
ConflLlama: GTD-Finetuned Llama-3 8B
- Model Type: GGUF quantized (q4_k_m and q8_0)
- Base Model: unsloth/llama-3-8b-bnb-4bit
- Quantization Details:
- Methods: q4_k_m, q8_0, BF16
- q4_k_m uses Q6_K for half of attention.wv and feed_forward.w2 tensors
- Optimized for both speed (q8_0) and quality (q4_k_m)
Training Data
- Dataset: Global Terrorism Database (GTD)
- Time Period: Events before January 1, 2017
- Format: Event summaries with associated attack types
- Labels: Attack type classifications from GTD
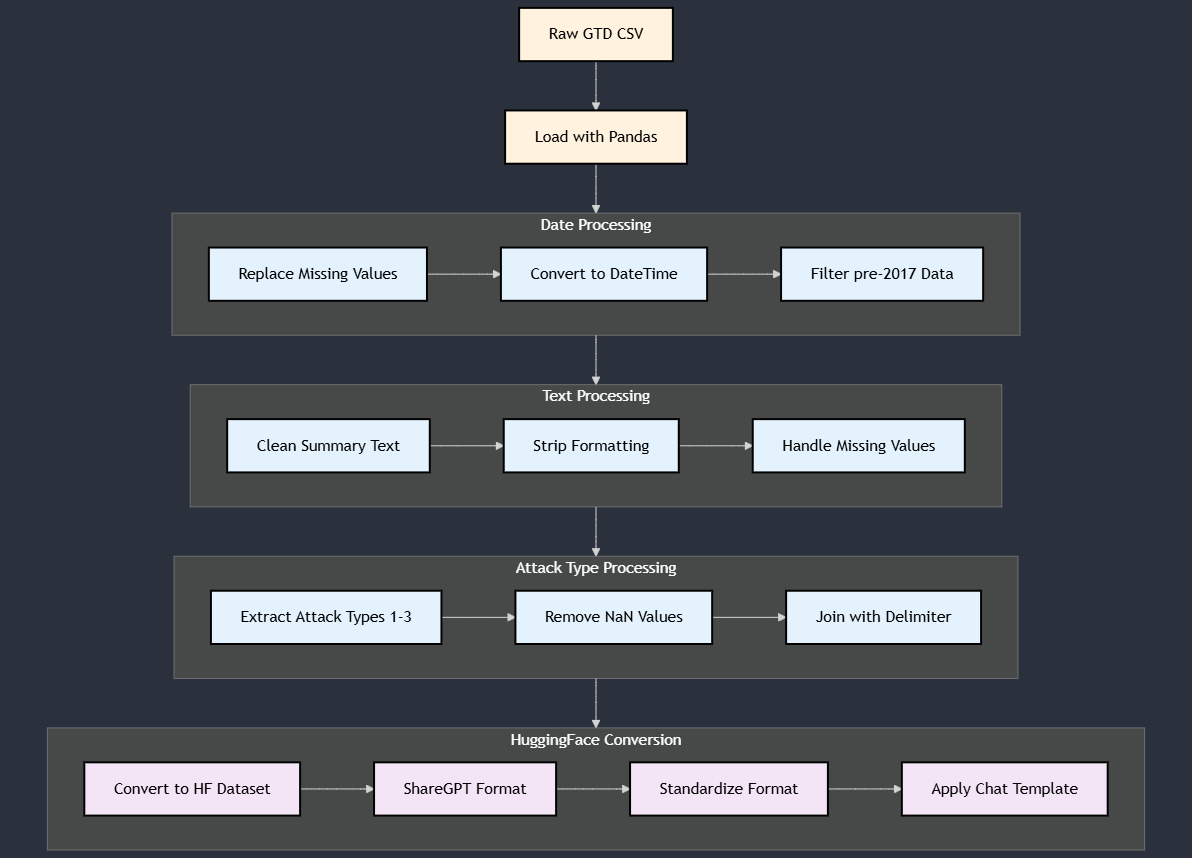
Data Processing
- Date Filtering:
- Filtered events occurring before 2017-01-01
- Handled missing dates by setting default month/day to 1
- Data Cleaning:
- Removed entries with missing summaries
- Cleaned summary text by removing special characters and formatting
- Attack Type Processing:
- Combined multiple attack types with separator '|'
- Included primary, secondary, and tertiary attack types when available
- Training Format:
Training Details
- Framework: QLoRA
- Hardware: NVIDIA A100-SXM4-40GB GPU on Delta Supercomputer
- Training Configuration:
- Batch Size: 1 per device
- Gradient Accumulation Steps: 8
- Learning Rate: 2e-4
- Max Steps: 1000
- Save Steps: 200
- Logging Steps: 10
- LoRA Configuration:
- Rank: 8
- Target Modules: q_proj, k_proj, v_proj, o_proj, gate_proj, up_proj, down_proj
- Alpha: 16
- Dropout: 0
- Optimizations:
- Gradient Checkpointing: Enabled
- 4-bit Quantization: Enabled
- Max Sequence Length: 1024
Model Architecture
The model uses a combination of efficient fine-tuning techniques and optimizations for handling conflict event classification:
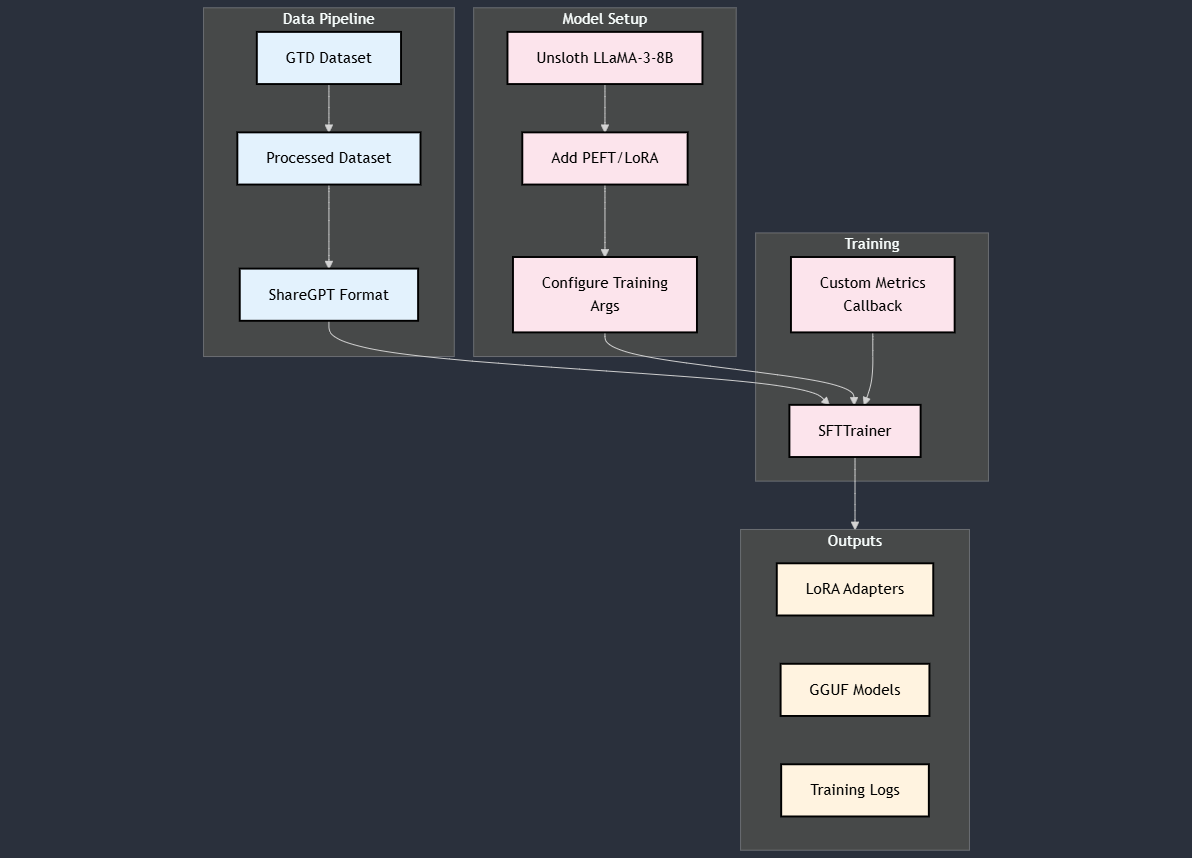
Data Processing Pipeline
The preprocessing pipeline transforms raw GTD data into a format suitable for fine-tuning:
Memory Optimizations
- Used 4-bit quantization
- Gradient accumulation steps: 8
- Memory-efficient gradient checkpointing
- Reduced maximum sequence length to 1024
- Disabled dataloader pin memory
Intended Use
This model is designed for:
- Classification of terrorist events based on event descriptions
- Research in conflict studies and terrorism analysis
- Understanding attack type patterns in historical events
- Academic research in security studies
Limitations
- Training data limited to pre-2017 events
- Maximum sequence length limited to 1024 tokens
- May not capture recent changes in attack patterns
- Performance dependent on quality of event descriptions
Ethical Considerations
- Model trained on sensitive terrorism-related data
- Should be used responsibly for research purposes only
- Not intended for operational security decisions
- Results should be interpreted with appropriate context
Training Logs
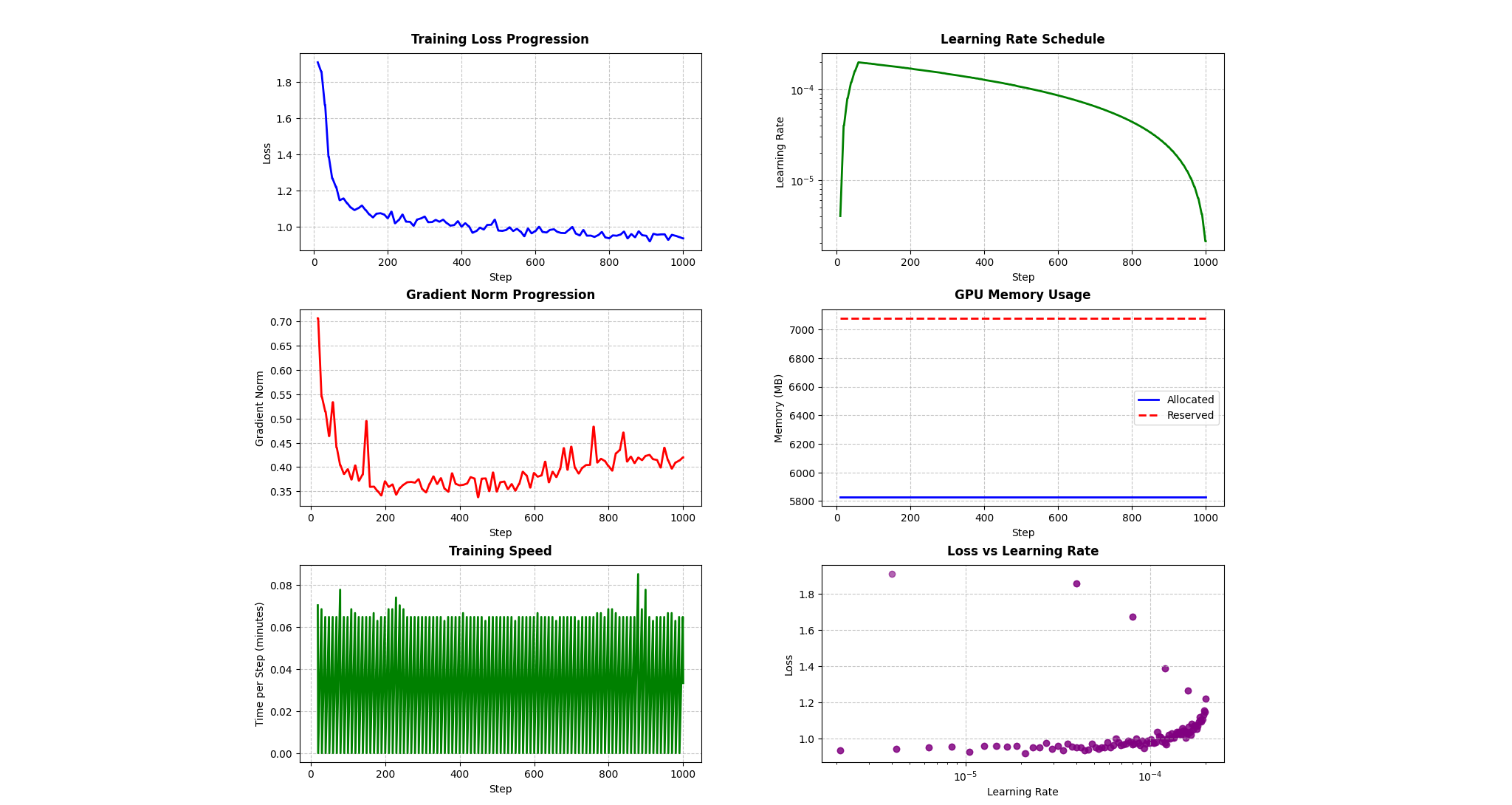
The training logs show a successful training run with healthy convergence patterns:
Loss & Learning Rate:
- Loss decreases from 1.95 to ~0.90, with rapid initial improvement
- Learning rate uses warmup/decay schedule, peaking at ~1.5x10^-4
Training Stability:
- Stable gradient norms (0.4-0.6 range)
- Consistent GPU memory usage (~5800MB allocated, 7080MB reserved)
- Steady training speed (~3.5s/step) with brief interruption at step 800
The graphs indicate effective model training with good optimization dynamics and resource utilization. The loss vs. learning rate plot suggests optimal learning around 10^-4.
Citation
@misc{conflllama,
author = {Meher, Shreyas},
title = {ConflLlama: GTD-Finetuned LLaMA-3 8B},
year = {2024},
publisher = {HuggingFace},
note = {Based on Meta's LLaMA-3 8B and GTD Dataset}
}
Acknowledgments
- Unsloth for optimization framework and base model
- Hugging Face for transformers infrastructure
- Global Terrorism Database team
- This research was supported by NSF award 2311142
- This work used Delta at NCSA / University of Illinois through allocation CIS220162 from the Advanced Cyberinfrastructure Coordination Ecosystem: Services & Support (ACCESS) program, which is supported by NSF grants 2138259, 2138286, 2138307, 2137603, and 2138296

