
Adapting Large Language Models via Reading Comprehension
This repo contains the model for our paper Adapting Large Language Models via Reading Comprehension
We explore continued pre-training on domain-specific corpora for large language models. While this approach enriches LLMs with domain knowledge, it significantly hurts their prompting ability for question answering. Inspired by human learning via reading comprehension, we propose a simple method to transform large-scale pre-training corpora into reading comprehension texts, consistently improving prompting performance across tasks in biomedicine, finance, and law domains. Our 7B model competes with much larger domain-specific models like BloombergGPT-50B. Moreover, our domain-specific reading comprehension texts enhance model performance even on general benchmarks, indicating potential for developing a general LLM across more domains.
GitHub repo:
https://github.com/microsoft/LMOps
Domain-specific LLMs:
Our models of different domains are now available in Huggingface: Biomedicine-LLM, Finance-LLM and Law-LLM, the performances of our AdaptLLM compared to other domain-specific LLMs are:
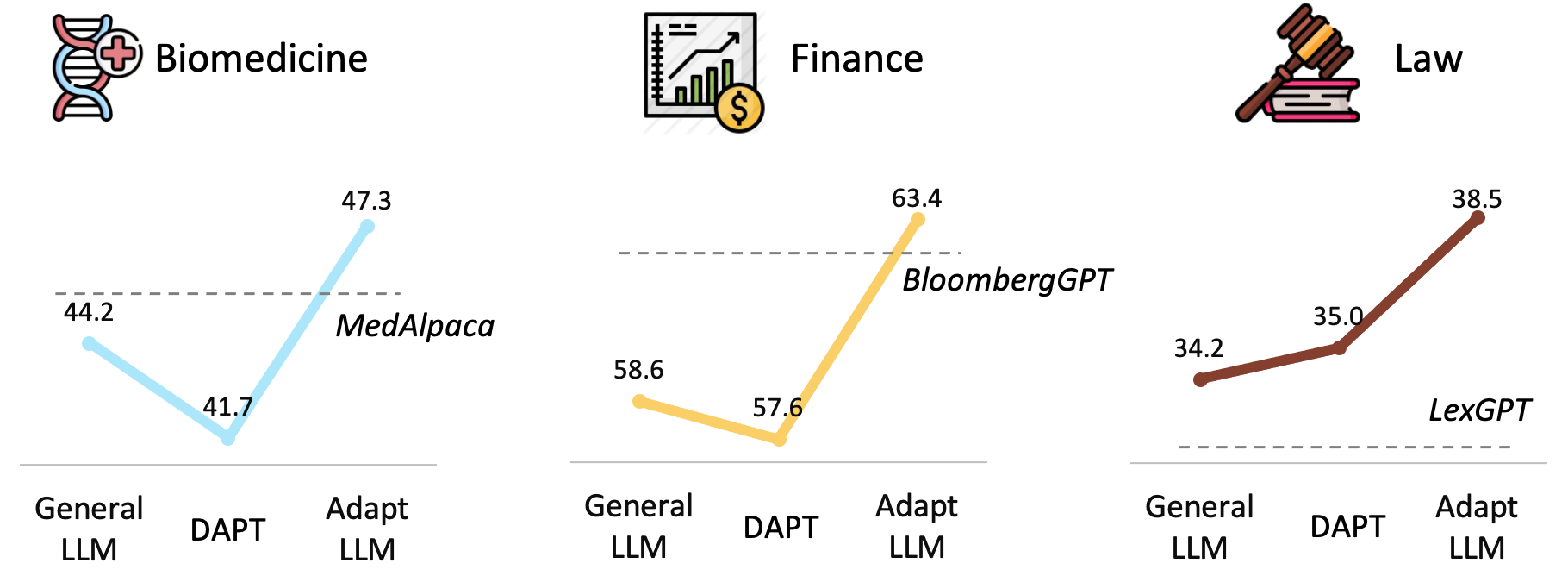
Domain-specific Tasks:
To easily reproduce our results, we have uploaded the filled-in zero/few-shot input instructions and output completions of each domain-specific task: biomedicine-tasks, finance-tasks, and law-tasks.
Citation:
@inproceedings{AdaptLLM,
title={Adapting Large Language Models via Reading Comprehension},
author={Daixuan Cheng and Shaohan Huang and Furu Wei},
url={https://arxiv.org/abs/2309.09530},
year={2023},
}