
File size: 10,029 Bytes
7b696a9 0efbbd1 b837cef 2695353 7b696a9 d4e9403 7b696a9 bd7a321 7b696a9 f0113bc b26f2f0 f0113bc 7464d19 781637d eecfcaa f0113bc 2c046ad f0113bc 7b696a9 bd7a321 027fe5b bd7a321 027fe5b bd7a321 eecfcaa 7b696a9 691294e 7b696a9 691294e b837cef eecfcaa 691294e eecfcaa 691294e b837cef 691294e b837cef 691294e eecfcaa dffbbc0 eecfcaa 30e0538 |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 |
---
library_name: transformers
tags:
- mergekit
- merge
license: apache-2.0
base_model:
- arcee-ai/Virtuoso-Small
- CultriX/SeQwence-14B-EvolMerge
- CultriX/Qwen2.5-14B-Wernicke
- sthenno-com/miscii-14b-1028
- underwoods/medius-erebus-magnum-14b
- sometimesanotion/lamarck-14b-prose-model_stock
- sometimesanotion/lamarck-14b-reason-model_stock
language:
- en
---

---
### Overview:
Lamarck-14B is a carefully designed merge which emphasizes [arcee-ai/Virtuoso-Small](https://huggingface.co/arcee-ai/Virtuoso-Small) in early and finishing layers, and midway features strong influence on reasoning and prose from [CultriX/SeQwence-14B-EvolMerge](http://huggingface.co/CultriX/SeQwence-14B-EvolMerge) especially, but a hefty list of other models as well.
Its reasoning and prose skills are quite strong. Version 0.3 is the product of a carefully planned and tested sequence of templated merges, produced by a toolchain which wraps around Arcee's mergekit.
For GGUFs, [mradermacher/Lamarck-14B-v0.3-i1-GGUF](https://huggingface.co/mradermacher/Lamarck-14B-v0.3-i1-GGUF) has you covered. Thank you @mradermacher!
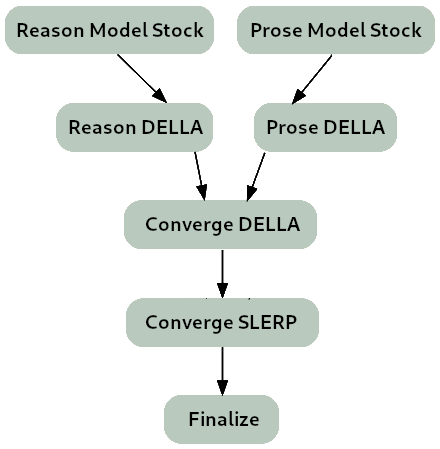
**The merge strategy of Lamarck 0.3 can be summarized as:**
- Two model_stocks commence specialized branches for reasoning and prose quality.
- For refinement on both model_stocks, DELLA and SLERP merges re-emphasize selected ancestors.
- For smooth instruction following, a SLERP merged Virtuoso with converged branches.
- For finalization and normalization, a TIES merge.
### Thanks go to:
- @arcee-ai's team for the ever-capable mergekit, and the exceptional Virtuoso Small model.
- @CultriX for the helpful examples of memory-efficient sliced merges and evolutionary merging. Their contribution of tinyevals on version 0.1 of Lamarck did much to validate the hypotheses of the process used here.
- The authors behind the capable models that appear in the model_stock. The boost to prose quality is already noticeable.
### Models Merged:
**Top influences:** These ancestors are base models and present in the model_stocks, but are heavily re-emphasized in the DELLA and SLERP merges.
- **[arcee-ai/Virtuoso-Small](https://huggingface.co/arcee-ai/Virtuoso-Small)** - A brand new model from Arcee, refined from the notable cross-architecture Llama-to-Qwen distillation [arcee-ai/SuperNova-Medius](https://huggingface.co/arcee-ai/SuperNova-Medius). The first two layers are nearly exclusively from Virtuoso. It has proven to be a well-rounded performer, and contributes a noticeable boost to the model's prose quality.
- **[CultriX/SeQwence-14B-EvolMerge](http://huggingface.co/CultriX/SeQwence-14B-EvolMerge)** - A top contender on reasoning benchmarks.
**Reason:** While Virtuoso is the strongest influence the starting ending layers, the reasoning mo
- **[CultriX/Qwen2.5-14B-Wernicke](http://huggingface.co/CultriX/Qwen2.5-14B-Wernicke)** - A top performer for Arc and GPQA, Wernicke is re-emphasized in small but highly-ranked portions of the model.
- **[VAGOsolutions/SauerkrautLM-v2-14b-DPO](https://huggingface.co/VAGOsolutions/SauerkrautLM-v2-14b-DPO)** - This model's influence is understated, but aids BBH and coding capability.
**Prose:** While the prose module is gently applied, its impact is noticeable on Lamarck 0.3's prose quality, and a DELLA merge re-emphasizes the contributions of two models particularly:
- **[sthenno-com/miscii-14b-1028](https://huggingface.co/sthenno-com/miscii-14b-1028)**
- **[underwoods/medius-erebus-magnum-14b](https://huggingface.co/underwoods/medius-erebus-magnum-14b)**
**Model stock:** Two model_stock merges, specialized for specific aspects of performance, are used to mildly influence a large range of the model.
- **[sometimesanotion/lamarck-14b-reason-model_stock](https://huggingface.co/sometimesanotion/lamarck-14b-reason-model_stock)**
- **[sometimesanotion/lamarck-14b-prose-model_stock](https://huggingface.co/sometimesanotion/lamarck-14b-prose-model_stock)** - This brings in a little influence from [EVA-UNIT-01/EVA-Qwen2.5-14B-v0.2](https://huggingface.co/EVA-UNIT-01/EVA-Qwen2.5-14B-v0.2), [oxyapi/oxy-1-small](https://huggingface.co/oxyapi/oxy-1-small), and [allura-org/TQ2.5-14B-Sugarquill-v1](https://huggingface.co/allura-org/TQ2.5-14B-Sugarquill-v1).
**Note on abliteration:** This author believes that adjacent services and not language models themselves are where guardrails are best placed. Effort to de-censor Lamarck will resume after the model has been further studied.
### Configuration:
The following YAML configurations were used to produce this model:
```yaml
name: lamarck-14b-reason-della # This contributes the knowledge and reasoning pool, later to be merged
merge_method: della # with the dominant instruction-following model
base_model: arcee-ai/Virtuoso-Small
tokenizer_source: arcee-ai/Virtuoso-Small
parameters:
int8_mask: false
normalize: true
rescale: false
density: 0.30
weight: 0.50
epsilon: 0.08
lambda: 1.00
models:
- model: CultriX/SeQwence-14B-EvolMerge
parameters:
density: 0.70
weight: 0.90
- model: sometimesanotion/lamarck-14b-reason-model_stock
parameters:
density: 0.90
weight: 0.60
- model: CultriX/Qwen2.5-14B-Wernicke
parameters:
density: 0.20
weight: 0.30
dtype: bfloat16
out_dtype: bfloat16
---
name: lamarck-14b-prose-della # This contributes the prose, later to be merged
merge_method: della # with the dominant instruction-following model
base_model: arcee-ai/Virtuoso-Small
tokenizer_source: arcee-ai/Virtuoso-Small
parameters:
int8_mask: false
normalize: true
rescale: false
density: 0.30
weight: 0.50
epsilon: 0.08
lambda: 0.95
models:
- model: sthenno-com/miscii-14b-1028
parameters:
density: 0.40
weight: 0.90
- model: sometimesanotion/lamarck-14b-prose-model_stock
parameters:
density: 0.60
weight: 0.70
- model: underwoods/medius-erebus-magnum-14b
dtype: bfloat16
out_dtype: bfloat16
---
name: lamarck-14b-converge-della # This is the strongest control point to quickly
merge_method: della # re-balance reasoning vs. prose
base_model: arcee-ai/Virtuoso-Small
tokenizer_source: arcee-ai/Virtuoso-Small
parameters:
int8_mask: false
normalize: true
rescale: false
density: 0.30
weight: 0.50
epsilon: 0.08
lambda: 1.00
models:
- model: sometimesanotion/lamarck-14b-reason-della
parameters:
density: 0.80
weight: 1.00
- model: arcee-ai/Virtuoso-Small
parameters:
density: 0.40
weight: 0.50
- model: sometimesanotion/lamarck-14b-prose-della
parameters:
density: 0.10
weight: 0.40
dtype: bfloat16
out_dtype: bfloat16
---
name: lamarck-14b-converge # Virtuoso has good capabilities all-around; it is 100% of the first
merge_method: slerp # two layers, and blends into the reasoning+prose convergance
base_model: arcee-ai/Virtuoso-Small # for some interesting boosts
tokenizer_source: base
parameters:
t: [ 0.00, 0.60, 0.80, 0.80, 0.80, 0.70, 0.40 ]
slices:
- sources:
- layer_range: [ 0, 2 ]
model: arcee-ai/Virtuoso-Small
- layer_range: [ 0, 2 ]
model: merges/lamarck-14b-converge-della
t: [ 0.00, 0.00 ]
- sources:
- layer_range: [ 2, 8 ]
model: arcee-ai/Virtuoso-Small
- layer_range: [ 2, 8 ]
model: merges/lamarck-14b-converge-della
t: [ 0.00, 0.60 ]
- sources:
- layer_range: [ 8, 16 ]
model: arcee-ai/Virtuoso-Small
- layer_range: [ 8, 16 ]
model: merges/lamarck-14b-converge-della
t: [ 0.60, 0.70 ]
- sources:
- layer_range: [ 16, 24 ]
model: arcee-ai/Virtuoso-Small
- layer_range: [ 16, 24 ]
model: merges/lamarck-14b-converge-della
t: [ 0.70, 0.70 ]
- sources:
- layer_range: [ 24, 32 ]
model: arcee-ai/Virtuoso-Small
- layer_range: [ 24, 32 ]
model: merges/lamarck-14b-converge-della
t: [ 0.70, 0.70 ]
- sources:
- layer_range: [ 32, 40 ]
model: arcee-ai/Virtuoso-Small
- layer_range: [ 32, 40 ]
model: merges/lamarck-14b-converge-della
t: [ 0.70, 0.60 ]
- sources:
- layer_range: [ 40, 48 ]
model: arcee-ai/Virtuoso-Small
- layer_range: [ 40, 48 ]
model: merges/lamarck-14b-converge-della
t: [ 0.60, 0.40 ]
dtype: bfloat16
out_dtype: bfloat16
---
name: lamarck-14b-finalize
merge_method: ties
base_model: Qwen/Qwen2.5-14B
tokenizer_source: Qwen/Qwen2.5-14B-Instruct
parameters:
int8_mask: false
normalize: true
rescale: false
density: 1.00
weight: 1.00
models:
- model: merges/lamarck-14b-converge
dtype: bfloat16
out_dtype: bfloat16
---
```
|