
French Medium Whisper
This model is a fine-tuned version of openai/whisper-medium on the common_voice_11_0 dataset. It achieves the following results on the evaluation set:
- Loss: 0.2664
- Wer (without normalization): 15.8969
- Wer (with normalization): 11.1406
Blog post
All information about this model in this blog post: Speech-to-Text & IA | Transcreva qualquer áudio para o português com o Whisper (OpenAI)... sem nenhum custo!.
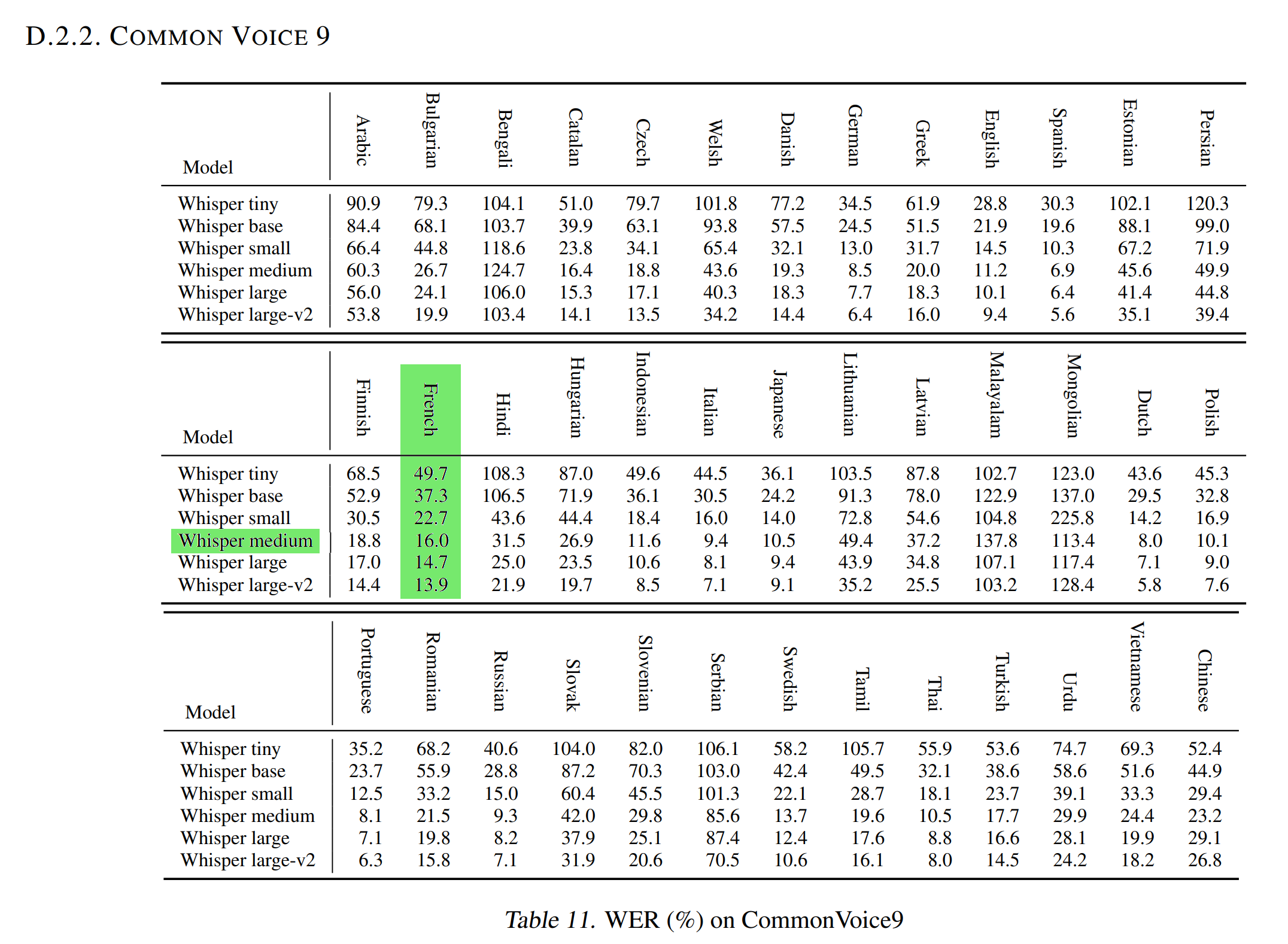
New SOTA
The Normalized WER in the OpenAI Whisper article with the Common Voice 9.0 test dataset is 16.0.
As this test dataset is similar to the Common Voice 11.0 test dataset used to evaluate our model (WER and WER Norm), it means that our French Medium Whisper is better than the Medium Whisper model at transcribing audios French in text.
Training procedure
Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 32
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- training_steps: 5000
- mixed_precision_training: Native AMP
Training results
| Training Loss | Epoch | Step | Validation Loss | Wer | Wer Norm |
|---|---|---|---|---|---|
| 0.2695 | 0.2 | 1000 | 0.3080 | 17.8083 | 12.9791 |
| 0.2099 | 0.4 | 2000 | 0.2981 | 17.4792 | 12.4242 |
| 0.1978 | 0.6 | 3000 | 0.2864 | 16.7767 | 12.0913 |
| 0.1455 | 0.8 | 4000 | 0.2752 | 16.4597 | 11.8966 |
| 0.1712 | 1.0 | 5000 | 0.2664 | 15.8969 | 11.1406 |
Framework versions
- Transformers 4.26.0.dev0
- Pytorch 1.13.0+cu117
- Datasets 2.7.1.dev0
- Tokenizers 0.13.2
- Downloads last month
- 42
Inference Providers
NEW
This model is not currently available via any of the supported third-party Inference Providers, and
the model is not deployed on the HF Inference API.
Dataset used to train pierreguillou/whisper-medium-french
Spaces using pierreguillou/whisper-medium-french 4
Evaluation results
- Wer on mozilla-foundation/common_voice_11_0test set self-reported11.141
- Wer (without normalization) on mozilla-foundation/common_voice_11_0test set self-reported15.897