
MixLoRA: Enhancing Large Language Models Fine-Tuning with LoRA-based Mixture of Experts
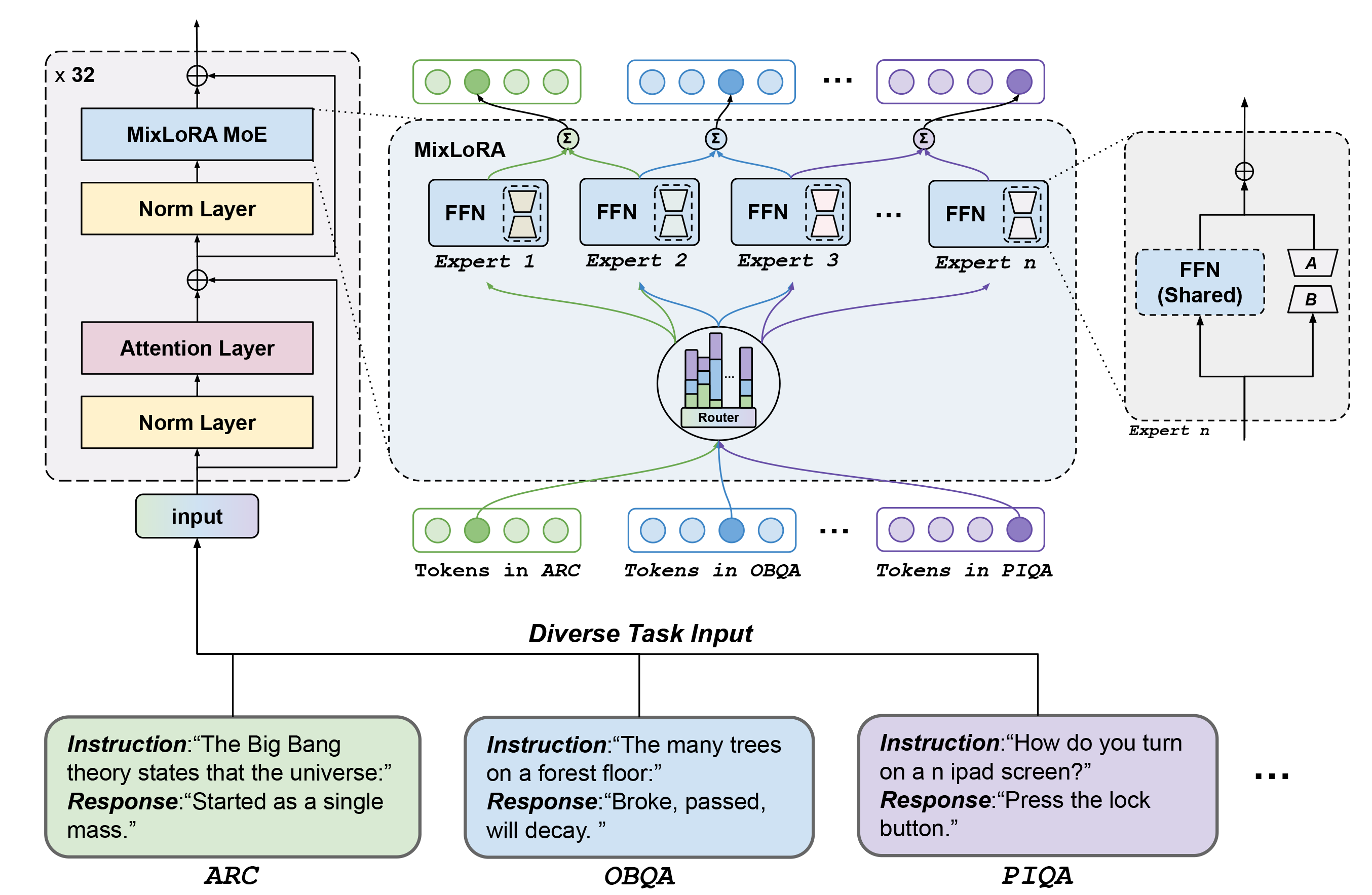
Fine-tuning Large Language Models (LLMs) is a common practice to adapt pre-trained models for specific applications. While methods like LoRA have effectively addressed GPU memory constraints during fine-tuning, their performance often falls short, especially in multi-task scenarios. In contrast, Mixture-of-Expert (MoE) models, such as Mixtral 8x7B, demonstrate remarkable performance in multi-task learning scenarios while maintaining a reduced parameter count. However, the resource requirements of these MoEs remain challenging, particularly for consumer-grade GPUs with less than 24GB memory. To tackle these challenges, we propose MixLoRA, an approach to construct a resource-efficient sparse MoE model based on LoRA. The figure above shows the architecture of the MixLoRA transformer block. MixLoRA inserts multiple LoRA-based experts within the feed-forward network block of a frozen pre-trained dense model and employs a commonly used top-k router. Unlike other LoRA-based MoE methods, MixLoRA enhances model performance by utilizing independent attention-layer LoRA adapters. Additionally, an auxiliary load balance loss is employed to address the imbalance problem of the router. Our evaluations show that MixLoRA improves about 9% accuracy compared to state-of-the-art PEFT methods in multi-task learning scenarios.
| PEFT Method | # Params (%) | ARC-e | ARC-c | BoolQ | OBQA | PIQA | SIQA | HellaS | WinoG | AVG. |
|---|---|---|---|---|---|---|---|---|---|---|
| LoRA | 2.9% | 73.8 | 50.9 | 62.2 | 80.4 | 82.1 | 69.9 | 88.4 | 66.8 | 71.8 |
| DoRA | 2.9% | 76.5 | 59.8 | 71.7 | 80.6 | 82.7 | 74.1 | 89.6 | 67.3 | 75.3 |
| MixLoRA | 2.9% | 77.7 | 58.1 | 72.7 | 81.6 | 83.2 | 78.0 | 93.1 | 76.8 | 77.6 |
| MixDoRA | 2.9% | 77.5 | 58.2 | 72.6 | 80.9 | 82.2 | 80.4 | 90.6 | 83.4 | 78.2 |
The table above presents the performance of MixLoRA and compares these results with outcomes obtained by employing LoRA and DoRA for fine-tuning. The results demonstrate that the language model with MixLoRA achieves commendable performance across all evaluation methods. All methods are fine-tuned and evaluated with meta-llama/Llama-2-7b-hf on m-LoRA, with all metrics reported as accuracy.
You can check the full experimental results, including other pre-trained models such as Gemma 2B, LLaMA3 8B, and LLaMA2 13B, and detailed performance metrics in our preprint paper: Li D, Ma Y, Wang N, et al. MixLoRA: Enhancing Large Language Models Fine-Tuning with LoRA based Mixture of Experts[J]. arXiv preprint arXiv:2404.15159, 2024.
How to Use
Please visit our GitHub repository: https://github.com/TUDB-Labs/MixLoRA
Citation
If MixLoRA has been useful for your work, please consider citing it using the appropriate citation format for your publication.
@misc{li2024mixloraenhancinglargelanguage,
title={MixLoRA: Enhancing Large Language Models Fine-Tuning with LoRA-based Mixture of Experts},
author={Dengchun Li and Yingzi Ma and Naizheng Wang and Zhengmao Ye and Zhiyuan Cheng and Yinghao Tang and Yan Zhang and Lei Duan and Jie Zuo and Cal Yang and Mingjie Tang},
year={2024},
eprint={2404.15159},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2404.15159},
}
@misc{alpaca-mixlora-7b,
author={Dengchun Li and Yingzi Ma and Naizheng Wang and Zhengmao Ye and Zhiyuan Cheng and Yinghao Tang and Yan Zhang and Lei Duan and Jie Zuo and Cal Yang and Mingjie Tang},
title = {MixLoRA adapter based on AlpacaCleaned dataset and LLaMA-2-7B base model},
year = {2024},
publisher = {HuggingFace Hub},
howpublished = {\url{https://huggingface.co/TUDB-Labs/alpaca-mixlora-7b}},
}
Copyright
Copyright © 2023-2024 All Rights Reserved.
m-LoRA and the weights of alpaca-mixlora-7b are licensed under the Apache 2.0 License.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
Model tree for TUDB-Labs/alpaca-mixlora-7b
Base model
meta-llama/Llama-2-7b-hf