
File size: 41,147 Bytes
eead5d8 a5686cb ff42e3f f0fc5f8 71ab0a8 5f9881c f842a0e 4b4bf28 f0fc5f8 f842a0e f0fc5f8 6d2199d f0fc5f8 91c4196 5f9881c f0fc5f8 5f9881c f0fc5f8 ff42e3f 6d2199d ff42e3f f0fc5f8 abfa81d ff42e3f 46e3999 6d2199d f0fc5f8 7498c33 99e2b1f 6d2199d 91c4196 6d2199d 91c4196 6d2199d d4c1a74 6d2199d 91c4196 6d2199d a4595fc ff42e3f c974ee5 abfa81d f0fc5f8 a56e564 f0fc5f8 5f9881c f0fc5f8 c974ee5 5f9881c f0fc5f8 d4c1a74 5f9881c c974ee5 5f9881c 91f77da 3d561c7 91f77da 5f9881c 91f77da d4c1a74 4b4bf28 5f9881c 91f77da 5f9881c 3d561c7 5f9881c d4c1a74 3d561c7 5f9881c 2bee256 3d561c7 d4c1a74 5f9881c 3d561c7 d4c1a74 38ed905 d4c1a74 3d561c7 d4c1a74 5f9881c d4c1a74 38ed905 d4c1a74 38ed905 24f8d00 38ed905 24f8d00 2bee256 24f8d00 4b4bf28 2bee256 24f8d00 5f9881c 24f8d00 4b4bf28 24f8d00 4b4bf28 24f8d00 4b4bf28 24f8d00 4b4bf28 24f8d00 5f9881c 6d2199d 5f9881c d4c1a74 ff42e3f f0fc5f8 5f9881c 4b4bf28 ff42e3f 4b4bf28 ff42e3f 4b4bf28 ff42e3f f0fc5f8 5f9881c f0fc5f8 46e3999 a5686cb 91c4196 6d2199d 91c4196 6d2199d 91c4196 12574b1 dc1d7e6 fdf1622 91c4196 6d2199d 91c4196 6d2199d 91c4196 f0fc5f8 ff42e3f 787d3cb c974ee5 787d3cb 38ed905 787d3cb f0fc5f8 38ed905 787d3cb 5f9881c 787d3cb f0fc5f8 c974ee5 3c9e1e2 5f9881c f0fc5f8 5f9881c f0fc5f8 fa9f031 f0fc5f8 5f9881c 38ed905 5f9881c a3bf481 c974ee5 3d561c7 a3bf481 91f77da fa9f031 3c9e1e2 5f9881c 3c9e1e2 5f9881c 8edfef8 5f9881c 3c9e1e2 5f9881c 3c9e1e2 5f9881c 3c9e1e2 5f9881c 3c9e1e2 5f9881c 3c9e1e2 f0fc5f8 4b4bf28 5f9881c f0fc5f8 4857c80 f0fc5f8 5f9881c f0fc5f8 5f9881c f0fc5f8 5f9881c f0fc5f8 12574b1 5f9881c f0fc5f8 a177bf9 f0fc5f8 ff42e3f 78e5850 be5787a 19a9d09 5f9881c f0fc5f8 53cdd75 f0fc5f8 5f9881c f0fc5f8 d271714 56102c0 dace914 8161832 f655fb1 5f9881c f655fb1 5f9881c 53cdd75 5f9881c d8b517c 5f9881c d8b517c 5f9881c 53cdd75 f655fb1 bfed8a0 f655fb1 787d3cb 72c5fd8 f655fb1 12574b1 4b4bf28 b6bb4d7 d730458 d4c1a74 |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 329 330 331 332 333 334 335 336 337 338 339 340 341 342 343 344 345 346 347 348 349 350 351 352 353 354 355 356 357 358 359 360 361 362 363 364 365 366 367 368 369 370 371 372 373 374 375 376 377 378 379 380 381 382 383 384 385 386 387 388 389 390 391 392 393 394 395 396 397 398 399 400 401 402 403 404 405 406 407 408 409 410 411 412 413 414 415 416 417 418 419 420 421 422 423 424 425 426 427 428 429 430 431 432 433 434 435 436 437 438 439 440 441 442 443 444 445 446 447 448 449 450 451 452 453 454 455 456 457 458 459 460 461 462 463 464 465 466 467 468 469 470 471 472 473 474 475 476 477 478 479 480 481 482 483 484 485 486 487 488 489 490 491 492 493 494 495 496 497 498 499 500 501 502 503 504 505 506 507 508 509 510 511 512 513 514 515 516 517 518 519 520 521 522 523 524 525 526 527 528 529 530 531 532 533 534 535 536 537 538 539 540 541 542 543 544 545 546 547 548 549 550 551 552 553 554 555 556 557 558 559 560 561 562 563 564 565 566 567 568 569 570 571 572 573 574 575 576 577 578 579 580 581 582 583 584 585 586 587 588 589 590 591 592 593 594 595 596 597 598 599 600 601 602 603 604 605 606 607 608 609 610 611 612 613 614 615 616 617 618 619 620 621 622 623 624 625 626 627 628 629 630 631 632 633 634 635 636 637 638 639 640 641 642 643 644 645 646 647 648 649 650 651 652 653 654 655 656 657 658 659 660 661 662 663 664 665 666 667 668 669 670 671 672 673 674 675 676 677 678 679 680 681 682 683 684 685 686 687 688 689 690 691 692 693 694 695 696 697 698 699 700 701 702 703 704 705 706 707 708 709 710 711 712 713 714 715 716 717 718 719 720 721 722 723 724 725 726 727 728 729 730 731 732 733 734 735 736 737 738 739 740 741 742 743 744 745 746 747 748 749 750 751 752 753 754 755 756 757 758 759 760 761 762 763 764 765 766 767 768 769 770 771 772 773 774 775 776 777 778 779 780 781 782 783 784 785 786 787 788 789 790 791 792 793 794 795 796 797 798 799 800 801 802 803 804 805 806 807 808 809 810 811 812 813 814 815 816 817 818 819 820 821 822 823 824 825 826 827 828 829 830 831 832 833 834 |
from climateqa.engine.embeddings import get_embeddings_function
embeddings_function = get_embeddings_function()
import gradio as gr
import pandas as pd
import numpy as np
import os
import time
import re
import json
from io import BytesIO
import base64
from datetime import datetime
from azure.storage.fileshare import ShareServiceClient
from utils import create_user_id
# ClimateQ&A imports
from climateqa.engine.llm import get_llm
from climateqa.engine.rag import make_rag_chain
from climateqa.engine.vectorstore import get_pinecone_vectorstore
from climateqa.engine.retriever import ClimateQARetriever
from climateqa.engine.embeddings import get_embeddings_function
from climateqa.engine.prompts import audience_prompts
from climateqa.sample_questions import QUESTIONS
from climateqa.constants import POSSIBLE_REPORTS
from climateqa.utils import get_image_from_azure_blob_storage
# Load environment variables in local mode
try:
from dotenv import load_dotenv
load_dotenv()
except Exception as e:
pass
# Set up Gradio Theme
theme = gr.themes.Base(
primary_hue="blue",
secondary_hue="red",
font=[gr.themes.GoogleFont("Poppins"), "ui-sans-serif", "system-ui", "sans-serif"],
)
init_prompt = ""
system_template = {
"role": "system",
"content": init_prompt,
}
account_key = os.environ["BLOB_ACCOUNT_KEY"]
if len(account_key) == 86:
account_key += "=="
credential = {
"account_key": account_key,
"account_name": os.environ["BLOB_ACCOUNT_NAME"],
}
account_url = os.environ["BLOB_ACCOUNT_URL"]
file_share_name = "climateqa"
service = ShareServiceClient(account_url=account_url, credential=credential)
share_client = service.get_share_client(file_share_name)
user_id = create_user_id()
def parse_output_llm_with_sources(output):
# Split the content into a list of text and "[Doc X]" references
content_parts = re.split(r'\[(Doc\s?\d+(?:,\s?Doc\s?\d+)*)\]', output)
parts = []
for part in content_parts:
if part.startswith("Doc"):
subparts = part.split(",")
subparts = [subpart.lower().replace("doc","").strip() for subpart in subparts]
subparts = [f"<span class='doc-ref'><sup>{subpart}</sup></span>" for subpart in subparts]
parts.append("".join(subparts))
else:
parts.append(part)
content_parts = "".join(parts)
return content_parts
# Create vectorstore and retriever
vectorstore = get_pinecone_vectorstore(embeddings_function)
llm = get_llm(max_tokens = 1024,temperature = 0.0)
def make_pairs(lst):
"""from a list of even lenght, make tupple pairs"""
return [(lst[i], lst[i + 1]) for i in range(0, len(lst), 2)]
def serialize_docs(docs):
new_docs = []
for doc in docs:
new_doc = {}
new_doc["page_content"] = doc.page_content
new_doc["metadata"] = doc.metadata
new_docs.append(new_doc)
return new_docs
# import asyncio
# from typing import Any, Dict, List
# from langchain.callbacks.base import AsyncCallbackHandler, BaseCallbackHandler
# class MyCustomAsyncHandler(AsyncCallbackHandler):
# """Async callback handler that can be used to handle callbacks from langchain."""
# async def on_chain_start(
# self, serialized: Dict[str, Any], inputs: Dict[str, Any], **kwargs: Any
# ) -> Any:
# """Run when chain starts running."""
# print("zzzz....")
# await asyncio.sleep(3)
# print(f"on_chain_start {serialized['name']}")
# # raise gr.Error("ClimateQ&A Error: Timeout, try another question and if the error remains, you can contact us :)")
async def chat(query,history,audience,sources,reports):
"""taking a query and a message history, use a pipeline (reformulation, retriever, answering) to yield a tuple of:
(messages in gradio format, messages in langchain format, source documents)"""
if audience == "Children":
audience_prompt = audience_prompts["children"]
elif audience == "General public":
audience_prompt = audience_prompts["general"]
elif audience == "Experts":
audience_prompt = audience_prompts["experts"]
else:
audience_prompt = audience_prompts["experts"]
# Prepare default values
if len(sources) == 0:
sources = ["IPCC"]
if len(reports) == 0:
reports = []
retriever = ClimateQARetriever(vectorstore=vectorstore,sources = sources,min_size = 200,reports = reports,k_summary = 3,k_total = 15,threshold=0.5)
rag_chain = make_rag_chain(retriever,llm)
# gradio_format = make_pairs([a.content for a in history]) + [(query, "")]
# history = history + [(query,"")]
# print(history)
# print(gradio_format)
# # reset memory
# memory.clear()
# for message in history:
# memory.chat_memory.add_message(message)
inputs = {"query": query,"audience": audience_prompt}
result = rag_chain.astream_log(inputs) #{"callbacks":[MyCustomAsyncHandler()]})
# result = rag_chain.stream(inputs)
reformulated_question_path_id = "/logs/flatten_dict/final_output"
retriever_path_id = "/logs/Retriever/final_output"
streaming_output_path_id = "/logs/AzureChatOpenAI:2/streamed_output_str/-"
final_output_path_id = "/streamed_output/-"
docs_html = ""
output_query = ""
output_language = ""
gallery = []
# for output in result:
# if "language" in output:
# output_language = output["language"]
# if "question" in output:
# output_query = output["question"]
# if "docs" in output:
# try:
# docs = output['docs'] # List[Document]
# docs_html = []
# for i, d in enumerate(docs, 1):
# docs_html.append(make_html_source(d, i))
# docs_html = "".join(docs_html)
# except TypeError:
# print("No documents found")
# continue
# if "answer" in output:
# new_token = output["answer"] # str
# time.sleep(0.03)
# answer_yet = history[-1][1] + new_token
# answer_yet = parse_output_llm_with_sources(answer_yet)
# history[-1] = (query,answer_yet)
# yield history,docs_html,output_query,output_language,gallery
# async def fallback_iterator(iterable):
# async for item in iterable:
# try:
# yield item
# except Exception as e:
# print(f"Error in fallback iterator: {e}")
# raise gr.Error(f"ClimateQ&A Error: {e}\nThe error has been noted, try another question and if the error remains, you can contact us :)")
try:
async for op in result:
op = op.ops[0]
# print("ITERATION",op)
if op['path'] == reformulated_question_path_id: # reforulated question
try:
output_language = op['value']["language"] # str
output_query = op["value"]["question"]
except Exception as e:
raise gr.Error(f"ClimateQ&A Error: {e} - The error has been noted, try another question and if the error remains, you can contact us :)")
elif op['path'] == retriever_path_id: # documents
try:
docs = op['value']['documents'] # List[Document]
docs_html = []
for i, d in enumerate(docs, 1):
docs_html.append(make_html_source(d, i))
docs_html = "".join(docs_html)
except TypeError:
print("No documents found")
print("op: ",op)
continue
elif op['path'] == streaming_output_path_id: # final answer
new_token = op['value'] # str
time.sleep(0.01)
answer_yet = history[-1][1] + new_token
answer_yet = parse_output_llm_with_sources(answer_yet)
history[-1] = (query,answer_yet)
# elif op['path'] == final_output_path_id:
# final_output = op['value']
# if "answer" in final_output:
# final_output = final_output["answer"]
# print(final_output)
# answer = history[-1][1] + final_output
# answer = parse_output_llm_with_sources(answer)
# history[-1] = (query,answer)
else:
continue
history = [tuple(x) for x in history]
yield history,docs_html,output_query,output_language,gallery
except Exception as e:
raise gr.Error(f"ClimateQ&A Error: {e}</br>The error has been noted, try another question and if the error remains, you can contact us :)")
try:
# Log answer on Azure Blob Storage
if os.getenv("GRADIO_ENV") != "local":
timestamp = str(datetime.now().timestamp())
file = timestamp + ".json"
prompt = history[-1][0]
logs = {
"user_id": str(user_id),
"prompt": prompt,
"query": prompt,
"question":output_query,
"sources":sources,
"docs":serialize_docs(docs),
"answer": history[-1][1],
"time": timestamp,
}
log_on_azure(file, logs, share_client)
except Exception as e:
print(f"Error logging on Azure Blob Storage: {e}")
raise gr.Error(f"ClimateQ&A Error: {str(e)[:100]}</br>The error has been noted, try another question and if the error remains, you can contact us :)")
image_dict = {}
for i,doc in enumerate(docs):
if doc.metadata["chunk_type"] == "image":
try:
key = f"Image {i}"
image_path = doc.metadata["image_path"].split("documents/")[1]
img = get_image_from_azure_blob_storage(image_path)
# Convert the image to a byte buffer
buffered = BytesIO()
img.save(buffered, format="PNG")
img_str = base64.b64encode(buffered.getvalue()).decode()
# Embedding the base64 string in Markdown
markdown_image = f""
image_dict[key] = {"img":img,"md":markdown_image,"caption":doc.page_content,"key":key,"figure_code":doc.metadata["figure_code"]}
except Exception as e:
print(f"Skipped adding image {i} because of {e}")
if len(image_dict) > 0:
gallery = [x["img"] for x in list(image_dict.values())]
img = list(image_dict.values())[0]
img_md = img["md"]
img_caption = img["caption"]
img_code = img["figure_code"]
if img_code != "N/A":
img_name = f"{img['key']} - {img['figure_code']}"
else:
img_name = f"{img['key']}"
answer_yet = history[-1][1] + f"\n\n{img_md}\n<p class='chatbot-caption'><b>{img_name}</b> - {img_caption}</p>"
history[-1] = (history[-1][0],answer_yet)
history = [tuple(x) for x in history]
# gallery = [x.metadata["image_path"] for x in docs if (len(x.metadata["image_path"]) > 0 and "IAS" in x.metadata["image_path"])]
# if len(gallery) > 0:
# gallery = list(set("|".join(gallery).split("|")))
# gallery = [get_image_from_azure_blob_storage(x) for x in gallery]
yield history,docs_html,output_query,output_language,gallery
# memory.save_context(inputs, {"answer": gradio_format[-1][1]})
# yield gradio_format, memory.load_memory_variables({})["history"], source_string
# async def chat_with_timeout(query, history, audience, sources, reports, timeout_seconds=2):
# async def timeout_gen(async_gen, timeout):
# try:
# while True:
# try:
# yield await asyncio.wait_for(async_gen.__anext__(), timeout)
# except StopAsyncIteration:
# break
# except asyncio.TimeoutError:
# raise gr.Error("Operation timed out. Please try again.")
# return timeout_gen(chat(query, history, audience, sources, reports), timeout_seconds)
# # A wrapper function that includes a timeout
# async def chat_with_timeout(query, history, audience, sources, reports, timeout_seconds=2):
# try:
# # Use asyncio.wait_for to apply a timeout to the chat function
# return await asyncio.wait_for(chat(query, history, audience, sources, reports), timeout_seconds)
# except asyncio.TimeoutError:
# # Handle the timeout error as desired
# raise gr.Error("Operation timed out. Please try again.")
def make_html_source(source,i):
meta = source.metadata
# content = source.page_content.split(":",1)[1].strip()
content = source.page_content.strip()
toc_levels = []
for j in range(2):
level = meta[f"toc_level{j}"]
if level != "N/A":
toc_levels.append(level)
else:
break
toc_levels = " > ".join(toc_levels)
print(toc_levels)
if len(toc_levels) > 0:
name = f"<b>{toc_levels}</b><br/>{meta['name']}"
else:
name = meta['name']
print(name)
if meta["chunk_type"] == "text":
card = f"""
<div class="card">
<div class="card-content">
<h2>Doc {i} - {meta['short_name']} - Page {int(meta['page_number'])}</h2>
<p>{content}</p>
</div>
<div class="card-footer">
<span>{name}</span>
<a href="{meta['url']}#page={int(meta['page_number'])}" target="_blank" class="pdf-link">
<span role="img" aria-label="Open PDF">🔗</span>
</a>
</div>
</div>
"""
else:
if meta["figure_code"] != "N/A":
title = f"{meta['figure_code']} - {meta['short_name']}"
else:
title = f"{meta['short_name']}"
card = f"""
<div class="card card-image">
<div class="card-content">
<h2>Image {i} - {title} - Page {int(meta['page_number'])}</h2>
<p>{content}</p>
<p class='ai-generated'>AI-generated description</p>
</div>
<div class="card-footer">
<span>{name}</span>
<a href="{meta['url']}#page={int(meta['page_number'])}" target="_blank" class="pdf-link">
<span role="img" aria-label="Open PDF">🔗</span>
</a>
</div>
</div>
"""
return card
# else:
# docs_string = "No relevant passages found in the climate science reports (IPCC and IPBES)"
# complete_response = "**No relevant passages found in the climate science reports (IPCC and IPBES), you may want to ask a more specific question (specifying your question on climate issues).**"
# messages.append({"role": "assistant", "content": complete_response})
# gradio_format = make_pairs([a["content"] for a in messages[1:]])
# yield gradio_format, messages, docs_string
def save_feedback(feed: str, user_id):
if len(feed) > 1:
timestamp = str(datetime.now().timestamp())
file = user_id + timestamp + ".json"
logs = {
"user_id": user_id,
"feedback": feed,
"time": timestamp,
}
log_on_azure(file, logs, share_client)
return "Feedback submitted, thank you!"
def log_on_azure(file, logs, share_client):
logs = json.dumps(logs)
file_client = share_client.get_file_client(file)
print("Uploading logs to Azure Blob Storage")
print("----------------------------------")
print("")
print(logs)
file_client.upload_file(logs)
print("Logs uploaded to Azure Blob Storage")
# --------------------------------------------------------------------
# Gradio
# --------------------------------------------------------------------
init_prompt = """
Hello, I am ClimateQ&A, a conversational assistant designed to help you understand climate change and biodiversity loss. I will answer your questions by **sifting through the IPCC and IPBES scientific reports**.
❓ How to use
- **Language**: You can ask me your questions in any language.
- **Audience**: You can specify your audience (children, general public, experts) to get a more adapted answer.
- **Sources**: You can choose to search in the IPCC or IPBES reports, or both.
⚠️ Limitations
*Please note that the AI is not perfect and may sometimes give irrelevant answers. If you are not satisfied with the answer, please ask a more specific question or report your feedback to help us improve the system.*
What do you want to learn ?
"""
def vote(data: gr.LikeData):
if data.liked:
print(data.value)
else:
print(data)
with gr.Blocks(title="Climate Q&A", css="style.css", theme=theme,elem_id = "main-component") as demo:
# user_id_state = gr.State([user_id])
with gr.Tab("ClimateQ&A"):
with gr.Row(elem_id="chatbot-row"):
with gr.Column(scale=2):
# state = gr.State([system_template])
chatbot = gr.Chatbot(
value=[(None,init_prompt)],
show_copy_button=True,show_label = False,elem_id="chatbot",layout = "panel",
avatar_images = (None,"https://i.ibb.co/YNyd5W2/logo4.png"),
)#,avatar_images = ("assets/logo4.png",None))
# bot.like(vote,None,None)
with gr.Row(elem_id = "input-message"):
textbox=gr.Textbox(placeholder="Ask me anything here!",show_label=False,scale=1,lines = 1,interactive = True)
with gr.Column(scale=1, variant="panel",elem_id = "right-panel"):
with gr.Tabs() as tabs:
with gr.TabItem("Examples",elem_id = "tab-examples",id = 0):
examples_hidden = gr.Textbox(visible = False)
first_key = list(QUESTIONS.keys())[0]
dropdown_samples = gr.Dropdown(QUESTIONS.keys(),value = first_key,interactive = True,show_label = True,label = "Select a category of sample questions",elem_id = "dropdown-samples")
samples = []
for i,key in enumerate(QUESTIONS.keys()):
examples_visible = True if i == 0 else False
with gr.Row(visible = examples_visible) as group_examples:
examples_questions = gr.Examples(
QUESTIONS[key],
[examples_hidden],
examples_per_page=8,
run_on_click=False,
elem_id=f"examples{i}",
api_name=f"examples{i}",
# label = "Click on the example question or enter your own",
# cache_examples=True,
)
samples.append(group_examples)
with gr.Tab("Citations",elem_id = "tab-citations",id = 1):
sources_textbox = gr.HTML(show_label=False, elem_id="sources-textbox")
docs_textbox = gr.State("")
with gr.Tab("Configuration",elem_id = "tab-config",id = 2):
gr.Markdown("Reminder: You can talk in any language, ClimateQ&A is multi-lingual!")
dropdown_sources = gr.CheckboxGroup(
["IPCC", "IPBES"],
label="Select source",
value=["IPCC"],
interactive=True,
)
dropdown_reports = gr.Dropdown(
POSSIBLE_REPORTS,
label="Or select specific reports",
multiselect=True,
value=None,
interactive=True,
)
dropdown_audience = gr.Dropdown(
["Children","General public","Experts"],
label="Select audience",
value="Experts",
interactive=True,
)
output_query = gr.Textbox(label="Query used for retrieval",show_label = True,elem_id = "reformulated-query",lines = 2,interactive = False)
output_language = gr.Textbox(label="Language",show_label = True,elem_id = "language",lines = 1,interactive = False)
#---------------------------------------------------------------------------------------
# OTHER TABS
#---------------------------------------------------------------------------------------
with gr.Tab("Figures",elem_id = "tab-images",elem_classes = "max-height other-tabs"):
gallery_component = gr.Gallery()
with gr.Tab("About ClimateQ&A",elem_classes = "max-height other-tabs"):
with gr.Row():
with gr.Column(scale=1):
gr.Markdown(
"""
<p><b>Climate change and environmental disruptions have become some of the most pressing challenges facing our planet today</b>. As global temperatures rise and ecosystems suffer, it is essential for individuals to understand the gravity of the situation in order to make informed decisions and advocate for appropriate policy changes.</p>
<p>However, comprehending the vast and complex scientific information can be daunting, as the scientific consensus references, such as <b>the Intergovernmental Panel on Climate Change (IPCC) reports, span thousands of pages</b>. To bridge this gap and make climate science more accessible, we introduce <b>ClimateQ&A as a tool to distill expert-level knowledge into easily digestible insights about climate science.</b></p>
<div class="tip-box">
<div class="tip-box-title">
<span class="light-bulb" role="img" aria-label="Light Bulb">💡</span>
How does ClimateQ&A work?
</div>
ClimateQ&A harnesses modern OCR techniques to parse and preprocess IPCC reports. By leveraging state-of-the-art question-answering algorithms, <i>ClimateQ&A is able to sift through the extensive collection of climate scientific reports and identify relevant passages in response to user inquiries</i>. Furthermore, the integration of the ChatGPT API allows ClimateQ&A to present complex data in a user-friendly manner, summarizing key points and facilitating communication of climate science to a wider audience.
</div>
"""
)
with gr.Column(scale=1):
gr.Markdown("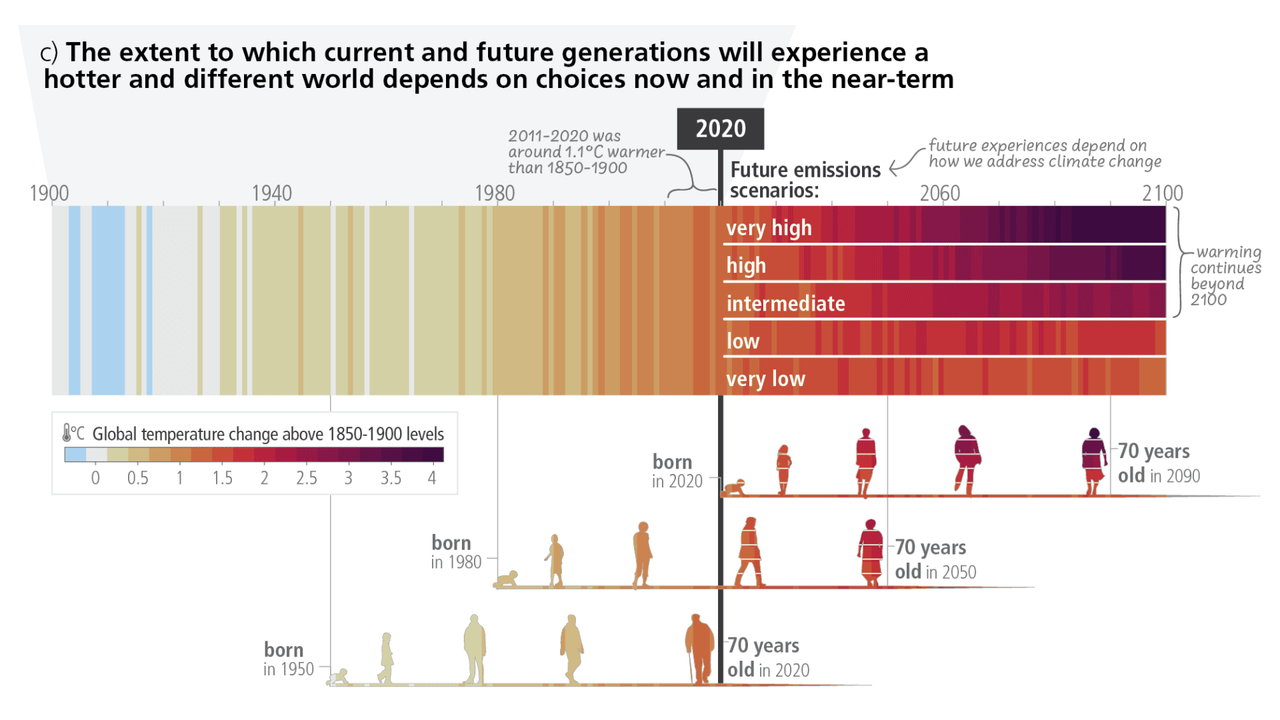")
gr.Markdown("*Source : IPCC AR6 - Synthesis Report of the IPCC 6th assessment report (AR6)*")
gr.Markdown("## How to use ClimateQ&A")
with gr.Row():
with gr.Column(scale=1):
gr.Markdown(
"""
### Getting started
- In the chatbot section, simply type your climate-related question, and ClimateQ&A will provide an answer with references to relevant IPCC reports.
- ClimateQ&A retrieves specific passages from the IPCC reports to help answer your question accurately.
- Source information, including page numbers and passages, is displayed on the right side of the screen for easy verification.
- Feel free to ask follow-up questions within the chatbot for a more in-depth understanding.
- You can ask question in any language, ClimateQ&A is multi-lingual !
- ClimateQ&A integrates multiple sources (IPCC and IPBES, … ) to cover various aspects of environmental science, such as climate change and biodiversity. See all sources used below.
"""
)
with gr.Column(scale=1):
gr.Markdown(
"""
### Limitations
<div class="warning-box">
<ul>
<li>Please note that, like any AI, the model may occasionally generate an inaccurate or imprecise answer. Always refer to the provided sources to verify the validity of the information given. If you find any issues with the response, kindly provide feedback to help improve the system.</li>
<li>ClimateQ&A is specifically designed for climate-related inquiries. If you ask a non-environmental question, the chatbot will politely remind you that its focus is on climate and environmental issues.</li>
</div>
"""
)
with gr.Tab("Contact, feedback and feature requests",elem_classes = "max-height other-tabs"):
gr.Markdown(
"""
For any question or press request, contact Théo Alves Da Costa at <b>theo.alvesdacosta@ekimetrics.com</b>
- ClimateQ&A welcomes community contributions. To participate, head over to the Community Tab and create a "New Discussion" to ask questions and share your insights.
- Provide feedback through email, letting us know which insights you found accurate, useful, or not. Your input will help us improve the platform.
- Only a few sources (see below) are integrated (all IPCC, IPBES), if you are a climate science researcher and net to sift through another report, please let us know.
*This tool has been developed by the R&D lab at **Ekimetrics** (Jean Lelong, Nina Achache, Gabriel Olympie, Nicolas Chesneau, Natalia De la Calzada, Théo Alves Da Costa)*
"""
)
# with gr.Row():
# with gr.Column(scale=1):
# gr.Markdown("### Feedbacks")
# feedback = gr.Textbox(label="Write your feedback here")
# feedback_output = gr.Textbox(label="Submit status")
# feedback_save = gr.Button(value="submit feedback")
# feedback_save.click(
# save_feedback,
# inputs=[feedback, user_id_state],
# outputs=feedback_output,
# )
# gr.Markdown(
# "If you need us to ask another climate science report or ask any question, contact us at <b>theo.alvesdacosta@ekimetrics.com</b>"
# )
# with gr.Column(scale=1):
# gr.Markdown("### OpenAI API")
# gr.Markdown(
# "To make climate science accessible to a wider audience, we have opened our own OpenAI API key with a monthly cap of $1000. If you already have an API key, please use it to help conserve bandwidth for others."
# )
# openai_api_key_textbox = gr.Textbox(
# placeholder="Paste your OpenAI API key (sk-...) and hit Enter",
# show_label=False,
# lines=1,
# type="password",
# )
# openai_api_key_textbox.change(set_openai_api_key, inputs=[openai_api_key_textbox])
# openai_api_key_textbox.submit(set_openai_api_key, inputs=[openai_api_key_textbox])
with gr.Tab("Sources",elem_classes = "max-height other-tabs"):
gr.Markdown("""
| Source | Report | URL | Number of pages | Release date |
| --- | --- | --- | --- | --- |
IPCC | Summary for Policymakers. In: Climate Change 2021: The Physical Science Basis. Contribution of the WGI to the AR6 of the IPCC. | https://www.ipcc.ch/report/ar6/wg1/downloads/report/IPCC_AR6_WGI_SPM.pdf | 32 | 2021
IPCC | Full Report. In: Climate Change 2021: The Physical Science Basis. Contribution of the WGI to the AR6 of the IPCC. | https://report.ipcc.ch/ar6/wg1/IPCC_AR6_WGI_FullReport.pdf | 2409 | 2021
IPCC | Technical Summary. In: Climate Change 2021: The Physical Science Basis. Contribution of the WGI to the AR6 of the IPCC. | https://www.ipcc.ch/report/ar6/wg1/downloads/report/IPCC_AR6_WGI_TS.pdf | 112 | 2021
IPCC | Summary for Policymakers. In: Climate Change 2022: Impacts, Adaptation and Vulnerability. Contribution of the WGII to the AR6 of the IPCC. | https://www.ipcc.ch/report/ar6/wg2/downloads/report/IPCC_AR6_WGII_SummaryForPolicymakers.pdf | 34 | 2022
IPCC | Technical Summary. In: Climate Change 2022: Impacts, Adaptation and Vulnerability. Contribution of the WGII to the AR6 of the IPCC. | https://www.ipcc.ch/report/ar6/wg2/downloads/report/IPCC_AR6_WGII_TechnicalSummary.pdf | 84 | 2022
IPCC | Full Report. In: Climate Change 2022: Impacts, Adaptation and Vulnerability. Contribution of the WGII to the AR6 of the IPCC. | https://report.ipcc.ch/ar6/wg2/IPCC_AR6_WGII_FullReport.pdf | 3068 | 2022
IPCC | Summary for Policymakers. In: Climate Change 2022: Mitigation of Climate Change. Contribution of the WGIII to the AR6 of the IPCC. | https://www.ipcc.ch/report/ar6/wg3/downloads/report/IPCC_AR6_WGIII_SummaryForPolicymakers.pdf | 50 | 2022
IPCC | Technical Summary. In: Climate Change 2022: Mitigation of Climate Change. Contribution of the WGIII to the AR6 of the IPCC. | https://www.ipcc.ch/report/ar6/wg3/downloads/report/IPCC_AR6_WGIII_TechnicalSummary.pdf | 102 | 2022
IPCC | Full Report. In: Climate Change 2022: Mitigation of Climate Change. Contribution of the WGIII to the AR6 of the IPCC. | https://www.ipcc.ch/report/ar6/wg3/downloads/report/IPCC_AR6_WGIII_FullReport.pdf | 2258 | 2022
IPCC | Summary for Policymakers. In: Global Warming of 1.5°C. An IPCC Special Report on the impacts of global warming of 1.5°C above pre-industrial levels and related global greenhouse gas emission pathways, in the context of strengthening the global response to the threat of climate change, sustainable development, and efforts to eradicate poverty. | https://www.ipcc.ch/site/assets/uploads/sites/2/2022/06/SPM_version_report_LR.pdf | 24 | 2018
IPCC | Summary for Policymakers. In: Climate Change and Land: an IPCC special report on climate change, desertification, land degradation, sustainable land management, food security, and greenhouse gas fluxes in terrestrial ecosystems. | https://www.ipcc.ch/site/assets/uploads/sites/4/2022/11/SRCCL_SPM.pdf | 36 | 2019
IPCC | Summary for Policymakers. In: IPCC Special Report on the Ocean and Cryosphere in a Changing Climate. | https://www.ipcc.ch/site/assets/uploads/sites/3/2022/03/01_SROCC_SPM_FINAL.pdf | 36 | 2019
IPCC | Technical Summary. In: IPCC Special Report on the Ocean and Cryosphere in a Changing Climate. | https://www.ipcc.ch/site/assets/uploads/sites/3/2022/03/02_SROCC_TS_FINAL.pdf | 34 | 2019
IPCC | Chapter 1 - Framing and Context of the Report. In: IPCC Special Report on the Ocean and Cryosphere in a Changing Climate. | https://www.ipcc.ch/site/assets/uploads/sites/3/2022/03/03_SROCC_Ch01_FINAL.pdf | 60 | 2019
IPCC | Chapter 2 - High Mountain Areas. In: IPCC Special Report on the Ocean and Cryosphere in a Changing Climate. | https://www.ipcc.ch/site/assets/uploads/sites/3/2022/03/04_SROCC_Ch02_FINAL.pdf | 72 | 2019
IPCC | Chapter 3 - Polar Regions. In: IPCC Special Report on the Ocean and Cryosphere in a Changing Climate. | https://www.ipcc.ch/site/assets/uploads/sites/3/2022/03/05_SROCC_Ch03_FINAL.pdf | 118 | 2019
IPCC | Chapter 4 - Sea Level Rise and Implications for Low-Lying Islands, Coasts and Communities. In: IPCC Special Report on the Ocean and Cryosphere in a Changing Climate. | https://www.ipcc.ch/site/assets/uploads/sites/3/2022/03/06_SROCC_Ch04_FINAL.pdf | 126 | 2019
IPCC | Chapter 5 - Changing Ocean, Marine Ecosystems, and Dependent Communities. In: IPCC Special Report on the Ocean and Cryosphere in a Changing Climate. | https://www.ipcc.ch/site/assets/uploads/sites/3/2022/03/07_SROCC_Ch05_FINAL.pdf | 142 | 2019
IPCC | Chapter 6 - Extremes, Abrupt Changes and Managing Risk. In: IPCC Special Report on the Ocean and Cryosphere in a Changing Climate. | https://www.ipcc.ch/site/assets/uploads/sites/3/2022/03/08_SROCC_Ch06_FINAL.pdf | 68 | 2019
IPCC | Cross-Chapter Box 9: Integrative Cross-Chapter Box on Low-Lying Islands and Coasts. In: IPCC Special Report on the Ocean and Cryosphere in a Changing Climate. | https://www.ipcc.ch/site/assets/uploads/sites/3/2019/11/11_SROCC_CCB9-LLIC_FINAL.pdf | 18 | 2019
IPCC | Annex I: Glossary [Weyer, N.M. (ed.)]. In: IPCC Special Report on the Ocean and Cryosphere in a Changing Climate. | https://www.ipcc.ch/site/assets/uploads/sites/3/2022/03/10_SROCC_AnnexI-Glossary_FINAL.pdf | 28 | 2019
IPBES | Full Report. Global assessment report on biodiversity and ecosystem services of the IPBES. | https://zenodo.org/record/6417333/files/202206_IPBES%20GLOBAL%20REPORT_FULL_DIGITAL_MARCH%202022.pdf | 1148 | 2019
IPBES | Summary for Policymakers. Global assessment report on biodiversity and ecosystem services of the IPBES (Version 1). | https://zenodo.org/record/3553579/files/ipbes_global_assessment_report_summary_for_policymakers.pdf | 60 | 2019
IPBES | Full Report. Thematic assessment of the sustainable use of wild species of the IPBES. | https://zenodo.org/record/7755805/files/IPBES_ASSESSMENT_SUWS_FULL_REPORT.pdf | 1008 | 2022
IPBES | Summary for Policymakers. Summary for policymakers of the thematic assessment of the sustainable use of wild species of the IPBES. | https://zenodo.org/record/7411847/files/EN_SPM_SUSTAINABLE%20USE%20OF%20WILD%20SPECIES.pdf | 44 | 2022
IPBES | Full Report. Regional Assessment Report on Biodiversity and Ecosystem Services for Africa. | https://zenodo.org/record/3236178/files/ipbes_assessment_report_africa_EN.pdf | 494 | 2018
IPBES | Summary for Policymakers. Regional Assessment Report on Biodiversity and Ecosystem Services for Africa. | https://zenodo.org/record/3236189/files/ipbes_assessment_spm_africa_EN.pdf | 52 | 2018
IPBES | Full Report. Regional Assessment Report on Biodiversity and Ecosystem Services for the Americas. | https://zenodo.org/record/3236253/files/ipbes_assessment_report_americas_EN.pdf | 660 | 2018
IPBES | Summary for Policymakers. Regional Assessment Report on Biodiversity and Ecosystem Services for the Americas. | https://zenodo.org/record/3236292/files/ipbes_assessment_spm_americas_EN.pdf | 44 | 2018
IPBES | Full Report. Regional Assessment Report on Biodiversity and Ecosystem Services for Asia and the Pacific. | https://zenodo.org/record/3237374/files/ipbes_assessment_report_ap_EN.pdf | 616 | 2018
IPBES | Summary for Policymakers. Regional Assessment Report on Biodiversity and Ecosystem Services for Asia and the Pacific. | https://zenodo.org/record/3237383/files/ipbes_assessment_spm_ap_EN.pdf | 44 | 2018
IPBES | Full Report. Regional Assessment Report on Biodiversity and Ecosystem Services for Europe and Central Asia. | https://zenodo.org/record/3237429/files/ipbes_assessment_report_eca_EN.pdf | 894 | 2018
IPBES | Summary for Policymakers. Regional Assessment Report on Biodiversity and Ecosystem Services for Europe and Central Asia. | https://zenodo.org/record/3237468/files/ipbes_assessment_spm_eca_EN.pdf | 52 | 2018
IPBES | Full Report. Assessment Report on Land Degradation and Restoration. | https://zenodo.org/record/3237393/files/ipbes_assessment_report_ldra_EN.pdf | 748 | 2018
IPBES | IPBES Invasive Alien Species Assessment: Summary for Policymakers & 6 chapters | https://zenodo.org/records/10127924/files/Summary%20for%20policymakers_IPBES%20IAS%20Assessment.pdf | 56 + 1198 | 2023
""")
with gr.Tab("Carbon Footprint",elem_classes = "max-height other-tabs"):
gr.Markdown("""
Carbon emissions were measured during the development and inference process using CodeCarbon [https://github.com/mlco2/codecarbon](https://github.com/mlco2/codecarbon)
| Phase | Description | Emissions | Source |
| --- | --- | --- | --- |
| Development | OCR and parsing all pdf documents with AI | 28gCO2e | CodeCarbon |
| Development | Question Answering development | 114gCO2e | CodeCarbon |
| Inference | Question Answering | ~0.102gCO2e / call | CodeCarbon |
| Inference | API call to turbo-GPT | ~0.38gCO2e / call | https://medium.com/@chrispointon/the-carbon-footprint-of-chatgpt-e1bc14e4cc2a |
Carbon Emissions are **relatively low but not negligible** compared to other usages: one question asked to ClimateQ&A is around 0.482gCO2e - equivalent to 2.2m by car (https://datagir.ademe.fr/apps/impact-co2/)
Or around 2 to 4 times more than a typical Google search.
"""
)
with gr.Tab("Changelog",elem_classes = "max-height other-tabs"):
gr.Markdown("""
##### Upcoming features
- Figures retrieval and multimodal system
- Conversational chat
- Intent routing
- Local environment setup
##### v1.2.1 - *2024-01-16*
- BUG - corrected asynchronous bug failing the chatbot frequently
##### v1.2.0 - *2023-11-27*
- Added new IPBES assessment on Invasive Species (SPM and chapters)
- Switched all the codebase to LCEL (Langchain Expression Language)
- Added sample questions by category
- Switched embeddings from old ``sentence-transformers/multi-qa-mpnet-base-dot-v1`` to ``BAAI/bge-base-en-v1.5``
- Report filtering to select directly the report you want to source your answers from
- First naive version of a figures retrieval system by looking up the figures in the retrieved pages
##### v1.1.0 - *2023-10-16*
- ClimateQ&A on Hugging Face is finally working again with all the new features !
- Switched all python code to langchain codebase for cleaner code, easier maintenance and future features
- Updated GPT model to August version
- Added streaming response to improve UX
- Created a custom Retriever chain to avoid calling the LLM if there is no documents retrieved
- Use of HuggingFace embed on https://climateqa.com to avoid demultiplying deployments
##### v1.0.0 - *2023-05-11*
- First version of clean interface on https://climateqa.com
- Add children mode on https://climateqa.com
- Add follow-up questions https://climateqa.com
"""
)
def start_chat(query,history):
history = history + [(query,"")]
history = [tuple(x) for x in history]
print(history)
return (gr.update(interactive = False),gr.update(selected=1),history)
def finish_chat():
return (gr.update(interactive = True,value = ""))
(textbox
.submit(start_chat, [textbox,chatbot], [textbox,tabs,chatbot],queue = False,api_name = "start_chat_textbox")
.then(chat, [textbox,chatbot,dropdown_audience, dropdown_sources,dropdown_reports], [chatbot,sources_textbox,output_query,output_language,gallery_component],concurrency_limit = 8,api_name = "chat_textbox")
.then(finish_chat, None, [textbox],api_name = "finish_chat_textbox")
)
(examples_hidden
.change(start_chat, [examples_hidden,chatbot], [textbox,tabs,chatbot],queue = False,api_name = "start_chat_examples")
.then(chat, [examples_hidden,chatbot,dropdown_audience, dropdown_sources,dropdown_reports], [chatbot,sources_textbox,output_query,output_language,gallery_component],concurrency_limit = 8,api_name = "chat_examples")
.then(finish_chat, None, [textbox],api_name = "finish_chat_examples")
)
def change_sample_questions(key):
index = list(QUESTIONS.keys()).index(key)
visible_bools = [False] * len(samples)
visible_bools[index] = True
return [gr.update(visible=visible_bools[i]) for i in range(len(samples))]
dropdown_samples.change(change_sample_questions,dropdown_samples,samples)
# # textbox.submit(predict_climateqa,[textbox,bot],[None,bot,sources_textbox])
# (textbox
# .submit(answer_user, [textbox,examples_hidden, bot], [textbox, bot],queue = False)
# .success(change_tab,None,tabs)
# .success(fetch_sources,[textbox,dropdown_sources], [textbox,sources_textbox,docs_textbox,output_query,output_language])
# .success(answer_bot, [textbox,bot,docs_textbox,output_query,output_language,dropdown_audience], [textbox,bot],queue = True)
# .success(lambda x : textbox,[textbox],[textbox])
# )
# (examples_hidden
# .change(answer_user_example, [textbox,examples_hidden, bot], [textbox, bot],queue = False)
# .success(change_tab,None,tabs)
# .success(fetch_sources,[textbox,dropdown_sources], [textbox,sources_textbox,docs_textbox,output_query,output_language])
# .success(answer_bot, [textbox,bot,docs_textbox,output_query,output_language,dropdown_audience], [textbox,bot],queue=True)
# .success(lambda x : textbox,[textbox],[textbox])
# )
# submit_button.click(answer_user, [textbox, bot], [textbox, bot], queue=True).then(
# answer_bot, [textbox,bot,dropdown_audience,dropdown_sources], [textbox,bot,sources_textbox]
# )
demo.queue()
demo.launch()
|