
Llama3.1 ELM Turbo
Collection
Collection of ELM Turbo model cards based on meta-llama/Meta-Llama-3.1-8B-Instruct
•
10 items
•
Updated
•
2
ELM (which stands for Efficient Language Models) Turbo is the next generation model in the series of cutting-edge language models from SliceX AI that is designed to achieve the best in class performance in terms of quality, throughput & memory.
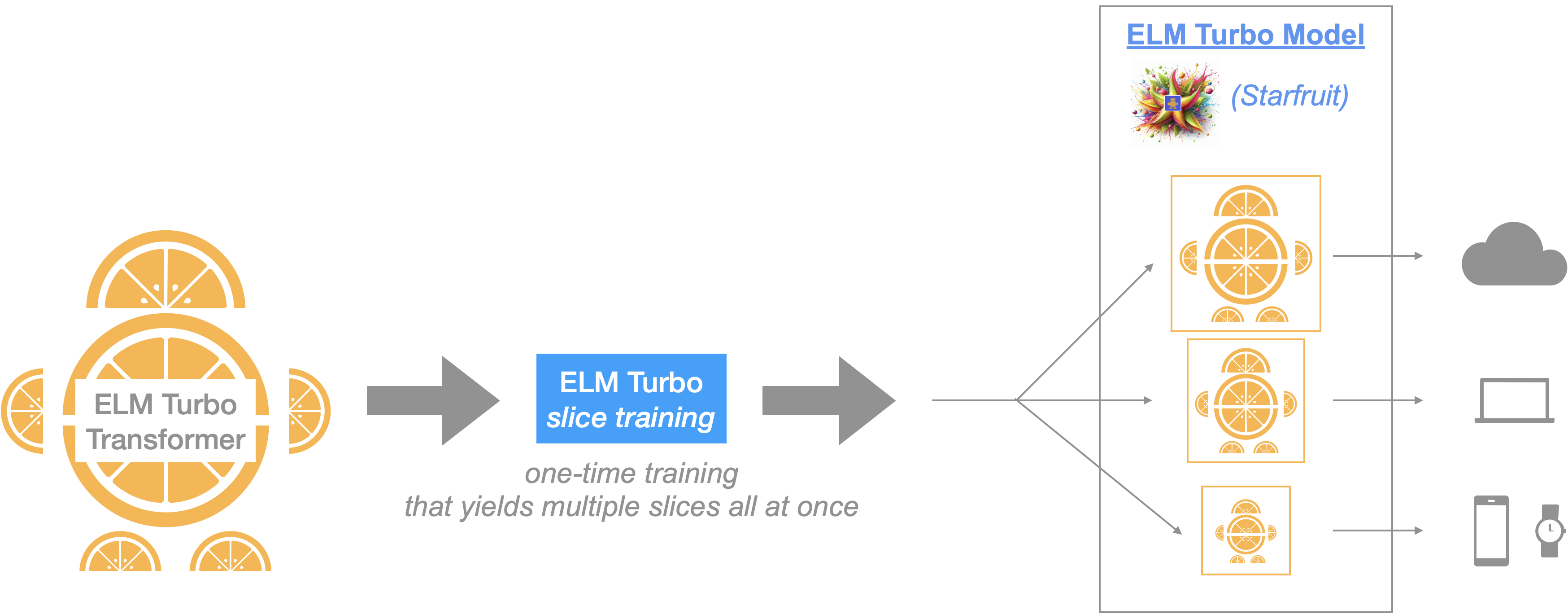
ELM is designed to be a modular and customizable family of neural networks that are highly efficient and performant. Today we are sharing the second version in this series: ELM Turbo models (named Starfruit).
Model: ELM Turbo introduces a more adaptable, decomposable LLM architecture thereby yielding flexibility in (de)-composing LLM models into smaller stand-alone slices. In comparison to our previous version, the new architecture allows for more powerful model slices to be learnt during the training process (yielding better quality & higher generative capacity) and a higher level of control wrt LLM efficiency - fine-grained slices to produce varying LLM model sizes (depending on the user/task needs and deployment criteria, i.e., Cloud or Edge device constraints).
Training: ELM Turbo introduces algorithmic optimizations that allows us to train a single model but once trained the ELM Turbo model can be sliced in many ways to fit different user/task needs. We formulate the entire training procedure for ELM Turbo as a continual learning process during which we apply "slicing" operations & corresponding optimizations during the pre-training and/or fine-tuning stage. In a nutshell, this procedure teaches the model to learn & compress its knowledge into smaller slices.
Fast Inference with Customization: As with our previous version, once trained, ELM Turbo model architecture permits flexible inference strategies at runtime depending on deployment & device constraints to allow users to make optimal compute/memory tradeoff choices for their application needs. In addition to the blazing fast speeds achieved by native ELM Turbo slice optimization, we also layered in NVIDIA's TensorRT-LLM integration to get further speedups. The end result 👉 optimized ELM Turbo models that achieve one of the world's best LLM performance.
In this version, we employed our new, improved decomposable ELM techniques on a widely used open-source LLM, meta-llama/Meta-Llama-3.1-8B-Instruct (8B params) (check Llama-license for usage). After training, we generated three smaller slices with parameter counts ranging from 3B billion to 6B billion.
NOTE: The open-source datasets from the HuggingFace hub used for instruction fine-tuning ELM Turbo include, but are not limited to: allenai/tulu-v2-sft-mixture, microsoft/orca-math-word-problems-200k, mlabonne/WizardLM_evol_instruct_70k-ShareGPT, and mlabonne/WizardLM_evol_instruct_v2_196K-ShareGPT. We advise users to exercise caution when utilizing ELM Turbo, as these datasets may contain factually incorrect information, unintended biases, inappropriate content, and other potential issues. It is recommended to thoroughly evaluate the model's outputs and implement appropriate safeguards for your specific use case.
[Cloud AI] If you are using A100 or H100 GPUs, you can utilize our pre-built ELM Turbo-TRTLLM engines. Below are the instructions to install and run them.
Additionally, you can build your own TRTLLM engines by following the instructions provided in Section (c) below.
[Edge AI] To run on edge (Windows RTX), follow the instructions provided by Nvidia in their TRT-LLM documentation: Windows README.
The following commands create a Docker container named elm_trtllm and install TensorRT-LLM. If you encounter any installation errors related to TensorRT-LLM, please refer to the troubleshooting section here.
git clone https://github.com/slicex-ai/elm-turbo.git
cd elm-turbo
sh setup_trtllm.sh
This creates a docker named elm_trtllm and installs tensorrt_llm.
Example: To run our pre-built trt-engine for slicexai/Llama3.1-elm-turbo-6B-instruct on A100 & H100 gpus respectively,
docker attach elm_trtllm
cd /lm
sh run_elm_turbo_trtllm_engine.sh slicexai/Llama3.1-elm-turbo-6B-instruct A100 "plan a fun day with my grandparents."
sh run_elm_turbo_trtllm_engine.sh slicexai/Llama3.1-elm-turbo-6B-instruct H100 "plan a fun day with my grandparents."
Detailed instructions to run the engine:
Usage: sh run_elm_turbo_trtllm_engine.sh <elm_turbo_model_id> <gpu_type> "<input_prompt>"
Supported elm-turbo_model_id choices : [slicexai/Llama3.1-elm-turbo-6B-instruct, slicexai/Llama3.1-elm-turbo-4B-instruct, slicexai/Llama3.1-elm-turbo-3B-instruct]
Supported gpu_types : [A100, H100]
To build an elm-turbo slicexai/Llama3.1-elm-turbo-6B-instruct tensortrt_llm engine with INT-8 quantization, follow the instructions below. For more detailed configurations, refer to the Llama conversion instructions provided by NVIDIA here.
docker attach elm_trtllm
cd /lm/TensorRT-LLM/examples/llama
huggingface-cli download slicexai/Llama3.1-elm-turbo-6B-instruct --local-dir ../slicexai/Llama3.1-elm-turbo-6B-instruct
python3 convert_checkpoint.py --dtype bfloat16 --use_weight_only --weight_only_precision int8 --model_dir ../slicexai/Llama3.1-elm-turbo-6B-instruct --output_dir ../slicexai/Llama3.1-elm-turbo-6B-instruct-trtllm-ckpt
trtllm-build --gpt_attention_plugin bfloat16 --gemm_plugin bfloat16 --max_seq_len 4096 --max_batch_size 256 --checkpoint_dir ../slicexai/Llama3.1-elm-turbo-6B-instruct-trtllm-ckpt --output_dir ../slicexai/Llama3.1-elm-turbo-6B-instruct-trtllm-engine
Now that you’ve got your model engine, it's time to run it.
python3 ../run.py \
--engine_dir ../slicexai/Llama3.1-elm-turbo-6B-instruct-trtllm-engine \
--max_output_len 512 \
--presence_penalty 0.7 \
--frequency_penalty 0.7 \
--tokenizer_dir ../slicexai/Llama3.1-elm-turbo-6B-instruct \
--input_text """<|begin_of_text|><|start_header_id|>user<|end_header_id|>
plan a fun day with my grandparents.<|eot_id|><|start_header_id|>assistant<|end_header_id|>
"""