
Model Card for llama3-8B-360Zhinao-360k-Instruct
llama3-8B-360Zhinao-360k-Instruct is 360Zhinao's extension of llama3-8B-Instruct to a 360k context window [GitHub].
Within the 360k-token length, llama3-8B-360Zhinao-360k-Instruct achieves:
100% perfect recall on the "value retrieval" variant of NIAH (Needle-In-A-Haystack), which requires the model to retrieve the number in the inserted needle "The special magic {random city} number is {random 7-digit number}".
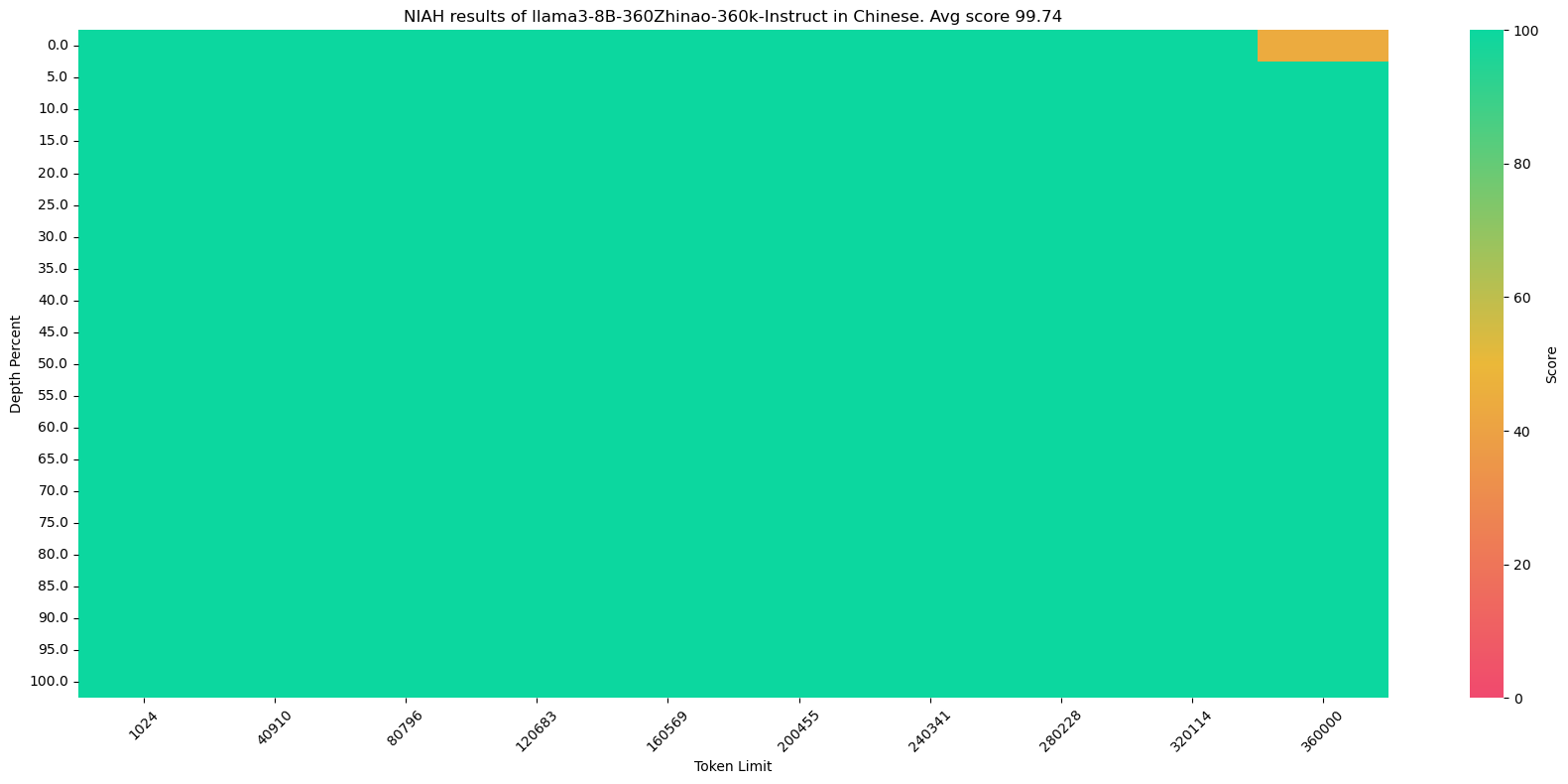
99.75% near-perfect recall on the original NIAH and its corresponding Chinese counterpart, where the needle (e.g. The best thing to do in San Francisco is...) and haystack (e.g. Paul Graham's essays which inevitably talk about San Francisco) are more relevant, hence a more difficult task. Other models with 100% recall on value retrieval could struggle with this NIAH version.
360k-NIAH (Needle-In-A-Haystack) results
"value retrieval" variant of NIAH

Original NIAH

Chinese NIAH
Remarks
We found that the "value retrieval" variant of NIAH (widely used recently in e.g. Gemini, LWM and gradient.ai) is relatively easy.
100% all-green results on value retrieval doesn't necessarily mean near-perfect results on more difficult NIAH tasks, as demonstrated by this original-version NIAH result of one open-sourced llama3-8B-262k model:
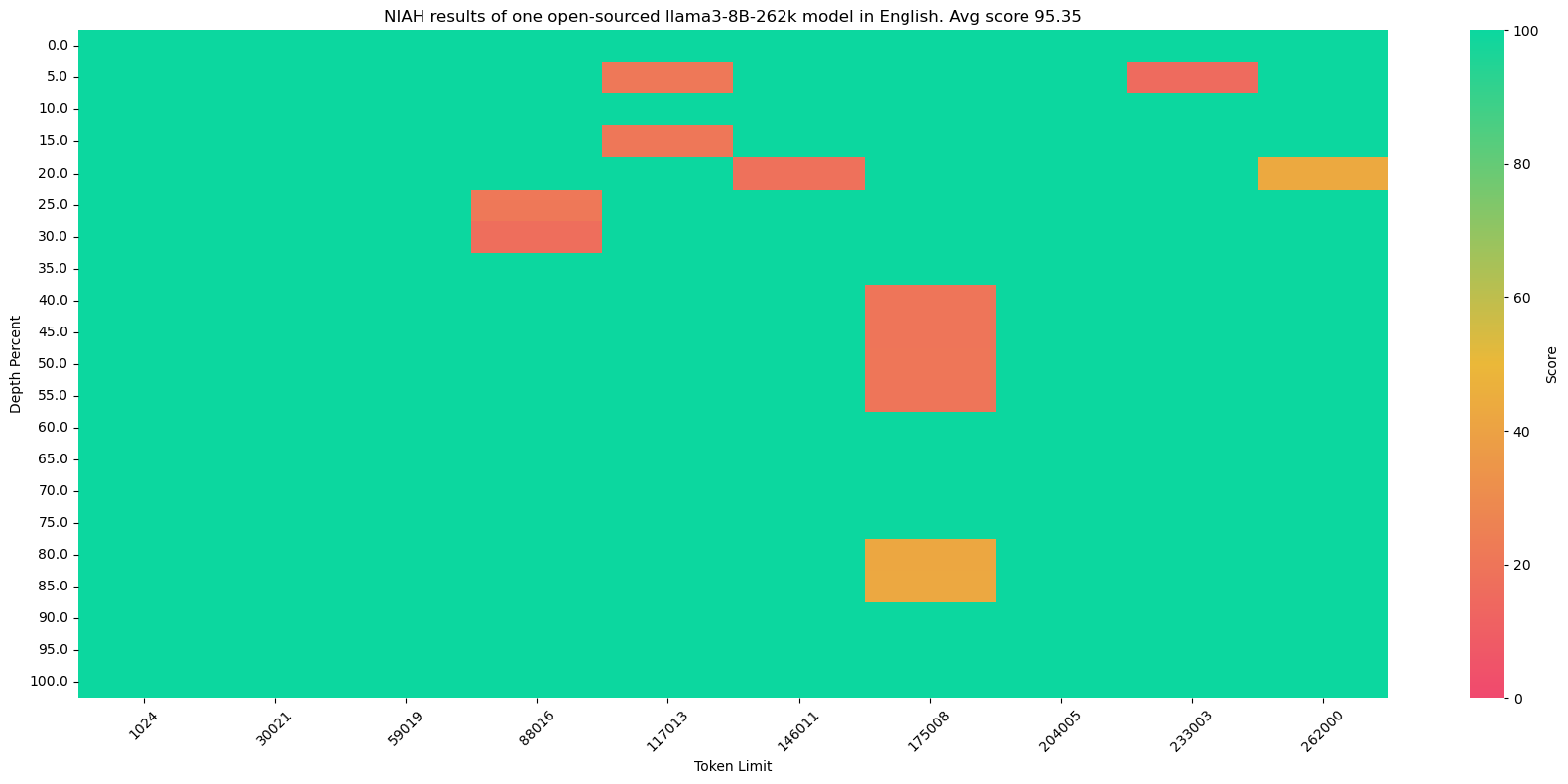
This model does achieve 100% all-green results on value retrieval but less than satisfactory results on the original version.
Reproduce
360k/niah generates the raw results.
The score for value retrieval NIAH is calculated on-the-fly when generating the raw results, while the actual score of original and Chinese NIAH is calculated in 360k/plot.
For the original version, 100% score is given if the regular expression sandwich.+?dolores.+?sunny matches the model output, and edit distance otherwise.
For the Chinese version, 100% score is given if 刘秀 is present in the model output, and edit distance otherwise. For the English-biased llama3 models this may not be perfect.
Usage
llama3-8B-360Zhinao-360k-Instruct could be launched with vllm. To perform inference on 360k-token inputs, we used a 8 x 80G machine (A800).
model_path=${1}
export ENV_PORT=7083
export ENV_TP=8
export ENV_MODEL_PATH=$model_path
echo ${ENV_MODEL_PATH}
export ENV_MAX_MODEL_LEN=365000
export ENV_MAX_BATCH_TOKENS=365000
export ENV_GPU_MEMORY_UTIL=0.6
export PYTORCH_CUDA_ALLOC_CONF=max_split_size_mb:256
python -m vllm.entrypoints.openai.api_server \
--model "${ENV_MODEL_PATH:-/workspace/model}" \
--tensor-parallel-size "${ENV_TP:-2}" \
--trust-remote-code \
--port "${ENV_PORT:-8002}" \
--gpu-memory-utilization "${ENV_GPU_MEMORY_UTIL:-0.92}" \
--max-num-batched-tokens "${ENV_MAX_BATCH_TOKENS:-18000}" \
--max-model-len "${ENV_MAX_MODEL_LEN:-4096}" \
--max-num-seqs "${ENV_MAX_NUM_SEQS:-32}" \
--enforce-eager \
> log8.server 2>&1
Methods
llama3-8B-360Zhinao-360k-Instruct is trained from llama3-8B-Instruct. Its original context-length is 8k with RoPE base 500,000.
We directly extended its context length to 360k. We changed RoPE base to 500,000,000 and trained on a combined SFT dataset of LWM's open-sourced data and internal long-context data in Chinese and English. We implemented SFT on top of EasyContext (code with simple derivation on loss reduction), but later found that turning on pretraining loss produced much better results. SFT is likely suitable for further finetuning within the already extended context window.
We have been using Megatron-LM for several months with tailored optimization on GPU memory. Its context parallelism wasn’t quite ready back then and we have now switched to ring attention implementations such as EasyContext.
Contact & License
Email: g-zhinao-opensource@360.cn
The source code of this repository follows the open-source license Apache 2.0. This project is built on other open-source projects, including llama3, LWM and EasyContext, whose original licenses should also be followed by users.
- Downloads last month
- 22