
Model Card for T5-Shona-SC
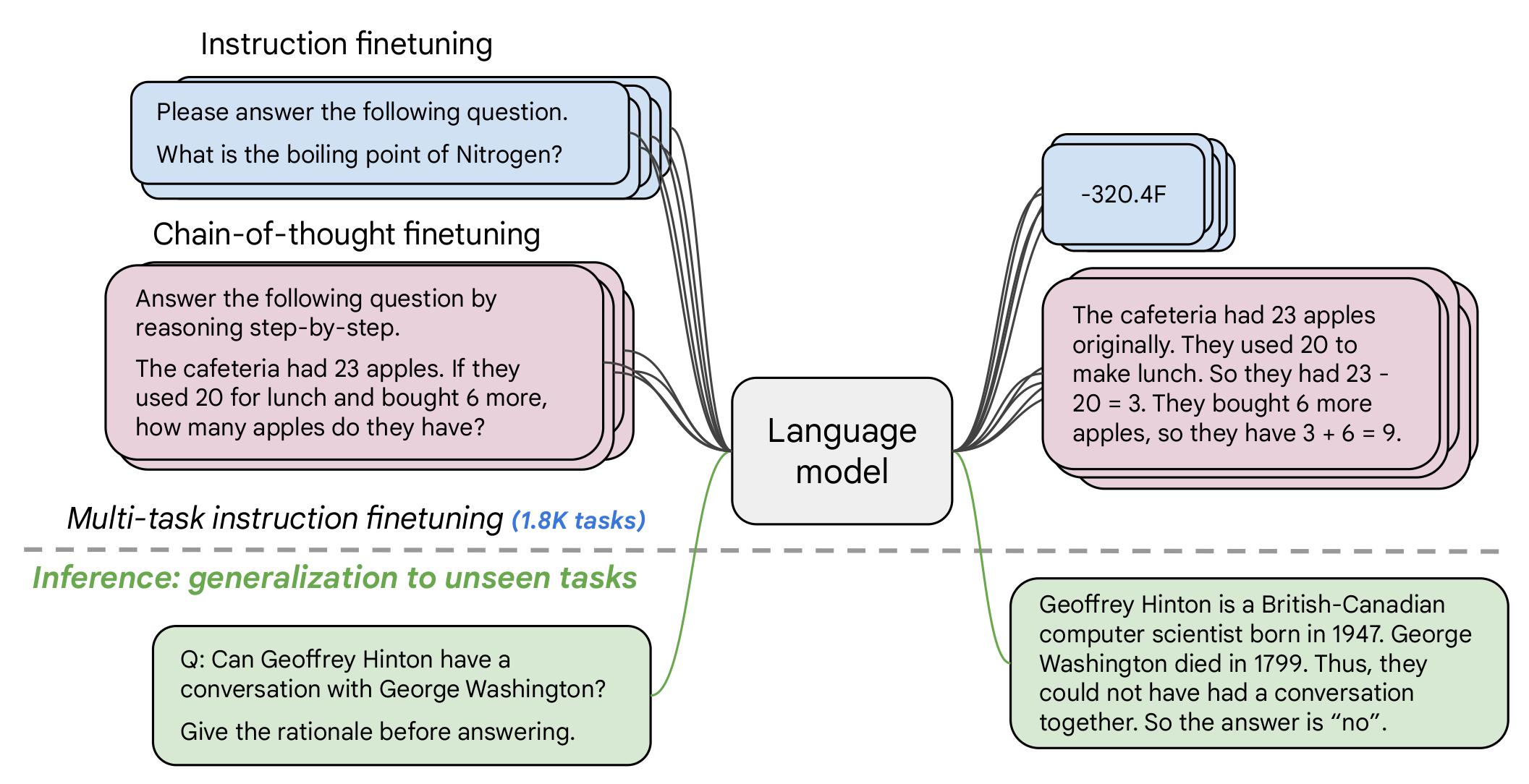
Model Details
Model Description
- Developed by: Thabolezwe Mabandla
- Model type: Language Model
- Language(s) (NLP): Shona
- Finetuned from model: FLAN-T5
Model Sources
- Repository: [More Information Needed]
- Paper: [More Information Needed]
- Demo: [More Information Needed]
Uses
Correction of spelling errors in shona sentences or phrases.
Direct Use
Spelling correction
Bias, Risks, and Limitations
The information below in this section are copied from the model's official model card:
Language models, including Flan-T5, can potentially be used for language generation in a harmful way, according to Rae et al. (2021). Flan-T5 should not be used directly in any application, without a prior assessment of safety and fairness concerns specific to the application.
Ethical considerations and risks
Flan-T5 is fine-tuned on a large corpus of text data that was not filtered for explicit content or assessed for existing biases. As a result the model itself is potentially vulnerable to generating equivalently inappropriate content or replicating inherent biases in the underlying data.
How to Get Started with the Model
Use the code below to get started with the model.
Running the model on a CPU
Click to expand
from transformers import T5Tokenizer, T5ForConditionalGeneration
tokenizer = T5Tokenizer.from_pretrained("thaboe01/t5-spelling-corrector")
model = T5ForConditionalGeneration.from_pretrained("thaboe01/t5-spelling-corrector")
input_text = "Please correct the following sentence: ndaids kurnda kumba kwaco"
input_ids = tokenizer(input_text, return_tensors="pt").input_ids
outputs = model.generate(input_ids)
print(tokenizer.decode(outputs[0]))
Running the model on a GPU
Click to expand
# pip install accelerate
from transformers import T5Tokenizer, T5ForConditionalGeneration
tokenizer = T5Tokenizer.from_pretrained("thaboe01/t5-spelling-corrector")
model = T5ForConditionalGeneration.from_pretrained("thaboe01/t5-spelling-corrector", device_map="auto")
input_text = "Please correct the following sentence: ndaids kurnda kumba kwaco"
input_ids = tokenizer(input_text, return_tensors="pt").input_ids.to("cuda")
outputs = model.generate(input_ids)
print(tokenizer.decode(outputs[0]))
Running the model on a GPU using different precisions
FP16
Click to expand
# pip install accelerate
import torch
from transformers import T5Tokenizer, T5ForConditionalGeneration
tokenizer = T5Tokenizer.from_pretrained("thaboe01/t5-spelling-corrector")
model = T5ForConditionalGeneration.from_pretrained("thaboe01/t5-spelling-corrector", device_map="auto", torch_dtype=torch.float16)
input_text = "Please correct the following sentence: ndaids kurnda kumba kwaco"
input_ids = tokenizer(input_text, return_tensors="pt").input_ids.to("cuda")
outputs = model.generate(input_ids)
print(tokenizer.decode(outputs[0]))
INT8
Click to expand
# pip install bitsandbytes accelerate
from transformers import T5Tokenizer, T5ForConditionalGeneration
tokenizer = T5Tokenizer.from_pretrained("thaboe01/t5-spelling-corrector")
model = T5ForConditionalGeneration.from_pretrained("thaboe01/t5-spelling-corrector", device_map="auto", load_in_8bit=True)
input_text = "Please correct the following sentence: ndaids kurnda kumba kwaco"
input_ids = tokenizer(input_text, return_tensors="pt").input_ids.to("cuda")
outputs = model.generate(input_ids)
print(tokenizer.decode(outputs[0]))
Evaluation
Testing Metrics
Metrics

Environmental Impact
Carbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).
- Hardware Type: [T4 GPU x 2]
- Hours used: [8]
- Cloud Provider: [Kaggle]
Model Card Authors
Thabolezwe Mabandla
Model Card Contact
- Downloads last month
- 127