
🌐 WiNGPT-Babel
WiNGPT-Babel(巴别塔)是一个基于大语言模型(LLM)为翻译应用定制的模型,致力于提供便捷的多语言信息母语级体验。
和其他机器翻译模型最大的不同是,WiNGPT-Babel 是采用 human-in-the-loop 数据生产采集闭环策略训练而成。因此 WiNGPT-Babel 更适应真实使用场景,例如新闻、研究成果以及观看带有实时翻译字幕的视频。通过一系列的工具插件 WiNGPT-Babel 会将这些内容翻译成用户的母语,以更好的体验呈现在用户面前。
我们的目标是利用先进的 LLM 技术,降低语言障碍,帮助用户更轻松地获取全球范围内的互联网信息,包括学术论文、社交媒体、网页内容和视频字幕等各种数据格式。虽然实现这一目标还需要时间,但 LLM 技术的发展为其提供了可能性。
✨ 核心特点
- human-in-the-loop 🌱: 首先,使用少量数据进行初步训练;然后,通过API收集我们使用各种工具的日志数据,并利用这些日志构建新的训练数据。使用WiNGPT-2.6 模型和奖励模型对这些数据进行rejection sampling,并辅以人工审核以确保数据质量。经过几轮迭代训练,模型性能将逐步提升,直至达到预期水平停止。
- 多格式翻译 📄 🌐 🎬: 支持多种文本格式的翻译,包括网页、社交媒体内容、学术论文、视频字幕、以及数据集等。
- 高精度翻译 🧠: 基于先进的 LLM 架构,我们致力于提供准确、自然、流畅的翻译结果。
- 高性能翻译 ⏱️: 采用1.5B模型,支持实时字幕翻译等应用场景,满足用户对实时翻译的需求。
- 多语言支持 🗣️: 目前支持超过 20 种语言,并不断扩展语言支持范围。
- 应用适配 🪒: 目前已适配的工具有:沉浸式翻译、videolingo。
🧪 适用场景
- 🌐 网页内容翻译: 适用于日常网页浏览,快速理解网页信息
- 📄 学术论文翻译: 适用于辅助理解多语言研究论文,提高阅读效率
- 📰 新闻资讯翻译: 适用于快速了解全球新闻动态,获取一手信息
- 🎬 视频字幕翻译: 适用于观看外语视频,辅助理解视频内容
- 📊 数据集多语言处理: 适用于多语言数据集的初步翻译,辅助数据分析
🔤 语言支持(更多语言待验证)
🇺🇸 English ↔️ 🇨🇳 Chinese | 🇯🇵 Japanese ➡️ 🇨🇳 Chinese
🚀 快速开始
WiNGPT-Babel 采用 Qwen2.5-1.5B 作为基础模型 ,是在测试比较了各种参数规模模型平衡推理速度和翻译质量的选择。在各种应用场景下的翻译速度可以达到甚至超过谷歌翻译,这样的体验对于使用翻译模型来说是至关重要的。 为了帮助大家快速上手,我们提供了以下示例,并使用 Hugging Face Transformers 库进行加载和推理,当然推荐大家使用vllm、llama.cpp、ollama等推理工具或框架:
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "WiNGPT/WiNGPT-Babel"
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained(model_name)
prompt = "Give me a short introduction to large language model."
messages = [
{"role": "system", "content": "中英互译下面的内容"},
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
generated_ids = model.generate(
**model_inputs,
max_new_tokens=4096
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
快速使用 llama.cpp 推理示例
llama-cli -m WiNGPT-Babel-Q4_K_M.gguf -co -i -if -p "<|im_start|>system\n中英互译下面的内容<|im_end|>\n" --in-prefix "<|im_start|>user\n" --in-suffix "<|im_end|>\n<|im_start|>assistant\n" -fa -ngl 80 -n 512
- 注意: WiNGPT-Babel 默认系统提示词仅为:“中英互译下面的内容”。模型会自动根据用户的输入翻译成对应的语言,无需其他复杂的指令。支持的最大长度8192,且具备多轮对话的能力。
🎬 示例
以下是一些应用场景示例,展示如何使用模型进行翻译。
- 网页翻译:
- 场景: 用户通过工具及简单系统提示,将外文网页内容翻译成母语。
- 工具: 沉浸式翻译
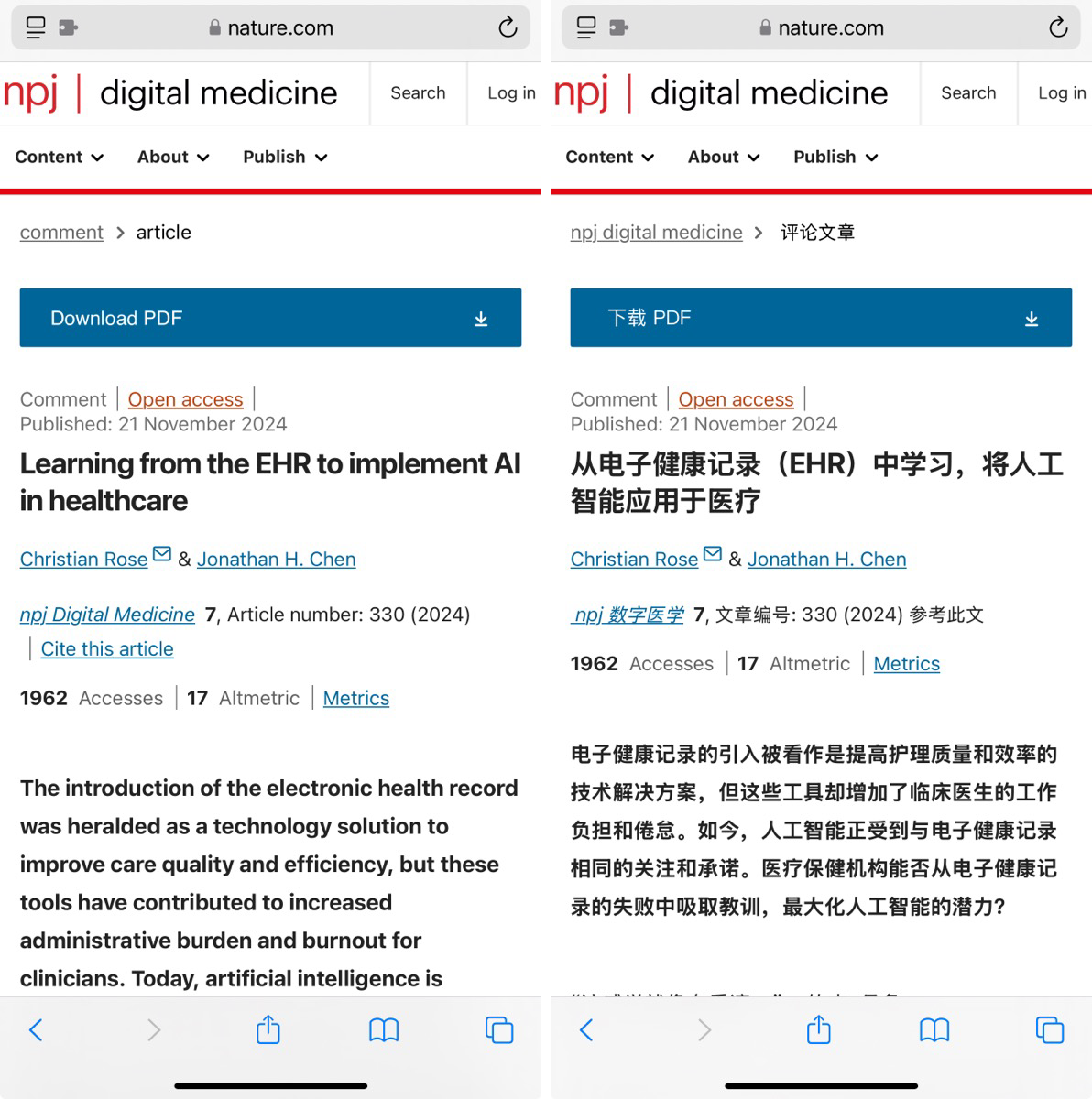

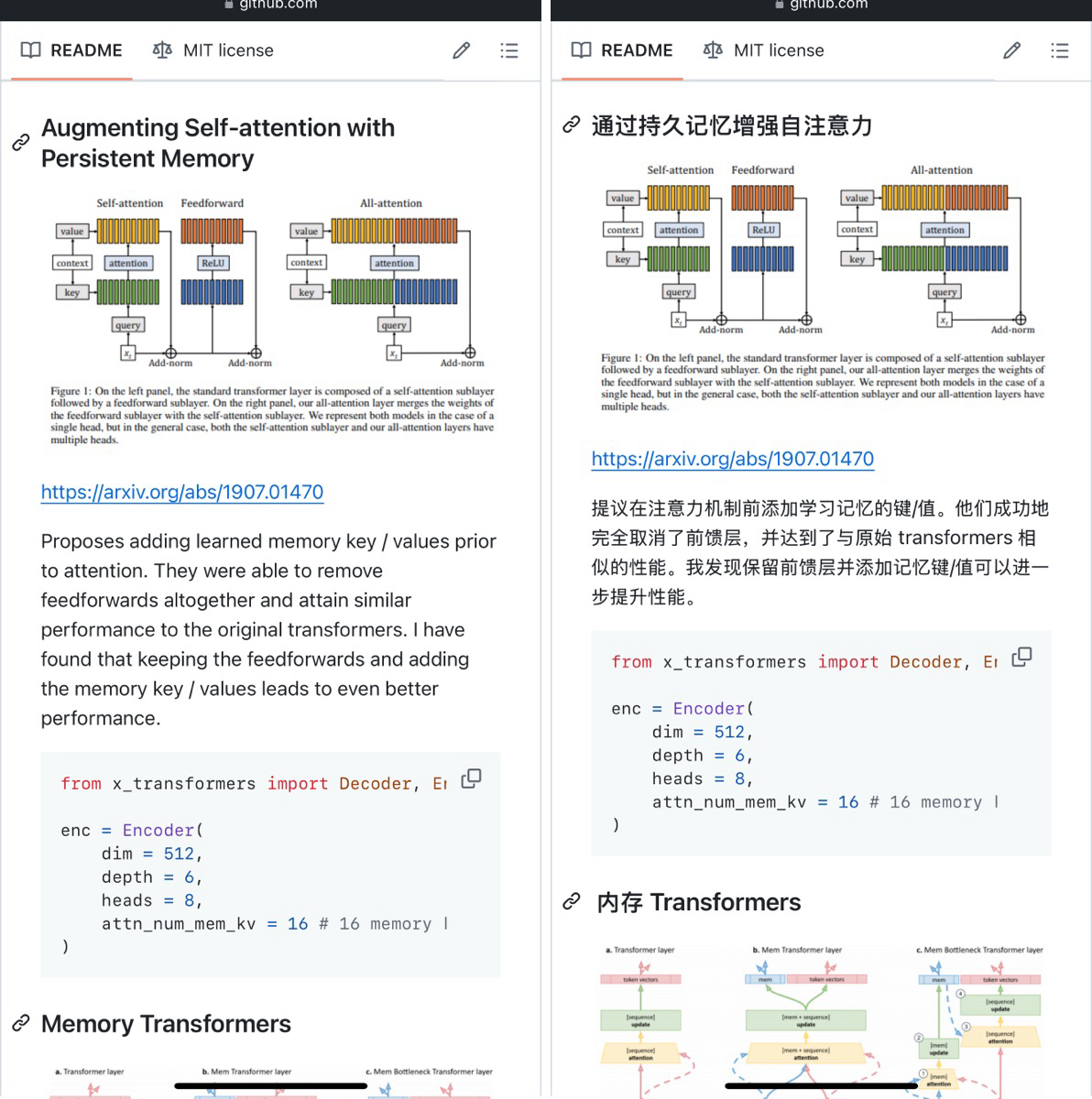

- 学术论文翻译:
- 场景: 用户使用工具翻译外文研究论文,辅助研究工作。
- 工具: 沉浸式翻译
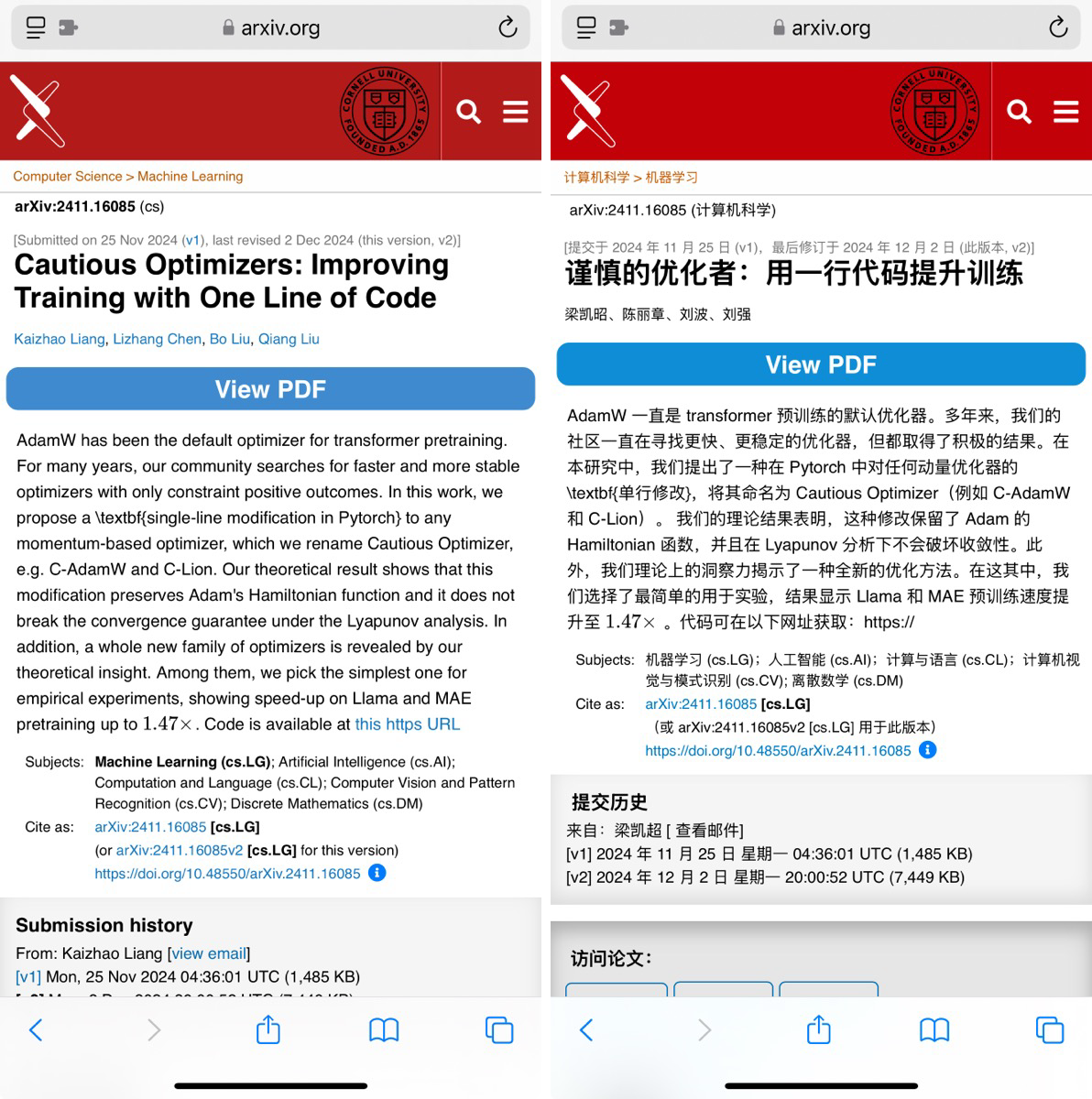
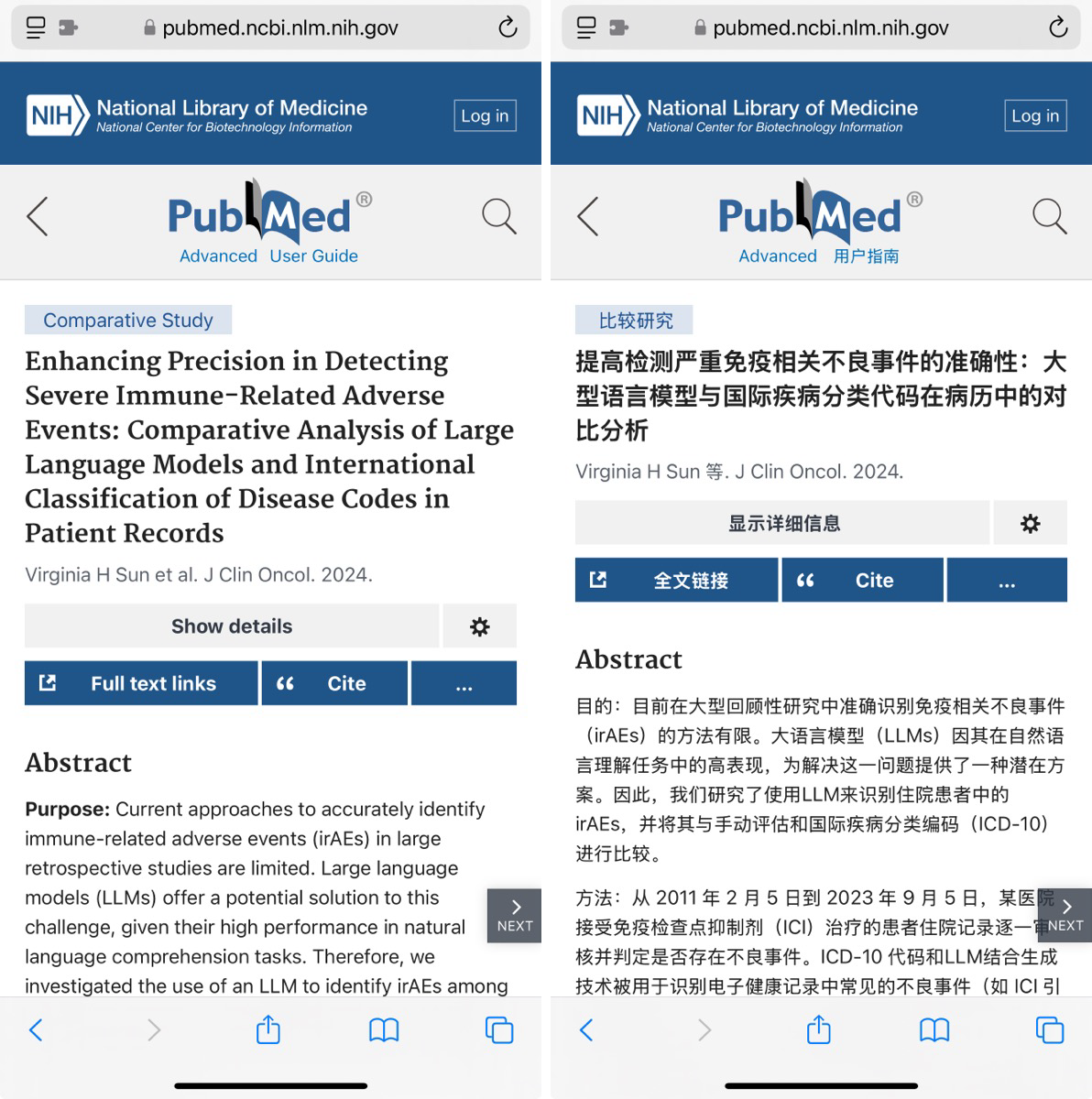
- 社交媒体翻译:
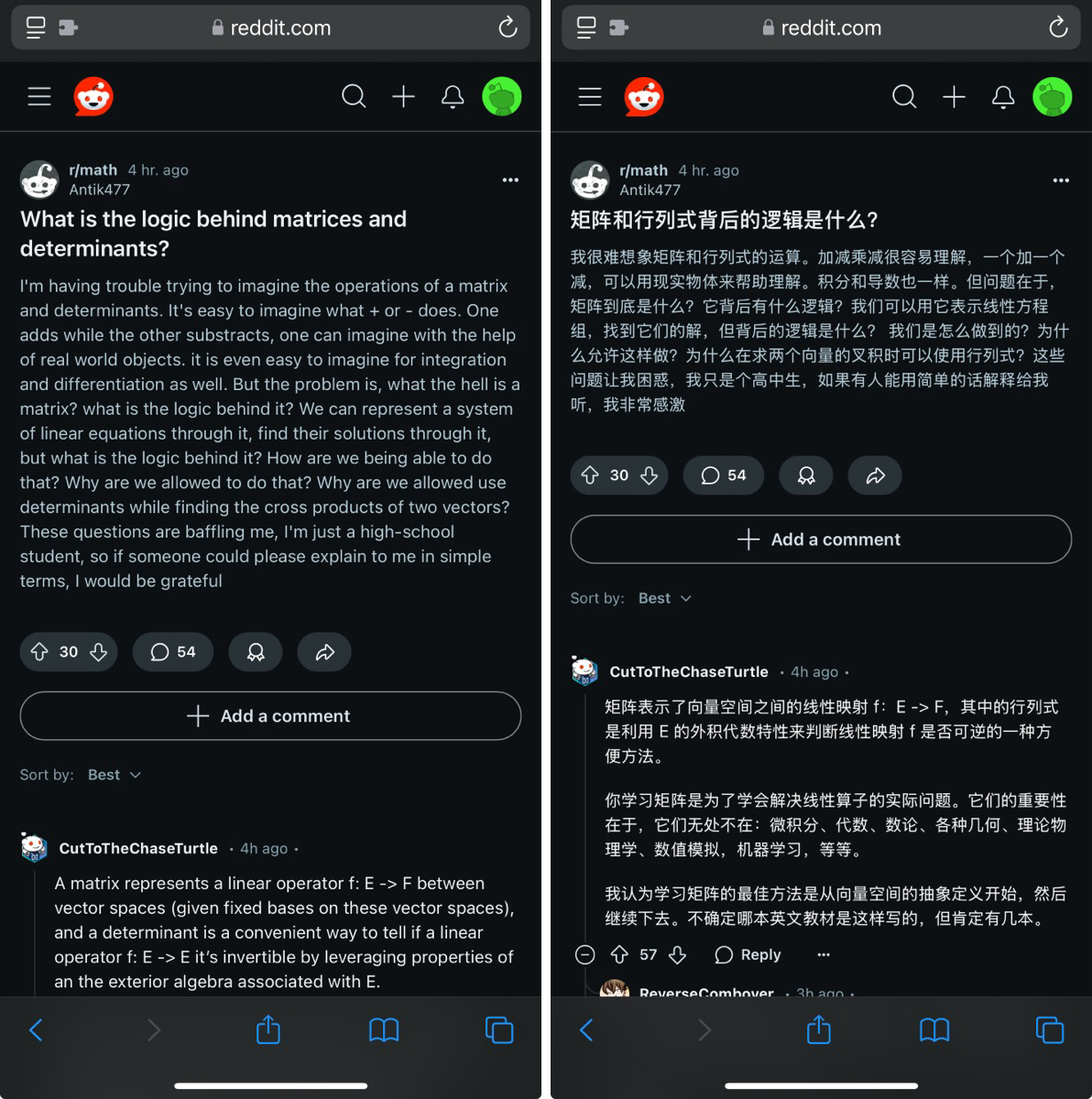
- 场景: 用户可以使用模型,将不同语言的社交媒体内容翻译成母语
- 工具: 沉浸式翻译

- 视频字幕翻译:
- 场景: 用户利用工具,结合模型,直接翻译字幕文件并保存为文件。
- 工具: 沉浸式翻译

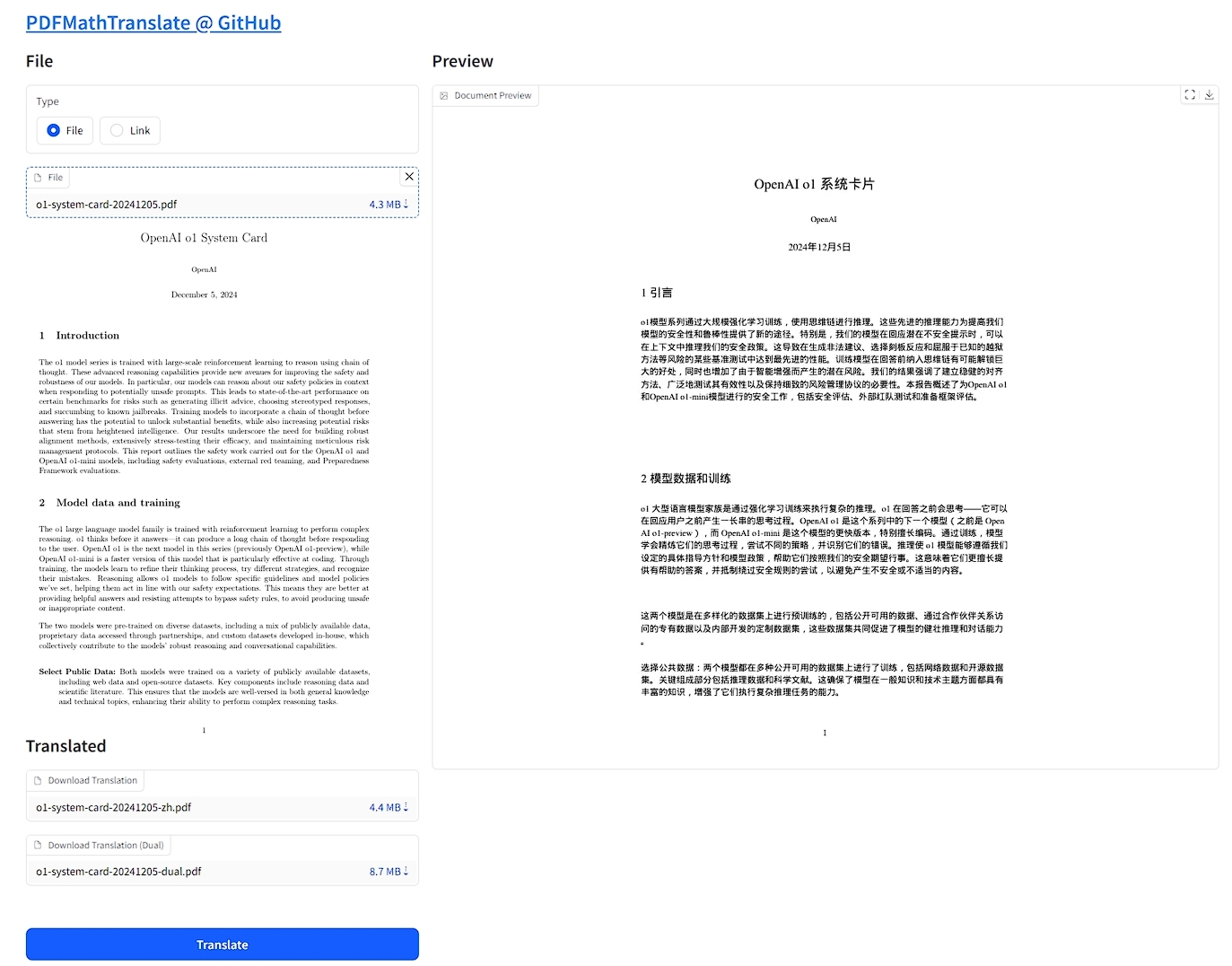
- PDF文件翻译:
- 场景: 用户利用工具,结合模型,将PDF等文档翻译或作为双语对照。
- 工具: PDFMathTranslate
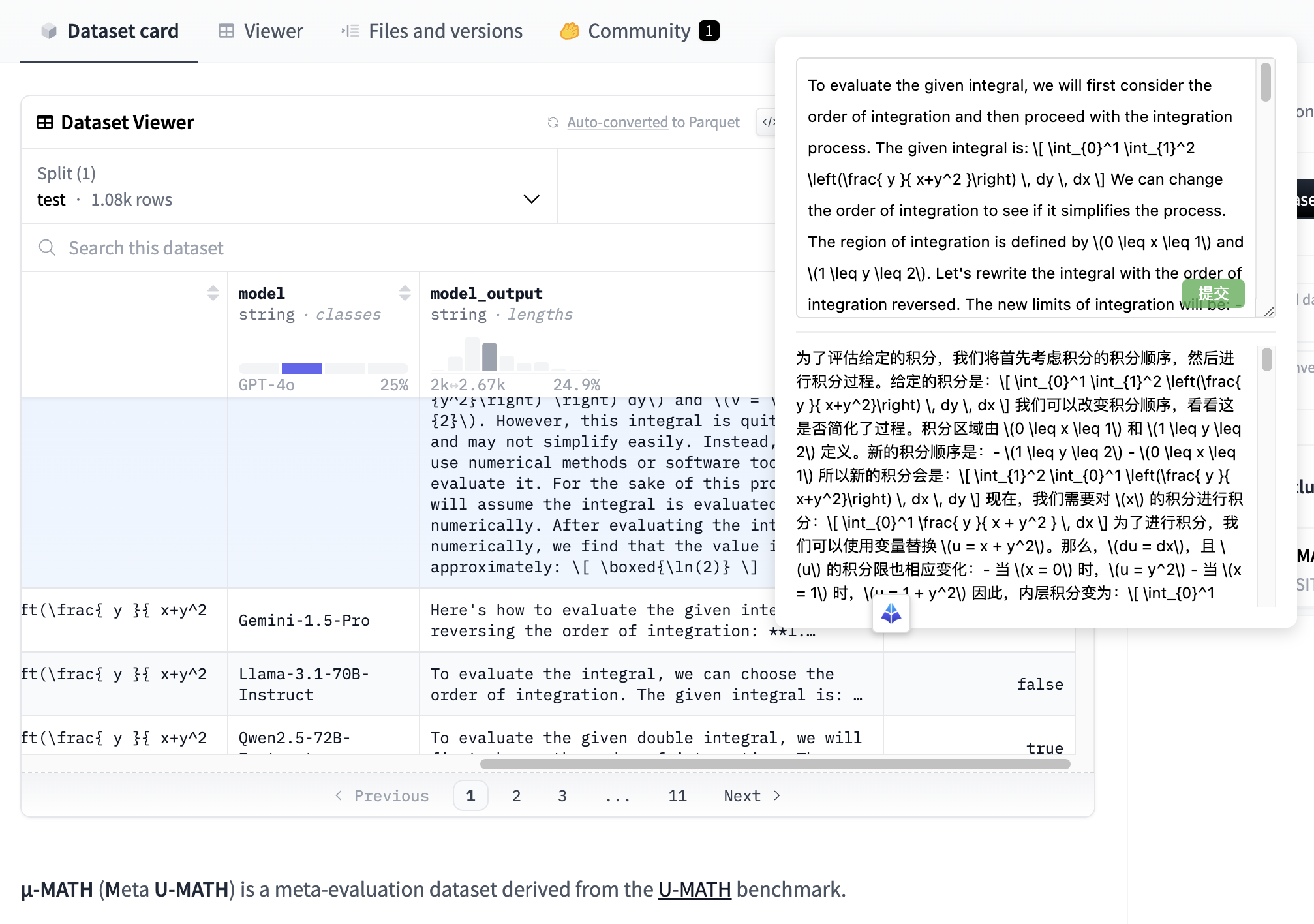
- 数据集翻译:
- 场景: 用户利用模型,将外语数据集进行翻译。
- 工具: wingpt-web-client
- 视频网站实时翻译:
- 场景: 用户利用工具,结合模型,在观看互联网视频时实时生成字幕。
- 工具: 沉浸式翻译


- 视频翻译与字幕压制:
- 场景: 用户利用工具,结合模型,将外语视频生成带有翻译字幕的视频。
- 工具: VideoLingo

注意: 以上示例展示了如何利用工具并结合 WiNGPT-Babel 模型进行文本翻译。你可以根据自己的需求和习惯,通过工具并将其应用到更多场景。
🌱 局限性
- 专业术语翻译: 在法律、医学等高度专业领域、代码等,翻译结果可能存在偏差
- 文学作品翻译: 对于文学作品中的修辞、隐喻等,可能无法完美传达原文意境
- 长文本翻译: 在处理超长文本时,可能会出现翻译错误或者幻觉问题,需要进行分段处理
- 多语言适配: 目前主要在中英语言场景里进行使用,其他语言需要更多的测试和反馈
许可证
- 本项目授权协议为 Apache License 2.0
- 使用本项目包括模型权重时请引用本项目:https://huggingface.co/winninghealth/WiNGPT-Babel
- 遵守 Qwen2.5-1.5B, immersive-translate, VideoLingo 相关协议及其许可证,详细内容参照其网站。
联系我们
通过 WiNGPT 测试平台 申请密钥
或通过 wair@winning.com.cn 与我们取得联系申请接口测试 API_KEY
- Downloads last month
- 606