
Model Description
These are model weights originally provided by the authors of the paper Learning Audio-Visual Speech Representation by Masked Multimodal Cluster Prediction.
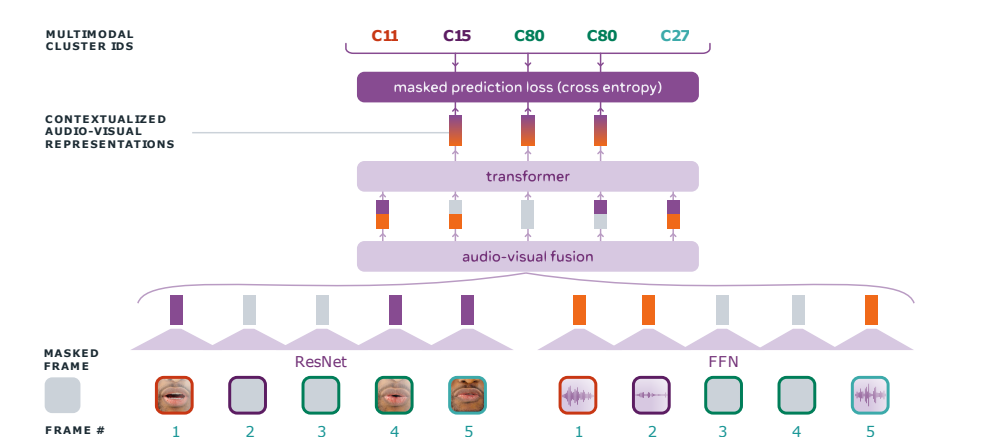
Video recordings of speech contain correlated audio and visual information, providing a strong signal for speech representation learning from the speaker’s lip movements and the produced sound.
Audio-Visual Hidden Unit BERT (AV-HuBERT), a self-supervised representation learning framework for audio-visual speech, which masks multi-stream video input and predicts automatically discovered and iteratively refined multimodal hidden units. AV-HuBERT learns powerful audio-visual speech representation benefiting both lip-reading and automatic speech recognition.
The official code of this paper in here
Example

Datasets
The authors trained the model on LRS3 with 433 hours of transcribed English videos and English portion of VoxCeleb2, which amounts to 1,326 hours