
Model overview
Mutual Implication Score is a symmetric measure of text semantic similarity based on a RoBERTA model pretrained for natural language inference and fine-tuned on a paraphrase detection dataset.
The code for inference and evaluation of the model is available here.
This measure is particularly useful for paraphrase detection, but can also be applied to other semantic similarity tasks, such as content similarity scoring in text style transfer.
How to use
The following snippet illustrates code usage:
!pip install mutual-implication-score
from mutual_implication_score import MIS
mis = MIS(device='cpu')#cuda:0 for using cuda with certain index
source_texts = ['I want to leave this room',
'Hello world, my name is Nick']
paraphrases = ['I want to go out of this room',
'Hello world, my surname is Petrov']
scores = mis.compute(source_texts, paraphrases)
print(scores)
# expected output: [0.9748, 0.0545]
Model details
We slightly modify the RoBERTa-Large NLI model architecture (see the scheme below) and fine-tune it with QQP paraphrase dataset.
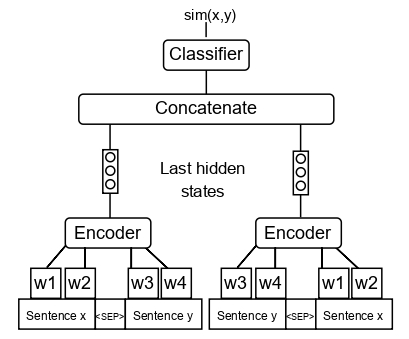
Performance on Text Style Transfer and Paraphrase Detection tasks
This measure was developed in terms of large scale comparison of different measures on text style transfer and paraphrase datasets.
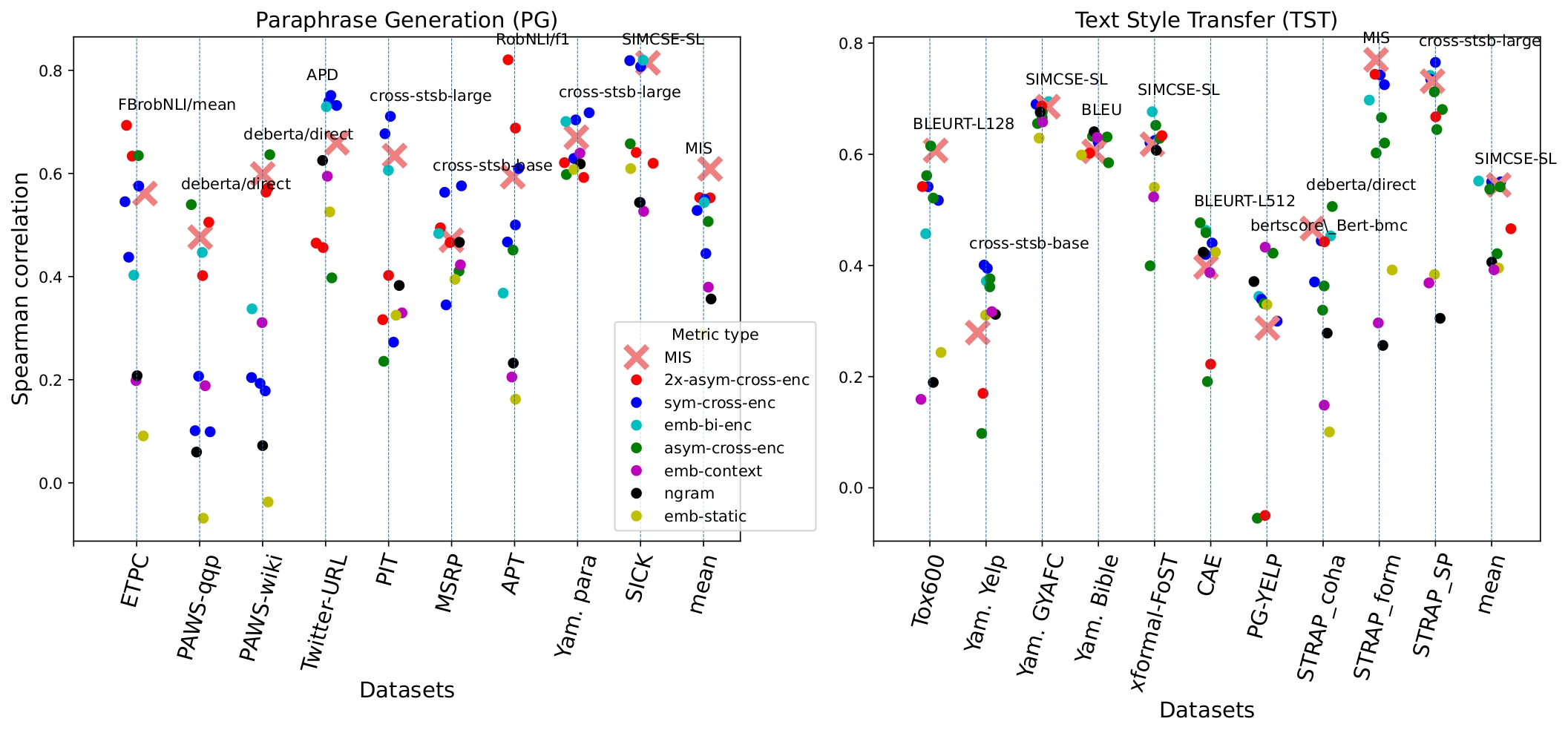
The scheme above shows the correlations of measures of different classes with human judgments on paraphrase and text style transfer datasets. The text above each dataset indicates the best-performing measure. The rightmost columns show the mean performance of measures across the datasets.
MIS outperforms all measures on the paraphrase detection task and performs on par with top measures on the text style transfer task.
To learn more, refer to our article: A large-scale computational study of content preservation measures for text style transfer and paraphrase generation
Citations
If you find this repository helpful, feel free to cite our publication:
@inproceedings{babakov-etal-2022-large,
title = "A large-scale computational study of content preservation measures for text style transfer and paraphrase generation",
author = "Babakov, Nikolay and
Dale, David and
Logacheva, Varvara and
Panchenko, Alexander",
booktitle = "Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics: Student Research Workshop",
month = may,
year = "2022",
address = "Dublin, Ireland",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2022.acl-srw.23",
pages = "300--321",
abstract = "Text style transfer and paraphrasing of texts are actively growing areas of NLP, dozens of methods for solving these tasks have been recently introduced. In both tasks, the system is supposed to generate a text which should be semantically similar to the input text. Therefore, these tasks are dependent on methods of measuring textual semantic similarity. However, it is still unclear which measures are the best to automatically evaluate content preservation between original and generated text. According to our observations, many researchers still use BLEU-like measures, while there exist more advanced measures including neural-based that significantly outperform classic approaches. The current problem is the lack of a thorough evaluation of the available measures. We close this gap by conducting a large-scale computational study by comparing 57 measures based on different principles on 19 annotated datasets. We show that measures based on cross-encoder models outperform alternative approaches in almost all cases.We also introduce the Mutual Implication Score (MIS), a measure that uses the idea of paraphrasing as a bidirectional entailment and outperforms all other measures on the paraphrase detection task and performs on par with the best measures in the text style transfer task.",
}
Licensing Information
Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License.

- Downloads last month
- 557