the precision result, so there is still going to be an improvement in the up-coming ones. Thank you for all of your appreciation and support for our work and models.
Important Features
Gargantuan Improvement On Precision: An overall 96%+ precision on an external validation dataset, consisting of around 56'000 samples of anime characters that are graphically Similar in style with the training dataset. An overall 94%+ precision on an extremely designed stress test dataset, consisting of around 1'200 samples of anime characters that are completely different in style and their genders are hard (but still able) to be identified by nake eyes. We firmly believe that this model, powered by magnificent precision with a strong generalization ability, has achieved top ranks among the open-source models, at least on mainstream platforms.
Output with Certainty: Unlike other gender-detective models, especially those with a CONFUSE as one of possible outputs, our models, or, saying that the whole serie of our animeGender models, DO NOT, and WILL NEVER output a vague tag like a CONFUSE, or UNKNOWN. Given that sometimes characters' gender may be actually vague to nake eyes, we will deprecate all of those that genders can not be defined in our training set. Hence, the result of our models show a probability, or saying, a tendency, that a particular gender of a character could have been, merely by the given image, but without any underlying information that could have in a certain background setting.
No Secondary Sexual Characteristics (SSE) Needed: Our models use a completely facial image to identify a character's gender, and only a head, or a face including some hair, is what the input to our models should be. So, when using this series, a full body is not needed, and particularly, please merely use a head instead. Given that most illustrative images naturally have observable characteristics for gender indication, so, we do not use Secondary Sexual Characteristics to interfere, but only facial features.
Transgressivability Technique: We use a brand new technique invented by our team to manually control the training process, in order to ameliorate the over-fitting and improve the overall performance at the same time. This technique can be basically comprehended as a tool to intelligently help the training system to identify the ourliers in our samples, and try to attach it with a lower weight to adjust the gradients when training. Obviously, it has an perceptible improvement on the performance of our proposal models, and compared to the control group, it has at least led to a 1.5% improvement on precision, and 2.0 points on generaliability.
Versatility On Illustrations: In comparison to our last generation, this version, animeGender-dvgg-0.8 has been trained and tuned on an varified training dataset, consisting of a more varified styles, gestures, and quality of illustrations, and correspondingly, is also capable to identify the gender for more characters illustrated with different presentations. Please note that it is still merely designed to identify Japanese animation characters, the performance on line art, real images, and 3D characters is not guaranteed.
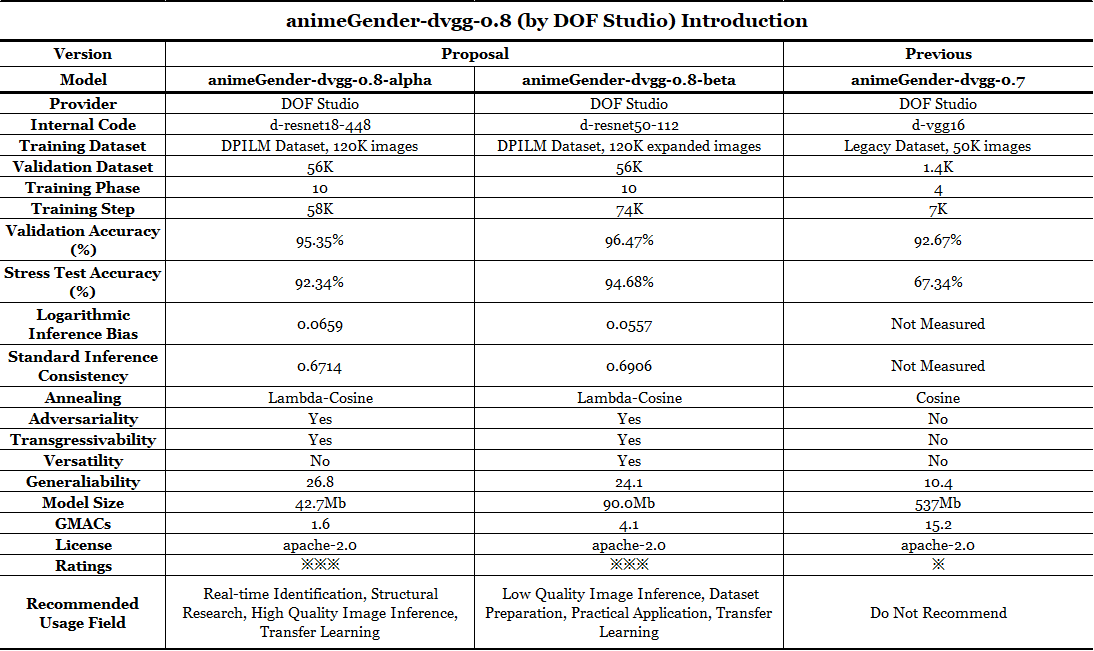
Multiple Choices: Different from the previous version, for this generation, we have silumtaneously released two different types of this animeGender-dvgg-0.8 model series, namely animeGender-dvgg-0.8-alpha and animeGender-dvgg-0.8-beta. Differences are shown in the first chart below and they are generally designed for varied use. Please note that in the future, we are going to structure a specially designed model rather than using the extant model structures, and hopefully to achieve a advanced performance. When it comes to the model selecting creterion, here's a reference that gives some advice:
Technical Details
Modification: This model, animeGender-dvgg-0.8, based on resnet structures, has been modified with the last sequantials, saying the dense layers, which means we have modified it into a binary classification model with two nodes outputing the possibility of each gender, namely female, and male.
Input: Just like the original design of resnet, which has been designed with an input with 224 * 224 in terms of resolution, and 3 dementions in RGB colorspace, in our model animeGender-dvgg-0.7, we aim to use the same dimensions (224 * 224, in three channels). Please note when feeding a picture into the model, please ensure that the input illustration only consists of the head and face of the character you want to identify, in order to make the result from the model most precise and reliable.
Output: This model, animeGender-dvgg-0.8, has an original output with a one-dim tensor, which length is 2, respectively shows the possibilities of each result of your input, namely female and male. In our open source usage example, see in the file folder, we have conveniently transformed the raw output into a readable result, for example, "male", with a numerical number showing the possibility, or the confidence. Note that our model does not have the background knowledge of a certain character, or the context of an animation, so some gender-neutral characters may still be misclassified, or correctly matched but with a confidence that is around 0.5.
Checkpoint: We have provided all of those two kinds of models taged as "alpha" and "beta"each in three types: ".safetensors" for Pytorch, ".onnx" for implementation, and ".pb" for keras. You can directly download a certain one you are interested in and the script file "use.py" to interfere, without the necessity to fully clone this repo. Due to the massive generated phased checkpoints while training, we do no provide other checkpoints that have inferior performance than the proposed ones.
Results and Rankings
- Here is a comprehensive table depicting the results and rankings of our model.

Examples
Here are some sample-exteral tests that are conducted by our staff with the corresponding results shown below. Note that we use the same legacy demonstration set as we did in the previous version to show the performance and output of out model, and here is a graph illustrating it.

Here is a consice graph showing the performance of different models, including those that are proposed in this repo, and that from a previous version 0.7.

Note that when you normally use this model, the performance basically lies in the range of our Stress Test and Validation.
Usage
We have uploaded the usage with Python in the file folder, and please note you should download them and run locally using either your CPU or with CUDA.
In the script provided with a name "use.py", you can operate it on your own device by changing the model filepath and image filepath. The script supports CPU and CUDA inference, and to switch between two methods, you can simply change a bool variable when loading the model.
Note that only the provided codes can be regarded as the only recommended approach to use this model, while other ways including those are automatically shown on this website are not guaranteed to be valid and user-friendly.
Limitations
The styles this model is good at are still in a limited range, which are almost confined to modern Japanese-styled illustrations, while lineart, American animations are not supported. But please note, although we are aiming at improving the versatility of this series of model, we have NEVER planned to included American, or Koeran styled animation illustrations into our training set, yet only concentrating on things we are doing now. But it might be a chance for anyone of you who is interested in to finetune your own model that is for your requirement, e.g., a specific style.
The precision of our models are related with the image you feed in, which not only means the quality, but especially the proportion of the face in an image. We presume that everyone do not care other information but only the details from faces of characters and did so in our work, hense, in order to maintain a high performance when using our models, we would highly recommend that AT LEAST 80% of the squared image should be a whole face of the character, and otherwise, the performace is not guaranteed if the face is too small to contain enough detail for models to identify.
Due to the lack of sources of male characters, the precision of males are slightly lower than that of females. But we are working on it to find approaches to solve this problem in future versions.
Notifications
We confidently claim that all data we trained on were from real-human illustrations, but our model is also suitable for generative graphs, for example, those generated from stable diffusion, with a relatively high accuracy correspondingly.
We confidently claim that all model related files EXCEPT this README.md file will NEVER be changed ever since the initial release, so please follow and like us to chase an updated version.
New models supremely capable of this task has already been officially released by our team, and please refer links shown below:
Version 0.9 is coming soon! Please see: https://huggingface.co/DOFOFFICIAL/animeGender-dvgg-0.9.
Yours,
Team DOF Studio, August 1st, 2023.
- Downloads last month
- 0