
NVIDIA NEST Large En
|
The NEST framework is designed for speech self-supervised learning, which can be used as a frozen speech feature extractor or as weight initialization for downstream speech processing tasks. The NEST-L model has about 115M parameters and is trained on an English dataset of roughly 100K hours.
This model is ready for commercial/non-commercial use.
License
License to use this model is covered by the CC-BY-4.0. By downloading the public and release version of the model, you accept the terms and conditions of the CC-BY-4.0 license.
Reference
[1] NEST: Self-supervised Fast Conformer as All-purpose Seasoning to Speech Processing Tasks
[2] NVIDIA NeMo Framework
[3] Stateful Conformer with Cache-based Inference for Streaming Automatic Speech Recognition
[4] Less is More: Accurate Speech Recognition & Translation without Web-Scale Data
[5] Sortformer: Seamless Integration of Speaker Diarization and ASR by Bridging Timestamps and Tokens
[6] Leveraging Pretrained ASR Encoders for Effective and Efficient End-to-End Speech Intent Classification and Slot Filling
Model Architecture
The NEST framework comprises several building blocks, as illustrated in the left part of the following figure. Once trained, the NEST encoder can be used as weight initialization or feature extractor for downstream speech processing tasks.
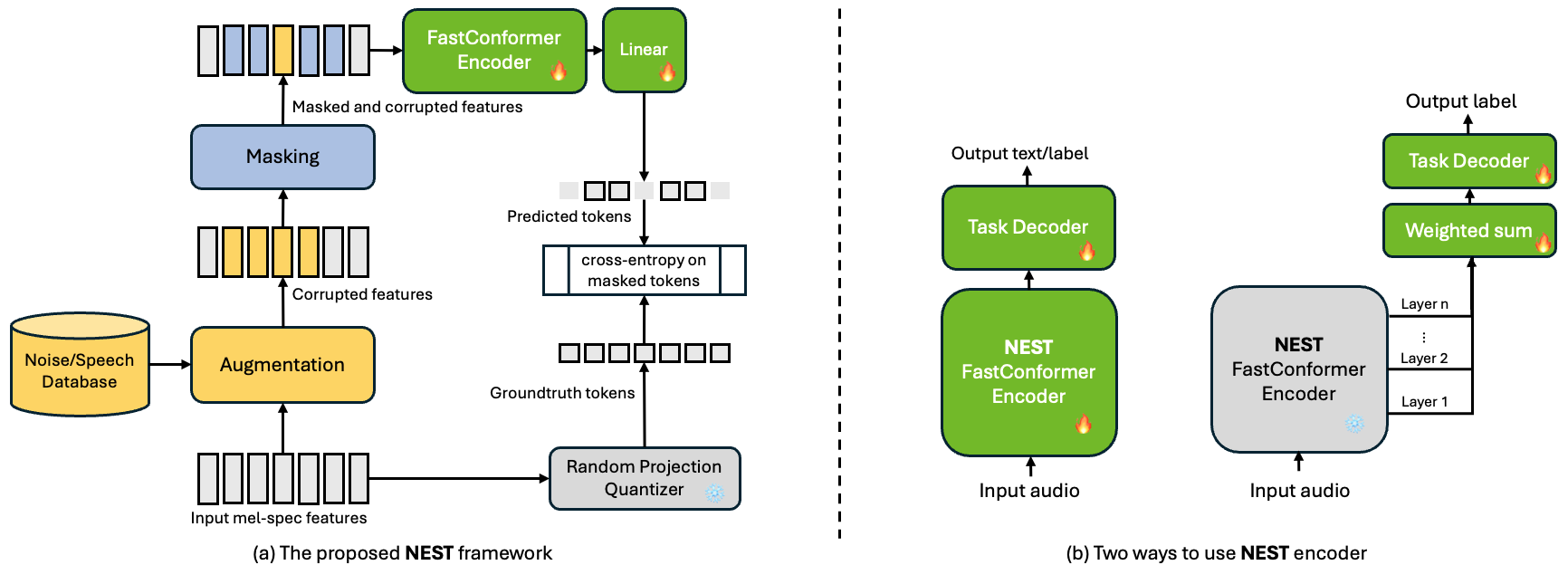
Architecture Details:
- Encoder: FastConformer (18 layers)
- Decoder: Linear classifier
- Masking: Random block masking
- Augmentor: Speaker/noise augmentation
- Loss: Cross-entropy on masked positions
Input
Input Type(s): Audio
Input Format(s): wav files
Input Parameters: One-Dimensional (1D)
Other Properties Related to Input: 16000 Hz Mono-channel Audio
Output
Output Type(s): Audio features
Output Format: Audio embeddings
Output Parameters: Feature sequence (2D)
Other Properties Related to Output: Audio feature sequence of shape [D,T]
Model Version(s)
ssl_en_nest_large_v1.0
How to Use the Model
The model is available for use in the NVIDIA NeMo Framework [2], and can be used as weight initialization for downstream tasks or as a frozen feature extractor.
Automatically Instantiate the Model
from nemo.collections.asr.models import EncDecDenoiseMaskedTokenPredModel
nest_model = EncDecDenoiseMaskedTokenPredModel.from_pretrained(model_name="nvidia/ssl_en_nest_large_v1.0")
Using NEST as Weight Initialization for Downstream Tasks
# use ASR as example:
python <NeMo Root>/examples/asr/asr_ctc/speech_to_text_ctc_bpe.py \
# (Optional: --config-path=<path to dir of configs> --config-name=<name of config without .yaml>) \
++init_from_pretrained.name="nvidia/ssl_en_nest_large_v1.0" \
++init_from_pretrained.include=["encoder"] \
model.train_ds.manifest_filepath=<path to train manifest> \
model.validation_ds.manifest_filepath=<path to val/test manifest> \
model.tokenizer.dir=<path to directory of tokenizer (not full path to the vocab file!)> \
model.tokenizer.type=<either bpe or wpe> \
trainer.devices=-1 \
trainer.accelerator="gpu" \
trainer.strategy="ddp" \
trainer.max_epochs=100 \
model.optim.name="adamw" \
model.optim.lr=0.001 \
model.optim.betas=[0.9,0.999] \
model.optim.weight_decay=0.0001 \
model.optim.sched.warmup_steps=2000
exp_manager.create_wandb_logger=True \
exp_manager.wandb_logger_kwargs.name="<Name of experiment>" \
exp_manager.wandb_logger_kwargs.project="<Name of project>"
More details can be found at maybe_init_from_pretrained_checkpoint().
Using NEST as Frozen Feature Extractor
NEST can also be used as a frozen feature extractor for downstream tasks. For example, in the case of speaker verification, embeddings can be extracted from different layers of the NEST model, and a learned weighted combination of those embeddings can be used as input to the speaker verification model. Please refer to this example script and config for details.
Extracting and Saving Audio Features from NEST
NEST supports extracting audio features from multiple layers of its encoder:
python <NeMo Root>/scripts/ssl/extract_features.py \
--model_path="nvidia/ssl_en_nest_large_v1.0" \
--input=<path to input manifest, or a dir containing audios, or path to audio> \
--output=<output directory to store features and manifest> \
--layers="all" \
--batch_size=8 \
--workers=8
Training
The NVIDIA NeMo Framework [2] was used for training the model. Model is trained with this example script and config.
Training Datasets
- LibriLight
- Data Collection Method: Human
- Labeling Method: Human
- Voxpopuli
- Data Collection Method: Human
- Labeling Method: Human
- NeMo ASR Set 3.0
- Data Collection Method: Hybrid: Automated, Human
- Labeling Method: Hybrid: Automated, Human
Inference
Engine: NVIDIA NeMo
Test Hardware:
- A6000
- A100
Performance
For performance on more tasks, please refer to the NEST paper [1].
Multi-lingual Speech Recognition (ASR) with Punctuation and Capitalization
We finetuned the NEST model on 14k hours of multilingual (En, De, Es, FR) ASR data using the hybrid-CTC-RNNT loss [3] and evaluate the model's word error rate (WER) with punctuation and capitalization on the MCV16.1 test set. Please refer to the NEST paper [1] for more results and details on the model and training setup.
| Model | En-MCV16.1-test | De-MCV16.1-test | Es-MCV16.1-test | Fr-MCV16.1-test |
|---|---|---|---|---|
| ssl_en_nest_xlarge | 14.43 | 8.07 | 8.70 | 16.18 |
Speech-to-text Translation (AST)
We use the stt_en_nest_xlarge model to initialize the Canary [4] model for speech-to-text translation. We evaluate the model's BLEU score on FLEURS test sets. Please refer to the NEST paper [1] for more results and details on the model and training setup.
| Model | En->De | En->Es | En->Fr |
|---|---|---|---|
| ssl_en_nest_xlarge | 29.50 | 22.61 | 39.27 |
Speaker Diarization (SD)
We use the ssl_en_nest_large_v1.0 model to initialize the Sortformer [5] model for speaker diarization. We evaluate the model's diarization error rate (DER) on the DIHARD and CALLHOME-part2 test sets. Please refer to the Sortformer paper [5] for more results and details on the model and training setup.
| Model | DIHARD | CALLHOME-part2 | CALLHOME-part2 | CALLHOME-part2 |
|---|---|---|---|---|
| [speakers] | <= 4 | 2 | 3 | 4 |
| [collar] | collar=0.0 | collar=0.25 | collar=0.25 | collar=0.25 |
| Sortformer w/ NEST | 14.60 | 6.08 | 9.57 | 15.40 |
Speech Intent Classification and Slot Filling (SLU)
We use the ssl_en_nest_large_v1.0 model to initialize the SLU model for speech intent classification and slot filling. We evaluate the model's intent classification accuracy and SLURP F1 score on the SLURP test set. Please refer to the NEST paper [1] for more results and details on the model and training setup.
| Model | Intent Acc | SLURP F1 |
|---|---|---|
| ssl_en_nest_large_v1.0 | 89.79 | 79.61 |
| ssl_en_nest_xlarge_v1.0 | 89.04 | 80.31 |
Software Integration
Runtime Engine(s):
- [NeMo-2.0]
Supported Hardware Microarchitecture Compatibility:
- [NVIDIA Ampere]
- [NVIDIA Blackwell]
- [NVIDIA Jetson]
- [NVIDIA Hopper]
- [NVIDIA Lovelace]
- [NVIDIA Pascal]
- [NVIDIA Turing]
- [NVIDIA Volta]
Supported Operating System(s):
- [Linux]
- [Windows]
Ethical Considerations
NVIDIA believes Trustworthy AI is a shared responsibility and we have established policies and practices to enable development for a wide array of AI applications. When downloaded or used in accordance with our terms of service, developers should work with their internal model team to ensure this model meets requirements for the relevant industry and use case and addresses unforeseen product misuse.
For more detailed information on ethical considerations for this model, please see the Model Card++ Explainability, Bias, Safety & Security, and Privacy Subcards [Insert Link to Model Card++ here].
Please report security vulnerabilities or NVIDIA AI Concerns here.
Bias
| Field | Response |
|---|---|
| Participation considerations from adversely impacted groups protected classes in model design and testing: | None |
| Measures taken to mitigate against unwanted bias: | None |
Explainability
| Field | Response |
|---|---|
| Intended Application & Domain: | Model initialization or feature extractor for downstream speech processing tasks |
| Model Type: | Transformer |
| Intended Users: | Researchers and Developers in speech processing |
| Output: | Audio embeddings |
| Describe how the model works: | Speech signal is processed by the model to produce audio embeddings |
| Name the adversely impacted groups this has been tested to deliver comparable outcomes regardless of: | Not Applicable |
| Technical Limitations: | This model was trained on English speech data and may not generalize well to other languages. Although the model was trained with various audio lengths from 1 second to 64 seconds, it may not perform well in streaming situations. |
Verified to have met prescribed NVIDIA quality standards: | Yes Performance Metrics: | Accuracy, F1, WER, DER Potential Known Risks: | Speech features might not be effective for unseen languages and non-speech signals Licensing: | CC-BY-4.0
Privacy
| Field | Response |
|---|---|
| Generatable or reverse engineerable personal data? | None |
| Personal data used to create this model? | None |
| Was consent obtained for any personal data used? | Not Applicable |
| How often is dataset reviewed? | Before Release |
| Is a mechanism in place to honor data subject right of access or deletion of personal data? | Not Applicable |
| If personal data was collected for the development of the model, was it collected directly by NVIDIA? | Not Applicable |
| If personal data was collected for the development of the model by NVIDIA, do you maintain or have access to disclosures made to data subjects? | Not Applicable |
| If personal data was collected for the development of this AI model, was it minimized to only what was required? | Not Applicable |
| Is there provenance for all datasets used in training? | Yes |
| Does data labeling (annotation, metadata) comply with privacy laws? | Yes |
| Is data compliant with data subject requests for data correction or removal, if such a request was made? | No, not possible with externally-sourced data. |
Safety
| Field | Response |
|---|---|
| Model Application(s): | Model initialization or feature extractor for downstream speech processing tasks |
| Describe the life critical impact (if present). | Not Applicable |
| Use Case Restrictions: | Abide by CC-BY-4.0 |
| Model and dataset restrictions: | The Principle of least privilege (PoLP) is applied limiting access for dataset generation and model development. Restrictions enforce dataset access during training, and dataset license constraints adhered to. |
Bias
| Field | Response |
|---|---|
| Participation considerations from adversely impacted groups protected classes in model design and testing: | None |
| Measures taken to mitigate against unwanted bias: | None |
Explainability
| Field | Response |
|---|---|
| Intended Application & Domain: | Model initialization or feature extractor for downstream speech processing tasks |
| Model Type: | Transformer |
| Intended Users: | Researchers and Developers in speech processing |
| Output: | Audio embeddings |
| Describe how the model works: | Speech signal is processed by the model to produce audio embeddings |
| Name the adversely impacted groups this has been tested to deliver comparable outcomes regardless of: | Not Applicable |
| Technical Limitations: | None |
| Verified to have met prescribed NVIDIA quality standards: | Yes |
| Performance Metrics: | N/A |
| Potential Known Risks: | None Known |
| Licensing: | CC-BY-4.0 |
Privacy
| Field | Response |
|---|---|
| Generatable or reverse engineerable personal data? | No |
| Personal data used to create this model? | No |
| Was consent obtained for any personal data used? | Not Applicable |
| How often is dataset reviewed? | Before Release |
| Is a mechanism in place to honor data subject right of access or deletion of personal data? | Not Applicable |
| If personal data was collected for the development of the model, was it collected directly by NVIDIA? | Not Applicable |
| If personal data was collected for the development of the model by NVIDIA, do you maintain or have access to disclosures made to data subjects? | Not Applicable |
| If personal data was collected for the development of this AI model, was it minimized to only what was required? | Not Applicable |
| Is there provenance for all datasets used in training? | Yes |
| Does data labeling (annotation, metadata) comply with privacy laws? | Yes |
| Is data compliant with data subject requests for data correction or removal, if such a request was made? | No, not possible with externally-sourced data. |
Safety
| Field | Response |
|---|---|
| Model Application(s): | Model initialization or feature extractor for downstream speech processing tasks |
| Describe the life critical impact (if present). | Not Applicable |
| Use Case Restrictions: | Model for commercial and non-commercial use |
| Model and dataset restrictions: | The Principle of least privilege (PoLP) is applied limiting access for dataset generation and model development. Restrictions enforce dataset access during training, and dataset license constraints adhered to. |