
update readme
Browse files- README.md +30 -0
- comparison.png +0 -0
README.md
ADDED
|
@@ -0,0 +1,30 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Adapting Large Language Models via Reading Comprehension
|
| 2 |
+
|
| 3 |
+
This repo contains the model for our paper [Adapting Large Language Models via Reading Comprehension](https://arxiv.org/pdf/2309.09530.pdf)
|
| 4 |
+
|
| 5 |
+
We explore **continued pre-training on domain-specific corpora** for large language models. While this approach enriches LLMs with domain knowledge, it significantly hurts their prompting ability for question answering. Inspired by human learning via reading comprehension, we propose a simple method to **transform large-scale pre-training corpora into reading comprehension texts**, consistently improving prompting performance across tasks in **biomedicine, finance, and law domains**. Our 7B model competes with much larger domain-specific models like BloombergGPT-50B. Moreover, our domain-specific reading comprehension texts enhance model performance even on general benchmarks, indicating potential for developing a general LLM across more domains.
|
| 6 |
+
|
| 7 |
+
## GitHub repo:
|
| 8 |
+
https://github.com/microsoft/LMOps
|
| 9 |
+
|
| 10 |
+
## Domain-specific LLMs:
|
| 11 |
+
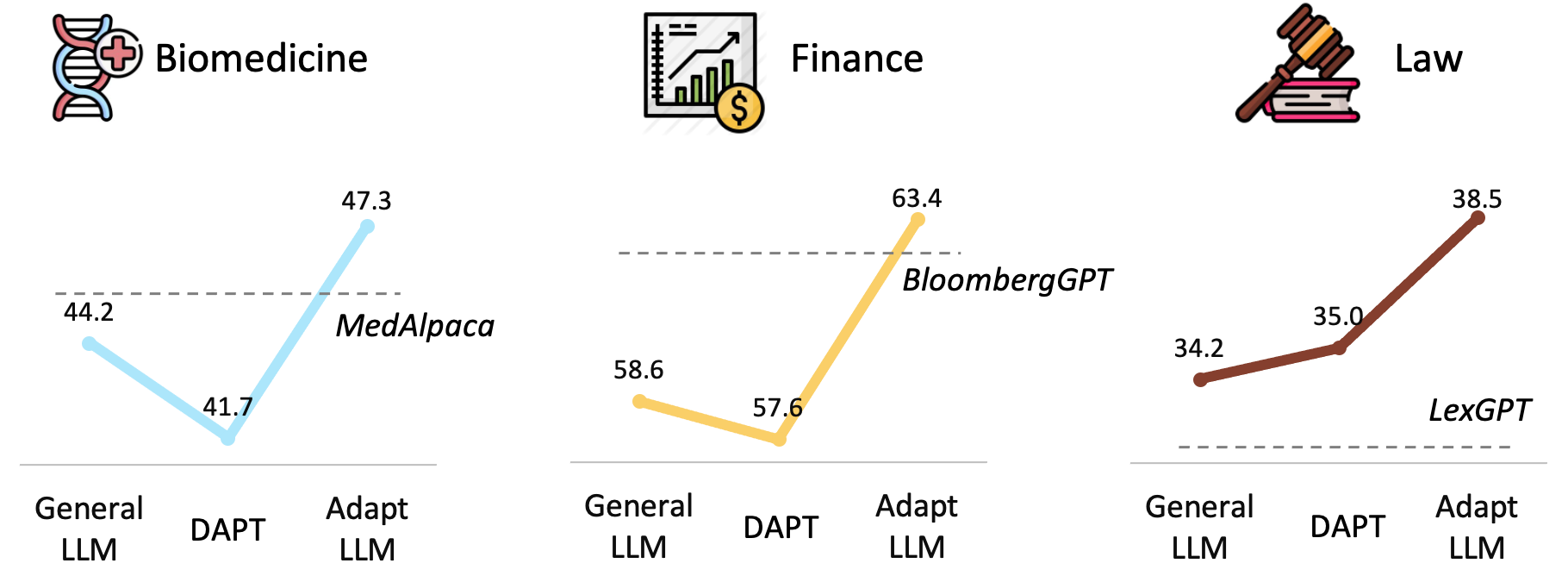
Our models of different domains are now available in Huggingface: [Biomedicine-LLM](https://huggingface.co/AdaptLLM/medicine-LLM), [Finance-LLM](https://huggingface.co/AdaptLLM/finance-LLM) and [Law-LLM](https://huggingface.co/AdaptLLM/law-LLM), the performances of our AdaptLLM compared to other domain-specific LLMs are:
|
| 12 |
+
|
| 13 |
+
<p align='center'>
|
| 14 |
+
<img src="./comparison.png" width="700">
|
| 15 |
+
</p>
|
| 16 |
+
|
| 17 |
+
## Domain-specific Tasks:
|
| 18 |
+
To easily reproduce our results, we have uploaded the filled-in zero/few-shot input instructions and output completions of each domain-specific task: [biomedicine-tasks](https://huggingface.co/datasets/AdaptLLM/medicine-tasks), [finance-tasks](https://huggingface.co/datasets/AdaptLLM/finance-tasks), and [law-tasks](https://huggingface.co/datasets/AdaptLLM/law-tasks).
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
## Citation:
|
| 22 |
+
```bibtex
|
| 23 |
+
@inproceedings{AdaptLLM,
|
| 24 |
+
title={Adapting Large Language Models via Reading Comprehension},
|
| 25 |
+
author={Daixuan Cheng and Shaohan Huang and Furu Wei},
|
| 26 |
+
url={https://arxiv.org/abs/2309.09530},
|
| 27 |
+
year={2023},
|
| 28 |
+
}
|
| 29 |
+
```
|
| 30 |
+
|
comparison.png
ADDED
|