
![]()
![]()
EEVE-Korean-2.8B-v1.0
Join Our Community on Discord!
If you're passionate about the field of Large Language Models and wish to exchange knowledge and insights, we warmly invite you to join our Discord server. It's worth noting that Korean is the primary language used in this server. The landscape of LLM is evolving rapidly, and without active sharing, our collective knowledge risks becoming outdated swiftly. Let's collaborate and drive greater impact together! Join us here: Discord Link.
Our Dedicated Team (Alphabetical Order)
| Research | Engineering | Product Management | UX Design |
|---|---|---|---|
| Myeongho Jeong | Geon Kim | Bokyung Huh | Eunsue Choi |
| Seungduk Kim | Rifqi Alfi | ||
| Seungtaek Choi | Sanghoon Han | ||
| Suhyun Kang |
About the Model
This model is a Korean vocabulary-extended version of microsoft/phi-2, specifically fine-tuned on various Korean web-crawled datasets available on HuggingFace. Our approach was to expand the model's understanding of Korean by pre-training the embeddings for new tokens and partially fine-tuning the lm_head embeddings for the already existing tokens while preserving the original parameters of the base model.
Technical Deep Dive
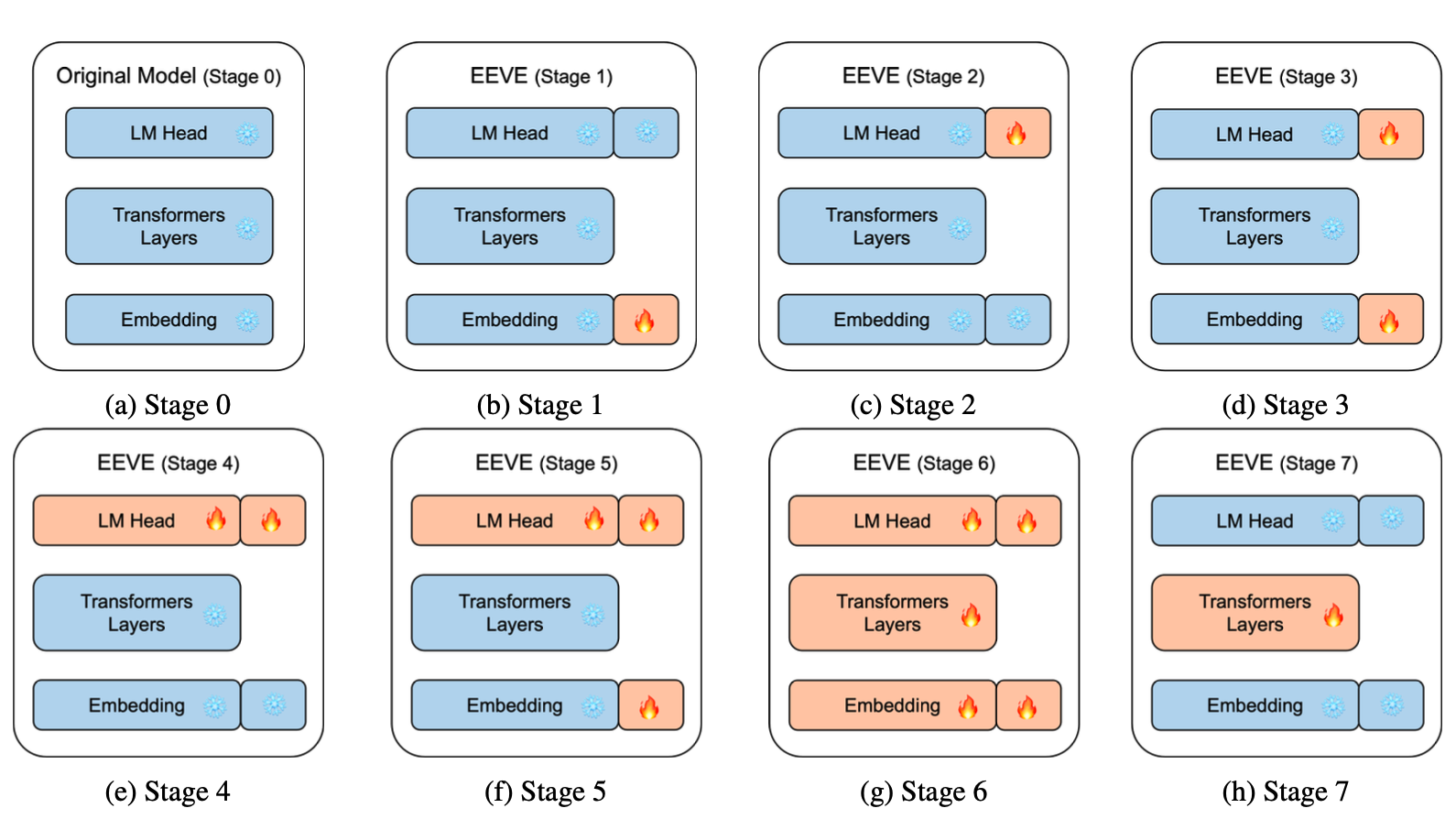
To adapt foundational models from English to Korean, we use subword-based embedding with a seven-stage training process involving parameter freezing. This approach progressively trains from input embeddings to full parameters, efficiently extending the model's vocabulary to include Korean. Our method enhances the model's cross-linguistic applicability by carefully integrating new linguistic tokens, focusing on causal language modeling pre-training. We leverage the inherent capabilities of foundational models trained on English to efficiently transfer knowledge and reasoning to Korean, optimizing the adaptation process.
For more details, please refer to our technical report: Efficient and Effective Vocabulary Expansion Towards Multilingual Large Language Models.
Here’s an simplified code for our key approach:
# number_of_old_tokens is the size of tokenizer before vocab extension. For example, in case of EEVE-Korean-10.8B-v1.0, number_of_old_tokens is 32000.
def freeze_partial_embedding_hook(grad):
grad[:number_of_old_tokens] = 0
return grad
for name, param in model.named_parameters():
if ("lm_head" in name or "embed_tokens" in name) and "original" not in name:
param.requires_grad = True
if "embed_tokens" in name:
param.register_hook(freeze_partial_embedding_hook)
else:
param.requires_grad = False
Usage and Limitations
Keep in mind that this model hasn't been fine-tuned with instruction-based training. While it excels in Korean language tasks, we advise careful consideration and further training for specific applications.
Training Details
Our model’s training was comprehensive and diverse:
Vocabulary Expansion: We meticulously selected 8,960 Korean tokens based on their frequency in our Korean web corpus. This process involved multiple rounds of tokenizer training, manual curation, and token frequency analysis, ensuring a rich and relevant vocabulary for our model.
Initial Tokenizer Training: We trained an intermediate tokenizer on a Korean web corpus, with a vocabulary of 40,000 tokens.
Extraction of New Korean Tokens: From the intermediate tokenizer, we identified all Korean tokens not present in the original SOLAR's tokenizer.
Manual Tokenizer Construction: We then built the target tokenizer, focusing on these new Korean tokens.
Frequency Analysis: Using the target tokenizer, we processed a 100GB Korean corpus to count each token's frequency.
Refinement of Token List: We removed tokens appearing less than 6,000 times, ensuring to secure enough tokens to train models later.
Inclusion of Single-Letter Characters: Counted missing Korean single-letter characters and added them to the target tokenizer that appeared more than 6,000 times.
Iterative Refinement: We repeated steps 2 to 6 until there were no tokens to drop or add.
Training Bias Towards New Tokens: Our training data was biased to include more texts with new tokens, for effective learning.
This rigorous approach ensured a comprehensive and contextually rich Korean vocabulary for the model.
Citation
@misc{kim2024efficient,
title={Efficient and Effective Vocabulary Expansion Towards Multilingual Large Language Models},
author={Seungduk Kim and Seungtaek Choi and Myeongho Jeong},
year={2024},
eprint={2402.14714},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
- Downloads last month
- 1,127