
Japanese to Korean translator for FFXIV
FINAL FANTASY is a registered trademark of Square Enix Holdings Co., Ltd.
This project is detailed on the Github repo.
Demo
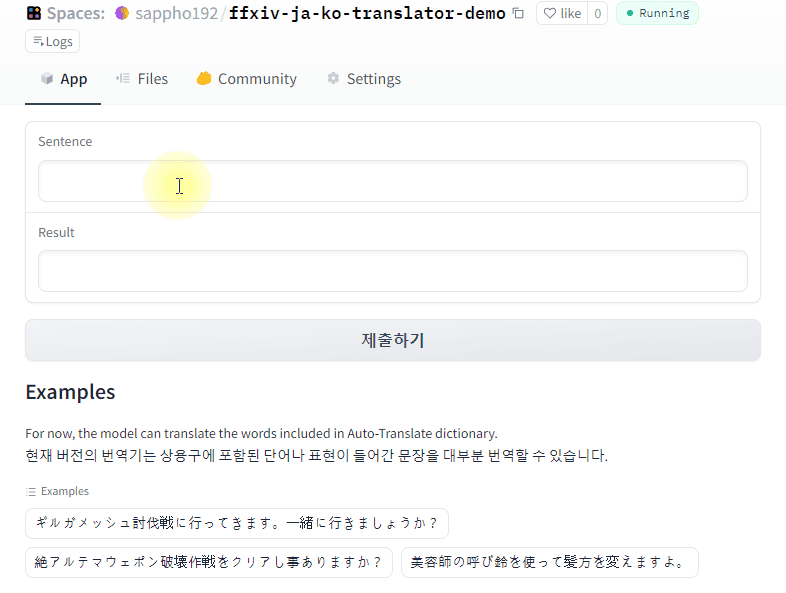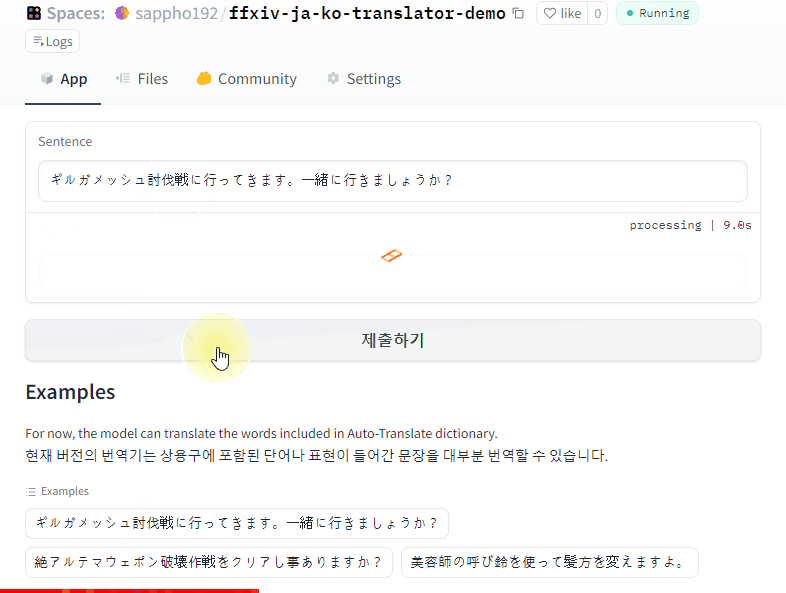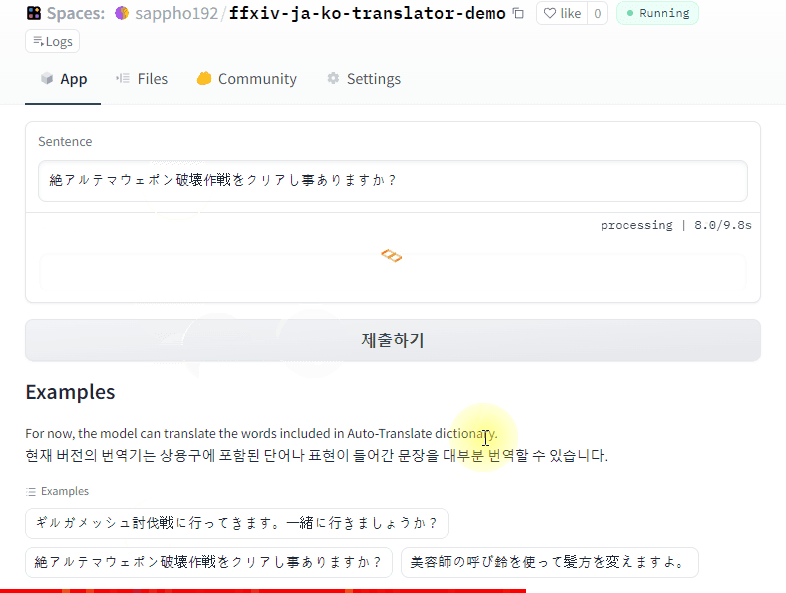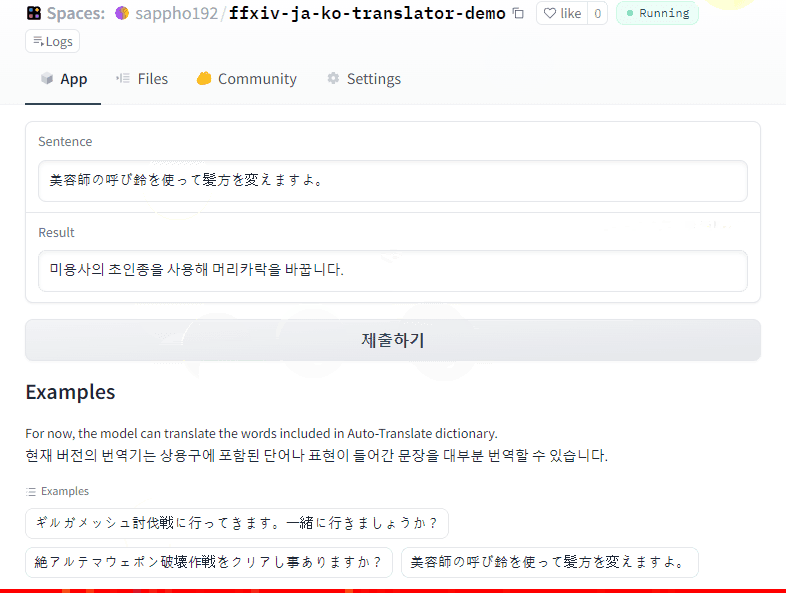 Click to try demo
Click to try demo
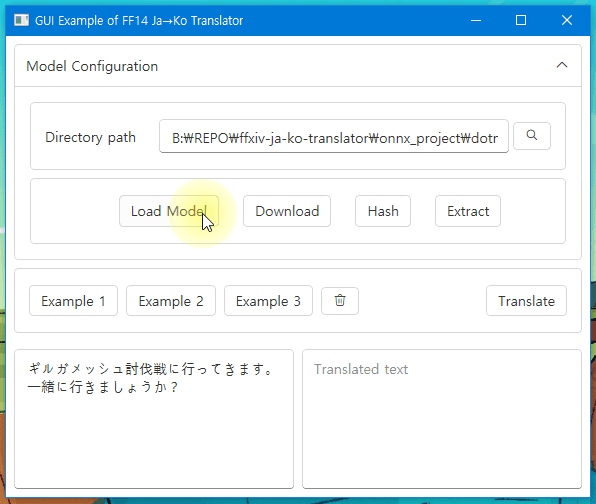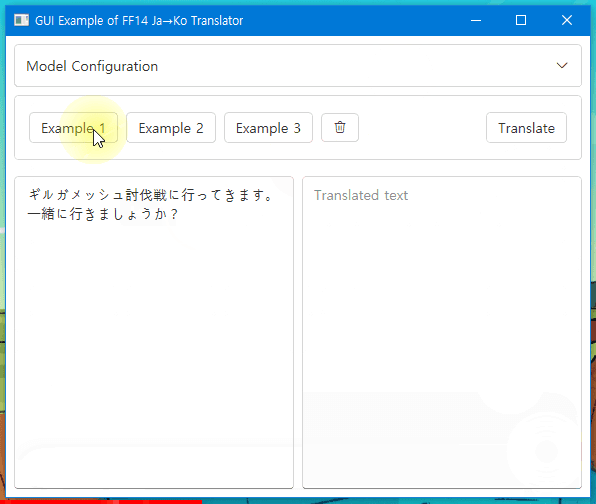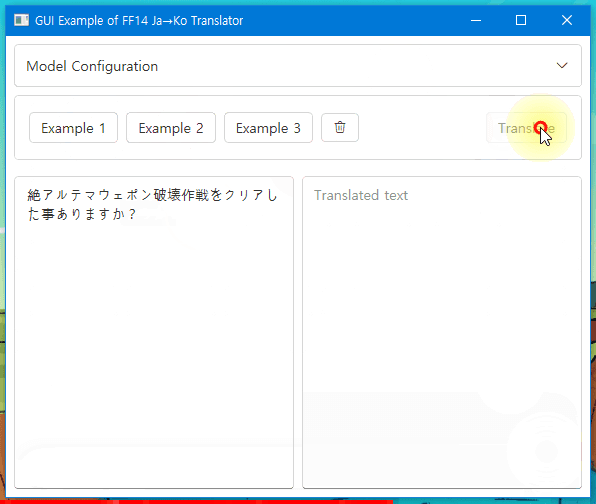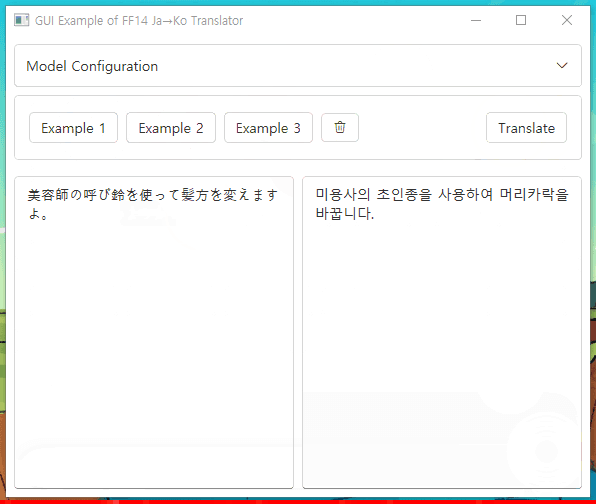 Check this Windows app demo with ONNX model
Check this Windows app demo with ONNX model
Usage
Inference (PyTorch)
from transformers import(
EncoderDecoderModel,
PreTrainedTokenizerFast,
BertJapaneseTokenizer,
)
import torch
encoder_model_name = "cl-tohoku/bert-base-japanese-v2"
decoder_model_name = "skt/kogpt2-base-v2"
src_tokenizer = BertJapaneseTokenizer.from_pretrained(encoder_model_name)
trg_tokenizer = PreTrainedTokenizerFast.from_pretrained(decoder_model_name)
# You should change following `./best_model` to the path of model **directory**
model = EncoderDecoderModel.from_pretrained("./best_model")
text = "ギルガメッシュ討伐戦"
# text = "ギルガメッシュ討伐戦に行ってきます。一緒に行きましょうか?"
def translate(text_src):
embeddings = src_tokenizer(text_src, return_attention_mask=False, return_token_type_ids=False, return_tensors='pt')
embeddings = {k: v for k, v in embeddings.items()}
output = model.generate(**embeddings, max_length=500)[0, 1:-1]
text_trg = trg_tokenizer.decode(output.cpu())
return text_trg
print(translate(text))
Inference (Optimum.OnnxRuntime)
Note that current Optimum.OnnxRuntime still requires PyTorch for backend. [Issue] You can use either [ONNX] or [quantized ONNX] model.
from transformers import BertJapaneseTokenizer,PreTrainedTokenizerFast
from optimum.onnxruntime import ORTModelForSeq2SeqLM
from onnxruntime import SessionOptions
import torch
encoder_model_name = "cl-tohoku/bert-base-japanese-v2"
decoder_model_name = "skt/kogpt2-base-v2"
src_tokenizer = BertJapaneseTokenizer.from_pretrained(encoder_model_name)
trg_tokenizer = PreTrainedTokenizerFast.from_pretrained(decoder_model_name)
sess_options = SessionOptions()
sess_options.log_severity_level = 3 # mute warnings including CleanUnusedInitializersAndNodeArgs
# change subfolder to "onnxq" if you want to use the quantized model
model = ORTModelForSeq2SeqLM.from_pretrained("sappho192/ffxiv-ja-ko-translator",
sess_options=sess_options, subfolder="onnx")
texts = [
"逃げろ!", # Should be "도망쳐!"
"初めまして.", # "반가워요"
"よろしくお願いします.", # "잘 부탁드립니다."
"ギルガメッシュ討伐戦", # "길가메쉬 토벌전"
"ギルガメッシュ討伐戦に行ってきます。一緒に行きましょうか?", # "길가메쉬 토벌전에 갑니다. 같이 가실래요?"
"夜になりました", # "밤이 되었습니다"
"ご飯を食べましょう." # "음, 이제 식사도 해볼까요"
]
def translate(text_src):
embeddings = src_tokenizer(text_src, return_attention_mask=False, return_token_type_ids=False, return_tensors='pt')
print(f'Src tokens: {embeddings.data["input_ids"]}')
embeddings = {k: v for k, v in embeddings.items()}
output = model.generate(**embeddings, max_length=500)[0, 1:-1]
print(f'Trg tokens: {output}')
text_trg = trg_tokenizer.decode(output.cpu())
return text_trg
for text in texts:
print(translate(text))
print()
Training
Check the training.ipynb.
- Downloads last month
- 10
Inference Providers
NEW
This model isn't deployed by any Inference Provider.
🙋
Ask for provider support
HF Inference deployability: The model authors have turned it off explicitly.